Official statement
Other statements from this video 11 ▾
- □ Google indexe-t-il vraiment vos PDF ou les transforme-t-il d'abord ?
- □ Le poids du contenu varie-t-il selon son emplacement en HTML et en PDF ?
- □ Google dépend-il vraiment d'Adobe pour indexer vos PDF ?
- □ Pourquoi les fichiers de code source peinent-ils à se classer dans Google ?
- □ Faut-il vraiment arrêter de stocker tous vos PDF dans un dossier /pdfs/ ?
- □ Pourquoi Google n'indexe-t-il jamais une image isolée sans page d'hébergement ?
- □ Google indexe-t-il vraiment les images et vidéos différemment du texte ?
- □ Google filtre-t-il les données personnelles avant indexation ?
- □ L'extension de fichier (.html, .php, .txt) a-t-elle un impact sur le référencement Google ?
- □ Google indexe-t-il vraiment tous vos fichiers XML ?
- □ Peut-on vraiment indexer des fichiers JSON et texte brut sans méta-données ?
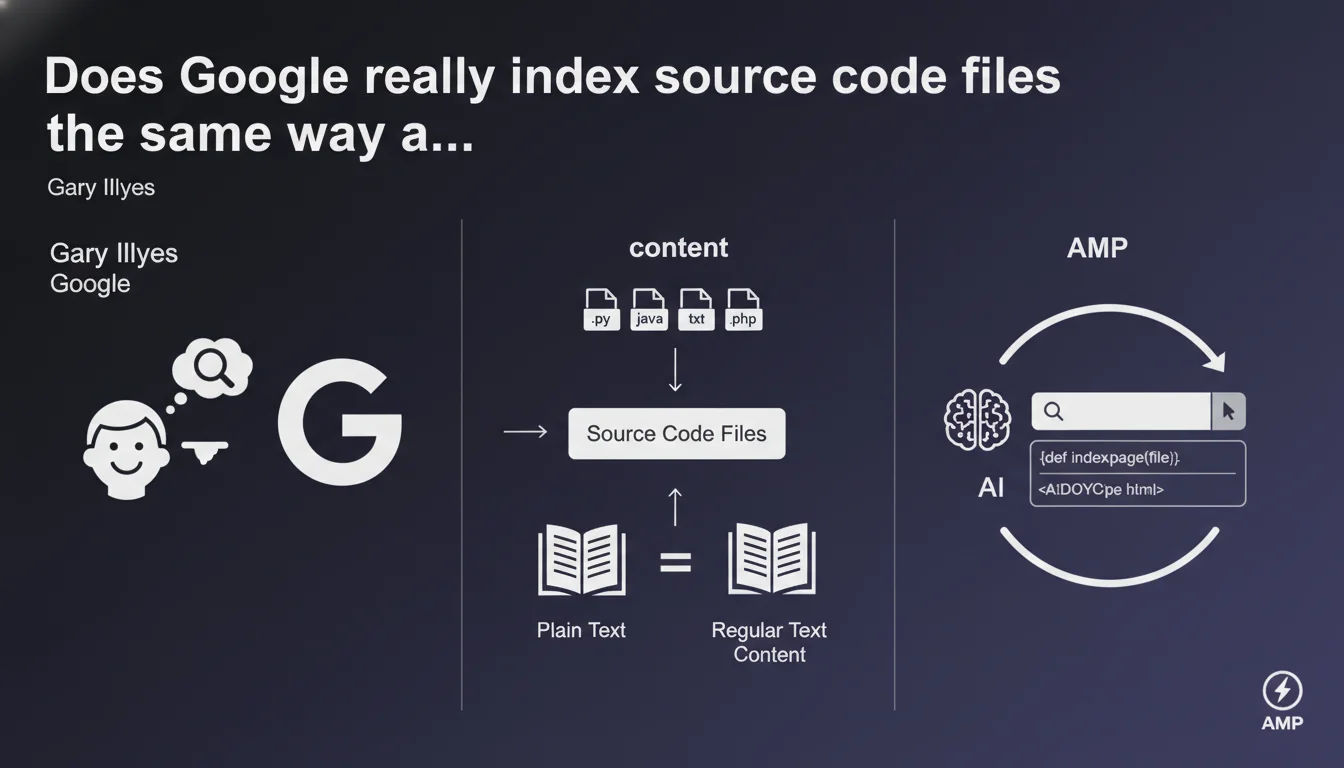
Google indexes code files (.py, .java, .txt, .php) as plain text because code is essentially written prose. These files can therefore appear in search results when someone searches for code examples. A reality that directly impacts how you manage access to your technical files.
What you need to understand
What does Google consider as indexable text?
Google makes no fundamental distinction between a blog post and a Python file. For the search engine, source code is a form of text — a sequence of characters organized according to syntax. This technical approach explains why your .php or .java files can end up in the index.
Concretely, if your site exposes code files accessible to crawlers, they will be treated like any HTML page. Google analyzes them, extracts the textual content, and ranks them based on their relevance to certain queries.
Why does this indexation pose a problem?
Most websites have no interest in seeing their technical files appear in the SERPs. A config.php file or a publicly exposed Python script represents an obvious security risk — not to mention polluting the index with content not intended for users.
But for code-sharing platforms (GitHub, Stack Overflow, technical documentation), it's exactly the opposite: this indexation is a visibility opportunity for actively searched content.
In what cases do these files appear in search results?
Google ranks these files when the query clearly indicates an intention to search for code. Someone typing "recursive function example python" or "JWT authentication code java" is precisely searching for source code, not a theoretical article.
The algorithm detects this intent and can then surface .py or .java files if they match the query better than a standard HTML page.
- Source code is indexed as text without specific processing of its technical nature
- .py, .java, .txt, .php files are crawlable if accessible to robots
- Appearance in the SERPs depends on search intent — queries explicitly targeting code
- Risk of sensitive information leakage if technical files are exposed without protection
- Opportunity for documentation sites and code-sharing platforms
SEO Expert opinion
Is this statement consistent with observed practices?
Yes, absolutely. For years, we've observed that Google indexes and ranks code files. Search "python flask authentication example filetype:py" — you'll find .py files in the results. This isn't a bug, it's a feature.
Gary Illyes' statement simply formalizes what experienced SEOs have noticed for a long time: Google doesn't discriminate between types of textual content. If it's crawlable and readable, it's indexable.
What nuances should be added to this claim?
Saying that "code is prose" remains a technical simplification. Google doesn't compile code, execute it, or understand its logic. It treats it as a series of keywords and syntactic structures — which is fundamentally different from understanding the semantics of natural text.
The algorithm can identify patterns (function names, imported libraries, comments) and use them for ranking, but it doesn't analyze the quality or functional relevance of the code. [To be verified]: Google has never detailed whether signals specific to code (library popularity, correct syntax) influence ranking.
When doesn't this rule apply?
If your code files are protected by robots.txt, authentication, or noindex directives, they obviously won't be indexed — like any blocked content. The problem occurs when these files are accessible by accident.
Additionally, Google may choose not to index certain files even if they're crawlable, particularly if they're deemed low value or massively duplicated (standard libraries copied everywhere). Crawl budget applies to code as well.
Practical impact and recommendations
What concretely should you do to avoid indexing sensitive files?
First step: audit your site to identify all publicly accessible code files. Look for /scripts/, /includes/, /config/ directories, exposed .php, .py, .java files. A simple site:yoursite.com filetype:php search in Google often reveals unpleasant surprises.
Then block access or indexation depending on sensitivity level. For files that must remain technically accessible but invisible in the index, use X-Robots-Tag: noindex in HTTP headers. For complete protection, move them outside the web root or add authentication.
What mistakes should you absolutely avoid?
Don't rely on security by obscurity. A file not linked from your navigation is not protected — bots discover URLs in multiple ways (forgotten sitemaps, exposed logs, external references). If a file is sensitive, it must be technically inaccessible, period.
Another pitfall: using robots.txt to block sensitive files. This directive prevents crawling but doesn't prevent indexation if the URL is known elsewhere. Robots.txt is not a security mechanism — it's a courtesy directive for crawlers.
How can you turn this constraint into an opportunity?
If you manage a technical documentation site, tutorial platform, or developer blog, code file indexation is an asset. Optimize your code examples as content: descriptive filenames, clear comments, usage context.
Add schema.org SoftwareSourceCode markup to enrich the SERP presentation. Link these files from context pages that explain their usage — this strengthens relevance and helps Google understand the search intent behind them.
- Audit your site with site: and filetype: queries to detect indexed code files
- Block indexation of sensitive files via X-Robots-Tag: noindex or authentication
- Never use robots.txt as your only protection for sensitive content
- Move critical technical files outside the publicly accessible web root
- For documentation sites: optimize code files with descriptive names and context
- Add schema.org SoftwareSourceCode markup for code examples meant to be discovered
- Regularly monitor Google's index to detect any unintended exposure
❓ Frequently Asked Questions
Google exécute-t-il le code qu'il indexe ?
Un fichier bloqué par robots.txt peut-il quand même apparaître dans l'index ?
Quels types de fichiers de code Google indexe-t-il prioritairement ?
Comment savoir si mes fichiers de code sont indexés par Google ?
L'indexation de fichiers de code consomme-t-elle du crawl budget inutilement ?
🎥 From the same video 11
Other SEO insights extracted from this same Google Search Central video · published on 08/09/2022
🎥 Watch the full video on YouTube →
💬 Comments (0)
Be the first to comment.