Declaration officielle
Autres déclarations de cette vidéo 7 ▾
- □ Les liens internes sont-ils vraiment traités comme des signaux UX par Googlebot ?
- □ Googlebot découvre-t-il vraiment vos pages grâce aux liens internes ?
- □ Pourquoi l'élément HTML <a> avec attribut href est-il indispensable au crawl Google ?
- □ Le texte d'ancrage significatif est-il encore un levier SEO décisif ?
- □ Pourquoi trop de liens internes peuvent-ils nuire à votre SEO ?
- □ Comment trouver le bon équilibre dans la quantité de liens internes ?
- □ Pourquoi Google insiste-t-il encore sur l'importance des liens internes pour la navigation et la découverte de contenu ?
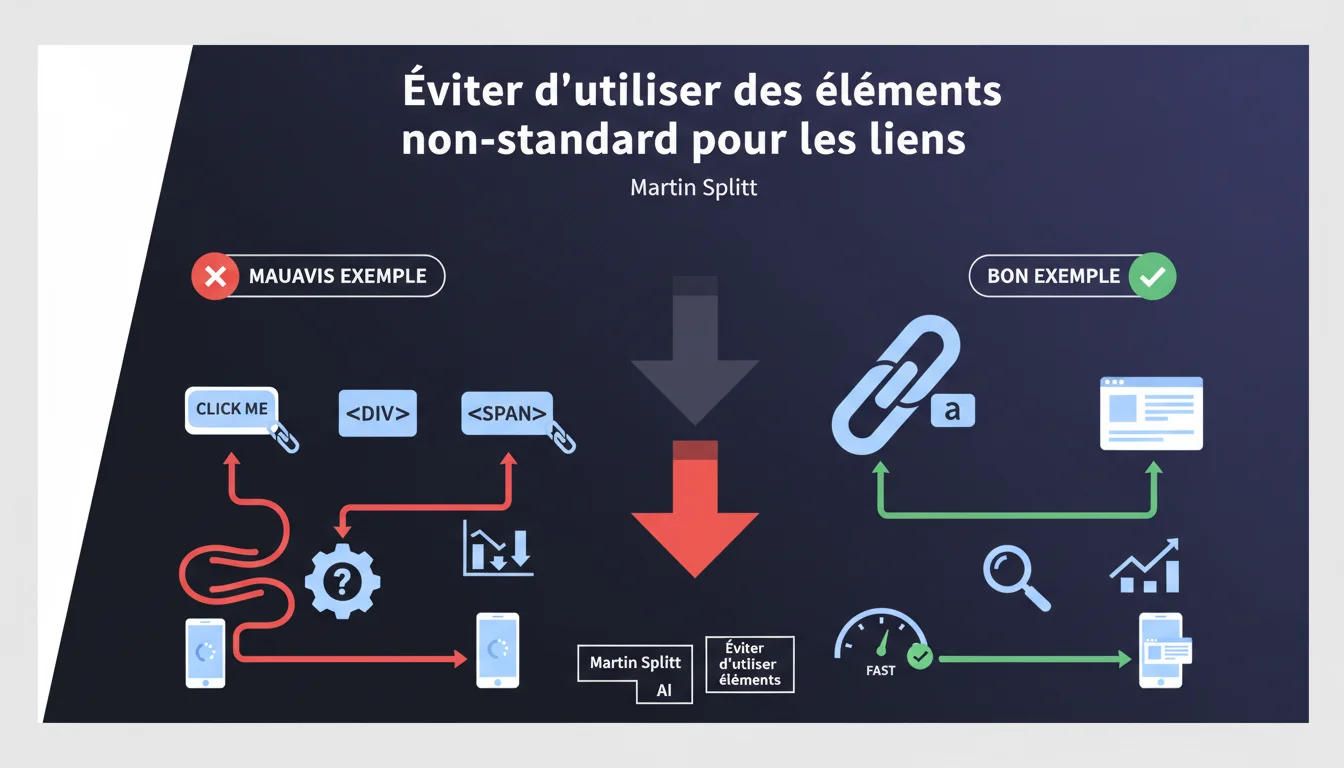
Google demande aux développeurs d'arrêter de bidouiller des faux liens avec des spans, divs ou boutons. Si ça se comporte comme un lien, utilisez une balise <a>. Sinon, Googlebot ne suivra tout simplement pas ces éléments, et vous perdrez du PageRank interne.
Ce qu'il faut comprendre
Pourquoi certains développeurs évitent-ils les balises classiques ?
La raison est souvent purement esthétique ou technique. Les frameworks JavaScript modernes poussent parfois à gérer les interactions via des événements onClick sur des éléments non-standard. Les designers veulent parfois un contrôle total sur le style sans se battre avec les propriétés CSS héritées des liens.
D'autres développeurs pensent gagner en « modernité » en utilisant des boutons stylisés avec du JavaScript pour déclencher la navigation. Le problème ? Googlebot ne va pas exécuter votre JS complexe pour comprendre qu'un div cliquable mène quelque part.
Qu'est-ce que Google considère comme un « lien approprié » ?
Un lien approprié, c'est une balise <a href="..."> avec un attribut href valide. Point final. Pas de onclick sur un span, pas de div déguisé en lien, pas de bouton avec un eventListener sophistiqué.
Googlebot crawle le HTML brut. Si votre « lien » nécessite du JavaScript pour fonctionner, vous prenez le risque que le bot ne le suive pas — ou pire, qu'il le suive mal et gaspille votre crawl budget.
Quelles sont les conséquences réelles d'ignorer ce conseil ?
Première conséquence : perte de découvrabilité. Si Googlebot ne suit pas vos faux liens, les pages cibles ne seront pas crawlées ou seront crawlées moins fréquemment.
Deuxième conséquence : dilution du PageRank interne. Google ne transmet pas de jus SEO via un span ou un div, même s'il est cliquable pour l'utilisateur. Votre maillage interne devient fantôme.
- Les balises <a href> sont le seul standard reconnu pour transmettre l'autorité entre pages
- Les éléments non-standard (span, div, button) ne sont pas crawlés comme des liens, même avec du JS
- Google peut techniquement exécuter du JavaScript, mais ce n'est pas garanti et ça consomme du crawl budget inutilement
- Un lien HTML classique est accessible, performant et universel — trois qualités que Google valorise
Avis d'un expert SEO
Cette déclaration est-elle vraiment nouvelle ou juste un rappel ?
Soyons honnêtes : c'est un rappel de base. Martin Splitt ne découvre rien ici — c'est une règle connue depuis les débuts du web. Mais le fait que Google doive encore le répéter en 2024 montre que le problème persiste, notamment avec les frameworks JS qui encouragent des pratiques non-standard.
Ce qui est intéressant, c'est le ton employé : « si quelque chose se comporte comme un lien, il devrait être un lien ». Google essaie de simplifier le message pour toucher les développeurs qui ne pensent pas SEO. Et c'est là que ça coince.
Dans quels cas cette règle pose-t-elle problème en pratique ?
Il existe des cas limites légitimes. Par exemple, un menu déroulant qui charge du contenu dynamique sans changer d'URL. Ou une application monopage (SPA) où la navigation est gérée par le router JavaScript.
Dans ces cas, utiliser un <a href> classique peut casser l'expérience utilisateur. La solution ? Implémenter une navigation hybride : un href valide pour Googlebot, un eventListener pour enrichir l'UX. C'est faisable, mais ça demande du travail — et beaucoup de devs prennent des raccourcis.
[A vérifier] : Google affirme que Googlebot peut suivre certains liens JavaScript avancés, mais les tests terrain montrent que c'est incohérent selon la complexité du code et le timing d'exécution. Compter là-dessus est un pari risqué.
Quelles nuances faut-il apporter pour les sites e-commerce ou SaaS ?
Sur un site e-commerce, les boutons « Ajouter au panier » n'ont pas besoin d'être des liens — ce sont des actions, pas de la navigation. Pas de confusion ici.
Par contre, les filtres de catégories ou les menus de navigation doivent absolument utiliser des <a href>. J'ai vu trop de sites perdre des milliers de pages de l'index parce que leurs filtres de facettes étaient gérés uniquement en JavaScript, sans fallback HTML.
Impact pratique et recommandations
Que faut-il auditer en priorité sur un site existant ?
Première étape : crawler votre site avec Screaming Frog ou Oncrawl en mode « Googlebot ». Regardez si tous vos liens internes apparaissent bien dans le graphe de crawl. Si des sections entières manquent, vous avez probablement des faux liens.
Deuxième étape : inspectez le HTML source (pas le DOM après exécution JS) sur vos pages clés. Cherchez les onclick, les data-href, les divs avec des classes « link » ou « btn-link ». Si vous en trouvez, remplacez-les par des <a href>.
Comment migrer des faux liens vers des vrais sans casser l'UX ?
Utilisez la technique du progressive enhancement. Créez d'abord un lien HTML classique. Ensuite, ajoutez du JavaScript pour enrichir le comportement (animations, chargement AJAX, etc.).
Exemple concret : remplacez <div onclick="goTo('/page')"> par <a href="/page" class="enhanced-link">. Puis ajoutez un eventListener qui intercepte le clic pour gérer l'UX avancée, mais laisse le href intact pour Googlebot.
Quelles erreurs éviter absolument lors de l'implémentation ?
Erreur n°1 : utiliser href="#" ou href="javascript:void(0)". Ces syntaxes rendent le lien invalide pour Googlebot. Si vous devez intercepter le comportement en JS, utilisez preventDefault(), mais gardez un href valide.
Erreur n°2 : oublier de tester en mode no-JS. Désactivez JavaScript dans Chrome DevTools et naviguez sur votre site. Si certains liens ne fonctionnent plus, vous avez un problème.
- Auditer tous les éléments de navigation avec un crawler configuré comme Googlebot
- Remplacer tous les spans, divs et buttons cliquables par des <a href> valides
- Vérifier que les frameworks JS (React, Vue, Next.js) génèrent bien des balises <a> dans le HTML
- Tester la navigation en mode no-JavaScript pour garantir l'accessibilité Googlebot
- Implémenter un progressive enhancement : href valide + JS optionnel pour l'UX
- Éviter href="#" ou href="javascript:void(0)" qui invalident le lien pour les crawlers
- Monitorer régulièrement le taux de pages découvertes dans la Search Console
❓ Questions frequentes
Est-ce que Google suit les liens générés dynamiquement en JavaScript ?
Un bouton peut-il remplacer un lien pour la navigation interne ?
Comment vérifier que mes liens React ou Vue sont bien crawlables ?
Les liens avec rel='nofollow' sont-ils concernés par cette règle ?
Peut-on utiliser des divs cliquables pour des raisons d'accessibilité ?
🎥 De la même vidéo 7
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 23/07/2024
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.