Declaration officielle
Autres déclarations de cette vidéo 20 ▾
- □ Comment Google indexe-t-il réellement le contenu des iframes ?
- □ Faut-il vraiment privilégier une structure hiérarchique pour les grands sites ?
- □ Bloquer le crawl via robots.txt : solution miracle contre les liens toxiques ?
- □ Faut-il traduire ses URLs pour améliorer son référencement international ?
- □ Pourquoi Googlebot ignore-t-il la balise meta prerender-status-code 404 dans les applications JavaScript ?
- □ Pourquoi les migrations de sites échouent-elles si souvent malgré une préparation SEO ?
- □ Les doubles slashes dans les URLs sont-ils un problème pour le SEO ?
- □ Pourquoi Google pénalise-t-il les vidéos hors du viewport et comment y remédier ?
- □ Comment transférer efficacement le classement de vos images vers de nouvelles URLs ?
- □ Faut-il vraiment s'inquiéter des erreurs 404 sur son site ?
- □ HTTP 200 sur une page 404 : soft 404 ou cloaking ?
- □ Faut-il s'inquiéter si Googlebot crawle vos endpoints API et génère des 404 ?
- □ L'accessibilité web est-elle vraiment un facteur de classement Google ou un écran de fumée ?
- □ L'achat de liens reste-t-il vraiment sanctionné par Google ?
- □ Faut-il encore signaler les mauvais backlinks à Google ?
- □ Pourquoi bloquer le crawl via robots.txt empêche-t-il Google de voir votre directive noindex ?
- □ Pourquoi Google refuse-t-il l'idée d'une formule magique pour ranker ?
- □ Pourquoi Google affiche-t-il mal vos caractères spéciaux dans ses résultats ?
- □ Google Analytics et Search Console : pourquoi ces différences de données posent-elles problème ?
- □ Faut-il vraiment viser le SEO parfait ?
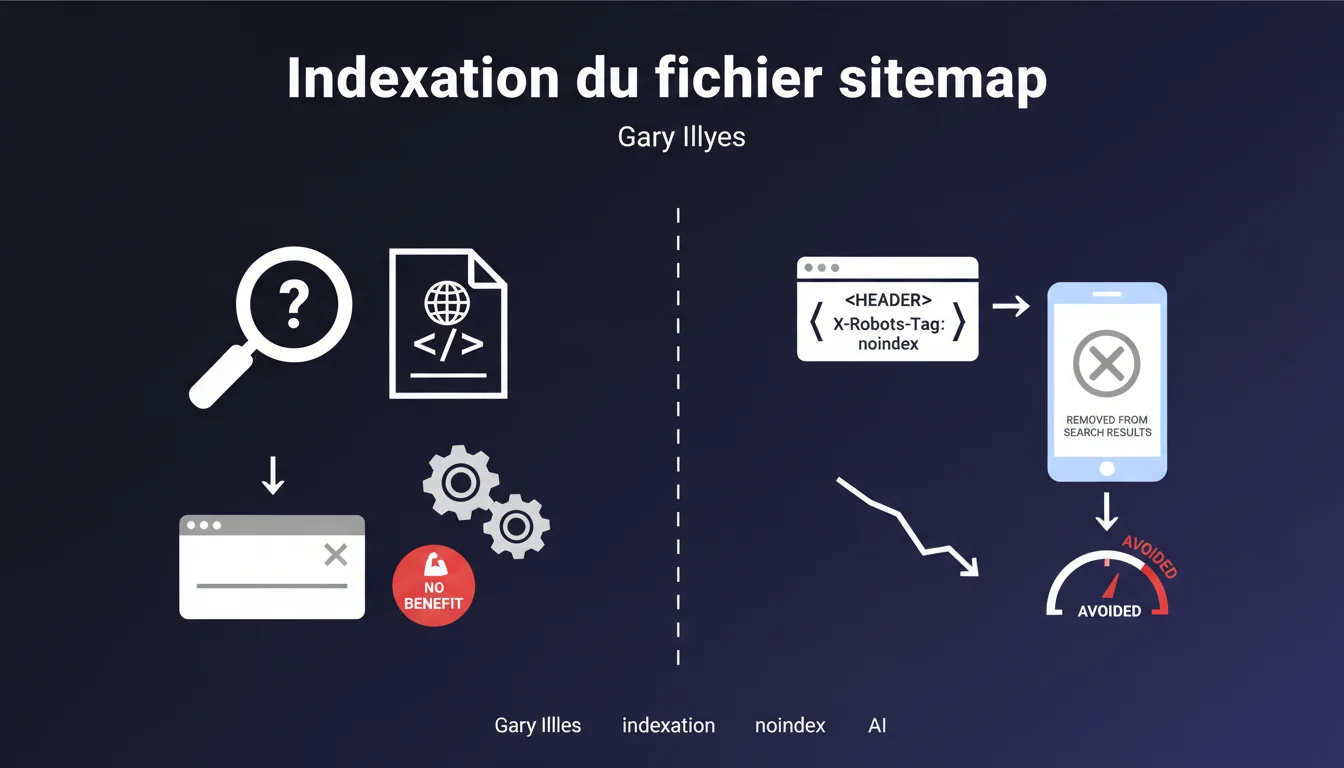
Google peut indexer votre sitemap, mais forcer cette indexation ne sert strictement à rien. Si vous voulez l'exclure des résultats, utilisez un header HTTP robots noindex — c'est la seule méthode efficace. Contrairement à une idée reçue, l'indexation du sitemap n'impacte ni positivement ni négativement votre référencement.
Ce qu'il faut comprendre
Pourquoi Google indexe-t-il parfois les fichiers sitemap ?
Un fichier sitemap est techniquement une ressource web comme une autre. Si Googlebot le découvre via un lien interne, externe ou une soumission dans Search Console, il peut décider de l'indexer. Rien d'anormal là-dedans.
L'indexation du sitemap se produit généralement quand il est accessible publiquement et qu'aucune directive d'exclusion n'est en place. C'est un comportement par défaut du crawler — pas un bug, pas un signal de qualité.
Est-ce que l'indexation du sitemap nuit au référencement ?
La réponse est simple : non. Gary Illyes est formel sur ce point. Un sitemap indexé ne consomme pas votre crawl budget de manière significative, ne dilue pas votre pertinence thématique, et ne provoque aucune pénalité algorithmique.
C'est du bruit dans vos rapports Search Console, rien de plus. Beaucoup de SEO ont une réaction épidermique en voyant leur sitemap.xml dans l'index, mais c'est un non-problème technique.
Quelle est la méthode officielle pour bloquer l'indexation du sitemap ?
Si vous voulez absolument retirer votre sitemap de l'index, Google recommande d'ajouter un header HTTP X-Robots-Tag: noindex dans la réponse serveur de votre fichier sitemap.xml. C'est la directive standard pour les ressources non-HTML.
Le robots.txt ne suffit pas ici — bloquer le crawl empêche Googlebot de voir la directive noindex, donc la ressource peut rester indexée avec un snippet générique. C'est un piège classique.
- Un sitemap peut être indexé, c'est un comportement normal de Googlebot
- L'indexation du sitemap n'a aucun impact négatif sur le référencement
- Forcer l'indexation du sitemap via des techniques artificielles est inutile
- Pour exclure le sitemap de l'index, utilisez un header HTTP X-Robots-Tag: noindex
- Ne bloquez pas le sitemap dans robots.txt si vous voulez le désindexer efficacement
Avis d'un expert SEO
Cette déclaration correspond-elle aux observations terrain ?
Oui, totalement. Sur des centaines d'audits, je n'ai jamais constaté de corrélation entre l'indexation du sitemap et une dégradation des performances SEO. C'est confirmé : aucun impact mesurable.
Par contre, j'ai vu des SEO perdre du temps à tenter de forcer la désindexation via des méthodes bancales — robots.txt, suppression d'URL dans Search Console, etc. Résultat : le sitemap reste indexé et le temps aurait été mieux investi ailleurs.
Pourquoi certains SEO s'acharnent-ils à désindexer leur sitemap ?
C'est souvent une question de perception de propreté. Un sitemap dans l'index, c'est perçu comme une pollution des résultats de recherche, une faille d'hygiène technique. Sauf que Google s'en fiche complètement.
Il y a aussi une confusion entre crawl budget et indexation. Certains pensent qu'un sitemap indexé consomme des ressources précieuses. Faux — le fichier est crawlé une fois, et ensuite c'est anecdotique. [À vérifier] : Google n'a jamais publié de données chiffrées sur le poids exact d'un sitemap indexé dans le crawl budget global d'un site moyen.
Dans quels cas faut-il quand même bloquer l'indexation du sitemap ?
Franchement ? Si votre sitemap contient des données sensibles (URLs de staging, endpoints API, structures de répertoires que vous préférez garder privées), là oui, bloquez-le. Mais c'est rare.
Pour un site classique avec un sitemap.xml standard, c'est cosmétique. Si ça vous obsède, ajoutez le header noindex et passez à autre chose. Sinon, laissez tomber — votre temps SEO a plus de valeur que ça.
Impact pratique et recommandations
Que faire si mon sitemap est actuellement indexé ?
Si cela ne vous dérange pas et que vous avez compris que c'est sans conséquence SEO, ne faites rien. Économisez votre énergie pour des chantiers qui ont un ROI mesurable.
Si vous voulez quand même le retirer, configurez votre serveur pour renvoyer un header X-Robots-Tag: noindex sur toutes les requêtes vers sitemap.xml. En Apache : Header set X-Robots-Tag "noindex" dans votre .htaccess ou configuration serveur. En Nginx : add_header X-Robots-Tag "noindex";.
Comment vérifier que la directive noindex est bien active ?
Utilisez les DevTools de votre navigateur (onglet Network) ou une commande curl pour inspecter les headers HTTP de votre sitemap. Vous devez voir X-Robots-Tag: noindex dans la réponse.
Ensuite, patience — la désindexation peut prendre plusieurs semaines selon la fréquence de crawl de votre site. Vous pouvez demander une suppression temporaire via Search Console pour accélérer, mais ce n'est pas obligatoire.
Quelles erreurs techniques éviter absolument ?
Ne bloquez pas le sitemap dans robots.txt si votre objectif est de le désindexer. Googlebot ne pourra pas voir le header noindex, et l'URL restera dans l'index avec un snippet vide. C'est contre-productif.
Évitez aussi de renvoyer un code 404 sur le sitemap pour le faire disparaître — vous perdez alors sa fonction première, qui est d'aider Google à découvrir vos URLs. Si vous voulez qu'il soit crawlé mais pas indexé, laissez-le accessible avec un 200 + noindex.
- Décider si l'indexation du sitemap justifie réellement une action (spoiler : probablement non)
- Configurer un header HTTP X-Robots-Tag: noindex sur sitemap.xml si désindexation souhaitée
- Vérifier la présence du header avec curl ou les DevTools navigateur
- Ne jamais bloquer le sitemap dans robots.txt pour le désindexer
- Maintenir le sitemap accessible en HTTP 200 pour que Google continue de le crawler
- Patienter plusieurs semaines pour constater la désindexation effective
❓ Questions frequentes
Un sitemap indexé consomme-t-il du crawl budget ?
Peut-on utiliser robots.txt pour empêcher l'indexation du sitemap ?
Combien de temps faut-il pour qu'un sitemap disparaisse de l'index après ajout du noindex ?
L'indexation du sitemap peut-elle provoquer du duplicate content ?
Dois-je supprimer mon sitemap de Search Console s'il est indexé ?
🎥 De la même vidéo 20
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 18/12/2023
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.