Official statement
Other statements from this video 11 ▾
- □ Les données structurées améliorent-elles vraiment le trafic SEO qualifié ?
- □ Pourquoi Google privilégie-t-il Schema.org pour comprendre vos contenus ?
- □ Faut-il vraiment multiplier les données structurées sur vos pages pour plaire à Google ?
- □ Pourquoi Google recommande-t-il JSON-LD plutôt que Microdata ou RDFa pour les données structurées ?
- □ Faut-il vraiment déléguer les données structurées aux plugins CMS ?
- □ Le Rich Results Test suffit-il vraiment pour valider vos données structurées ?
- □ Search Console alerte-t-elle vraiment sur tous les problèmes de données structurées ?
- □ Les erreurs de données structurées peuvent-elles pénaliser votre référencement ?
- □ Les données structurées hors sujet peuvent-elles vraiment pénaliser votre site ?
- □ Pourquoi les identifiants uniques sont-ils cruciaux pour la désambiguïsation dans Google ?
- □ Les données structurées en conflit peuvent-elles vraiment tuer vos rich snippets ?
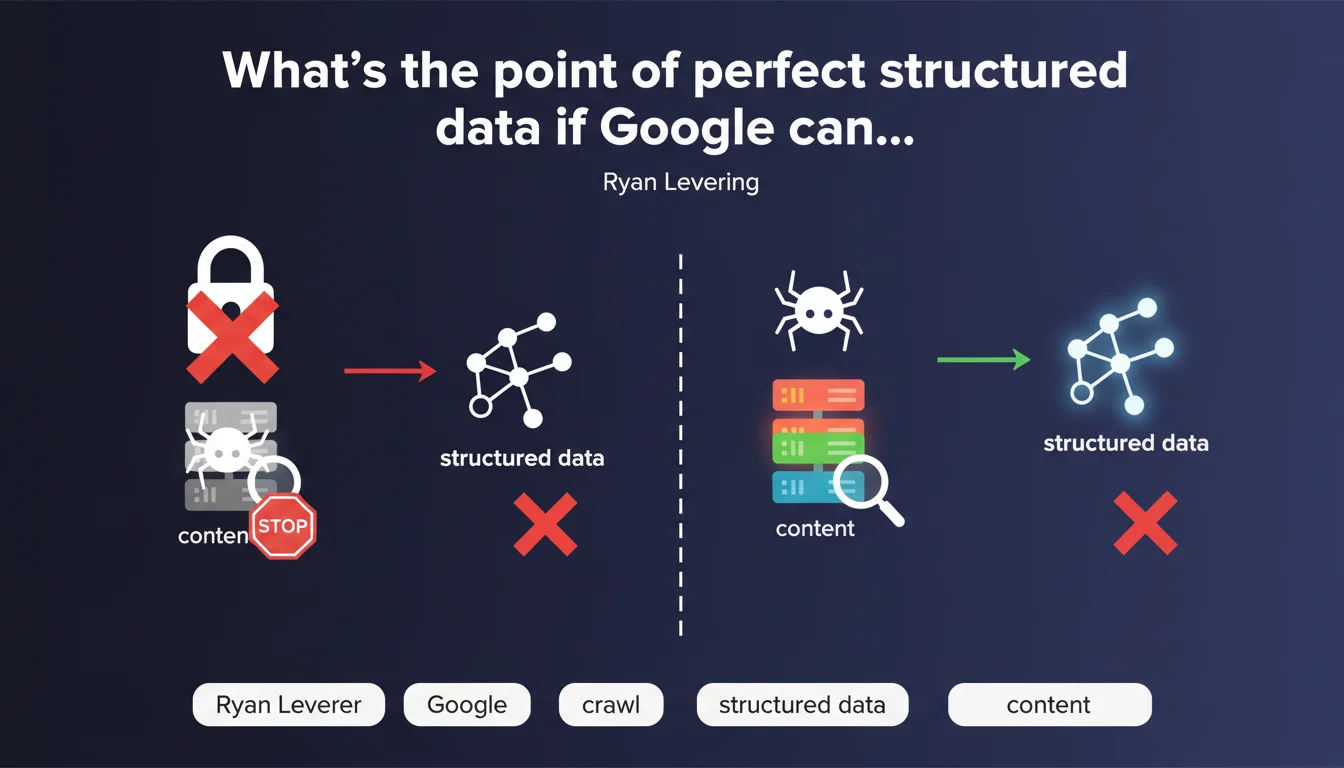
Google cannot leverage your structured data if your pages aren't crawlable. Ryan Levering drives home an often-overlooked truth: before fine-tuning your Schema.org markup, make sure Googlebot actually reaches your content. Without crawl, there's no indexation — and therefore no rich snippets.
What you need to understand
Ryan Levering is stating the obvious — yet it remains a closed door for many websites. Structured data is absolutely useless if Google's crawler cannot crawl the page hosting it. We're talking about relentless logic here: no crawl, no discovery of markup, no exploitation in SERPs.
This statement comes at a time when the Schema.org obsession drives some webmasters to multiply JSON-LD tags without verifying the fundamentals. The result: hours spent on recipes, FAQs, or products that are invisible to Googlebot because the robots.txt blocks access or content is locked behind poorly executed JavaScript.
Is Google actually crawling all your important pages?
Not necessarily. Crawl budget is limited, especially on large sites. Google prioritizes URLs it considers strategic based on popularity, freshness, and depth in site architecture.
If your critical pages — those carrying your structured data — are buried 5 clicks deep from the homepage, poorly linked, or duplicated, they risk never being crawled regularly. And without recent crawl activity, your Schema.org modifications fall through the cracks.
What are the common obstacles preventing crawl?
The classics: overly restrictive robots.txt directives, meta robots tags with noindex/nofollow, redirect chains, catastrophic server response times (>3s), JavaScript-generated content without server-side rendering.
But there are also sneakier mistakes: poorly managed pagination, URLs canonicalized to a non-crawlable version, or CSS/JS resources blocked that prevent full page rendering.
- Crawlability first: verify Googlebot access before any Schema.org optimization
- Robots.txt: never block URLs containing your critical structured data
- Search Console: use the URL inspection tool to validate Google's actual rendering and access
- Crawl budget: optimize internal linking to push your priority pages
- JavaScript: if your Schema.org is injected via JS, ensure Googlebot executes it properly
SEO Expert opinion
Is this statement consistent with real-world practices?
Absolutely. I've seen dozens of sites where FAQ or Product tags were technically perfect — validated by the Rich Results Test — but never appeared in SERPs. Reason: the pages hosting these tags simply weren't being crawled or indexed.
The problem is that Google never screams about this absence of crawl. No red alert in Search Console if your robots.txt blocks an entire category of product sheets. You discover the truth when you notice your stars never appear, despite flawless markup.
Why does this obvious fact still need to be repeated?
Because the SEO ecosystem values sexy optimizations — Schema.org, Core Web Vitals, generative AI — over unglamorous fundamentals. Verifying crawl is a chore. It requires cross-referencing server logs, Search Console, and sometimes debugging obscure JavaScript.
Result: we layer advanced optimizations on rotten foundations. It's like installing a security system in a house with no doors.
In what cases does this rule not apply?
It always applies. [To verify]: one might imagine scenarios where Google indexes a page without complete crawl — for instance via manual URL submission or partial rendering. But in practice, if Googlebot cannot access the page normally, it will never reliably exploit the structured data.
Practical impact and recommendations
What should you do concretely before deploying your structured data?
Launch a crawl of your priority URLs in Googlebot mode (official user-agent) to identify blockages. Use Screaming Frog or Sitebulb by setting the user-agent to "Googlebot". Compare with a crawl using a standard user-agent: any difference reveals potential differential treatment that's problematic.
Next, cross-reference with Search Console: export URLs submitted via sitemap and verify their indexation status. If critical pages show as "Discovered, currently not indexed," it's often a signal of insufficient or blocked crawl.
What errors must you absolutely avoid?
Never block your CSS and JavaScript files in robots.txt — Google needs them for full rendering. Don't use X-Robots-Tag: noindex at the server level on pages you want to appear in rich snippets.
Also avoid deploying structured data only via late asynchronous JavaScript. If Schema.org appears only after a user event (scroll, click), Google will likely never see it.
How do you verify your site is truly crawlable for structured data?
- Inspect 5-10 representative URLs via Search Console's tool and verify the rendered HTML
- Review your server logs to confirm Googlebot is actually accessing the target pages (200 status code)
- Use the Rich Results Test on production URLs, not just staging
- Verify your XML sitemap contains only crawlable and indexable URLs
- Monitor server response time: beyond 2-3s, Google may abandon the crawl
- Test JavaScript rendering with Google's Mobile-Friendly Test tool
❓ Frequently Asked Questions
Est-ce que Google peut exploiter des données structurées sur une page bloquée par le robots.txt ?
Mes données structurées sont valides dans le Rich Results Test mais n'apparaissent pas en SERP. Pourquoi ?
Le JavaScript peut-il empêcher Google de lire mes données structurées ?
Comment savoir si Google crawle suffisamment mes pages avec données structurées ?
Les données structurées peuvent-elles compenser un problème d'indexation ?
🎥 From the same video 11
Other SEO insights extracted from this same Google Search Central video · published on 23/08/2022
🎥 Watch the full video on YouTube →
💬 Comments (0)
Be the first to comment.