Declaration officielle
Autres déclarations de cette vidéo 7 ▾
- □ Les liens internes sont-ils vraiment traités comme des signaux UX par Googlebot ?
- □ Pourquoi l'élément HTML <a> avec attribut href est-il indispensable au crawl Google ?
- □ Pourquoi Google insiste-t-il pour que les liens restent de vrais liens HTML ?
- □ Le texte d'ancrage significatif est-il encore un levier SEO décisif ?
- □ Pourquoi trop de liens internes peuvent-ils nuire à votre SEO ?
- □ Comment trouver le bon équilibre dans la quantité de liens internes ?
- □ Pourquoi Google insiste-t-il encore sur l'importance des liens internes pour la navigation et la découverte de contenu ?
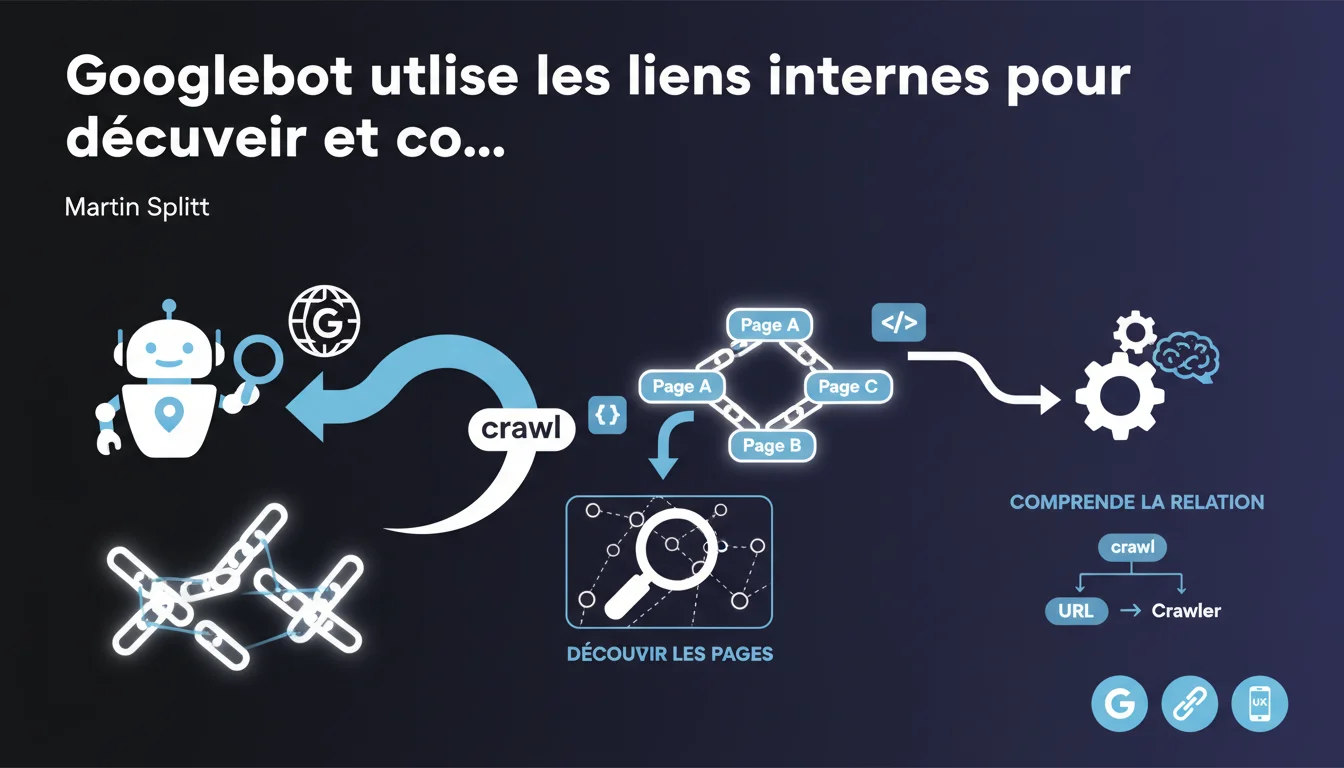
Googlebot utilise les liens internes pour deux fonctions précises : découvrir les pages de votre site et comprendre leurs relations hiérarchiques. Sans liens internes, une URL peut rester invisible pour Google même si elle existe techniquement sur votre domaine.
Ce qu'il faut comprendre
Pourquoi les liens internes sont-ils critiques pour le crawl ?
Googlebot ne devine pas l'arborescence de votre site. Il suit les liens hypertextes pour passer d'une page à l'autre, exactement comme un utilisateur. Une page orpheline — sans aucun lien interne pointant vers elle — peut échapper totalement au crawl.
Martin Splitt précise que cette logique sert aussi à comprendre la relation entre les pages. Le moteur déduit la hiérarchie, l'importance relative, et parfois même le contexte thématique d'une URL selon les liens qui y mènent et leur ancrage.
Comment Googlebot décide-t-il quelles URLs crawler ?
Quand le bot trouve une URL dans vos pages, il peut essayer de la crawler — aucune garantie. La formulation "peut essayer" trahit les contraintes de crawl budget : Google ne promet pas de visiter systématiquement chaque URL découverte.
Le crawl budget dépend de l'autorité du domaine, de la fraîcheur des contenus, et de la qualité perçue du site. Un lien interne ne suffit donc pas à déclencher un crawl immédiat si le site est jugé peu prioritaire.
Quels types de liens internes compte vraiment Google ?
La déclaration reste volontairement floue sur ce point. On sait que les liens HTML classiques sont pris en compte. Les liens JavaScript, si le JS est exécuté et si le bot parvient à rendre la page, peuvent aussi être suivis — mais c'est moins fiable.
Les liens en nofollow interne sont techniquement découverts, mais leur poids est sujet à débat. Google a déclaré que le nofollow est désormais un "indice" plutôt qu'une directive stricte, mais rien n'est tranché.
- Les liens HTML dans le corps ou les menus sont le socle du crawl.
- Les liens JavaScript nécessitent un rendu côté client — risque de latence ou d'échec.
- Les liens en
nofollowpeuvent être suivis, mais leur impact reste opaque. - Les sitemaps XML complètent mais ne remplacent jamais le maillage interne.
Avis d'un expert SEO
Cette déclaration est-elle cohérente avec les observations terrain ?
Oui, pour l'essentiel. Les sites avec un maillage interne robuste voient leurs pages indexées plus rapidement que ceux qui comptent uniquement sur le sitemap. C'est un fait établi depuis des années.
Mais la formulation "peut essayer de crawler" laisse une marge d'interprétation énorme. Concrètement, on observe que Google ignore régulièrement des URLs découvertes si elles paraissent redondantes, de faible qualité, ou si le crawl budget est serré. [À vérifier] : aucune métrique officielle ne permet de prédire si une URL sera effectivement crawlée.
Quelles nuances faut-il apporter pour les gros sites ?
Sur un site de 100 000 pages, le maillage interne peut devenir un casse-tête. Trop de liens diluent le PageRank interne, trop peu créent des pages orphelines. La déclaration de Splitt ne mentionne pas le concept de profondeur de clic — pourtant déterminant.
Une page accessible en 5 clics depuis l'accueil aura moins de chances d'être crawlée qu'une page à 2 clics, même si les deux sont techniquement "découvrables". Et c'est là que ça coince : Google ne donne aucune consigne chiffrée.
Dans quels cas cette règle ne s'applique-t-elle pas pleinement ?
Les sites mono-page (SPA) ou les architectures JavaScript lourdes posent problème. Si Googlebot doit attendre le rendu complet pour découvrir les liens internes, le crawl peut échouer ou être partiel. Soyons honnêtes : l'écart entre ce que Google dit et ce qu'il fait sur les SPA reste énorme.
Autre cas : les sites avec authentification ou contenus dynamiques. Un lien interne visible uniquement après login ne sera jamais suivi par Googlebot. Évident ? Oui. Mais on voit encore des e-commerces qui cachent leurs fiches produits derrière un mur d'inscription.
Impact pratique et recommandations
Que faut-il faire concrètement pour optimiser le maillage interne ?
D'abord, cartographiez votre maillage. Utilisez Screaming Frog, Oncrawl, ou Botify pour identifier les pages orphelines et celles accessibles en trop de clics. L'objectif : aucune page stratégique à plus de 3 clics de l'accueil.
Ensuite, travaillez les ancres de liens internes. Google utilise le texte d'ancrage pour comprendre le sujet de la page cible. Une ancre générique type "cliquez ici" n'apporte rien — préférez des ancres descriptives et riches en mots-clés.
Quelles erreurs éviter absolument ?
Ne multipliez pas les liens depuis le footer ou la sidebar vers des centaines de pages. Google détecte ces patterns et dévalue ces liens. Un lien contextuel dans le corps de texte pèse bien plus lourd qu'un lien noyé dans un mega-menu.
Évitez aussi les boucles de redirection interne ou les chaînes de redirections. Chaque saut supplémentaire consomme du crawl budget et dilue l'équité de lien. Et ne vous fiez pas uniquement au sitemap XML : ce n'est qu'un filet de sécurité, pas la stratégie principale.
Comment vérifier que mon site est conforme ?
Auditez régulièrement avec Google Search Console : regardez les pages "Découvertes, actuellement non indexées" et "Crawlées, actuellement non indexées". Si ces listes explosent, c'est un signal d'alerte.
Testez aussi le rendu JavaScript avec l'outil d'inspection d'URL de la GSC. Vérifiez que les liens internes apparaissent bien dans la version rendue par Google, surtout si vous utilisez React, Vue ou Angular.
- Identifier et corriger toutes les pages orphelines stratégiques
- Réduire la profondeur de clic maximale à 3 depuis l'accueil
- Privilégier les liens contextuels dans le contenu principal
- Utiliser des ancres descriptives riches en mots-clés
- Vérifier le rendu JavaScript avec l'outil d'inspection Google
- Monitorer les statuts "Découvertes non indexées" dans la Search Console
- Supprimer les redirections internes inutiles pour économiser le crawl budget
❓ Questions frequentes
Un sitemap XML peut-il remplacer les liens internes ?
Les liens en JavaScript sont-ils pris en compte par Googlebot ?
Faut-il mettre du nofollow sur les liens internes peu importants ?
Combien de liens internes maximum par page ?
Comment savoir si mes pages orphelines sont un problème ?
🎥 De la même vidéo 7
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 23/07/2024
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.