Declaration officielle
Autres déclarations de cette vidéo 20 ▾
- □ Comment Google indexe-t-il réellement le contenu des iframes ?
- □ Faut-il vraiment privilégier une structure hiérarchique pour les grands sites ?
- □ Faut-il traduire ses URLs pour améliorer son référencement international ?
- □ Pourquoi Googlebot ignore-t-il la balise meta prerender-status-code 404 dans les applications JavaScript ?
- □ Pourquoi les migrations de sites échouent-elles si souvent malgré une préparation SEO ?
- □ Les doubles slashes dans les URLs sont-ils un problème pour le SEO ?
- □ Pourquoi Google pénalise-t-il les vidéos hors du viewport et comment y remédier ?
- □ Comment transférer efficacement le classement de vos images vers de nouvelles URLs ?
- □ Faut-il vraiment s'inquiéter des erreurs 404 sur son site ?
- □ HTTP 200 sur une page 404 : soft 404 ou cloaking ?
- □ Faut-il forcer l'indexation de son fichier sitemap dans Google ?
- □ Faut-il s'inquiéter si Googlebot crawle vos endpoints API et génère des 404 ?
- □ L'accessibilité web est-elle vraiment un facteur de classement Google ou un écran de fumée ?
- □ L'achat de liens reste-t-il vraiment sanctionné par Google ?
- □ Faut-il encore signaler les mauvais backlinks à Google ?
- □ Pourquoi bloquer le crawl via robots.txt empêche-t-il Google de voir votre directive noindex ?
- □ Pourquoi Google refuse-t-il l'idée d'une formule magique pour ranker ?
- □ Pourquoi Google affiche-t-il mal vos caractères spéciaux dans ses résultats ?
- □ Google Analytics et Search Console : pourquoi ces différences de données posent-elles problème ?
- □ Faut-il vraiment viser le SEO parfait ?
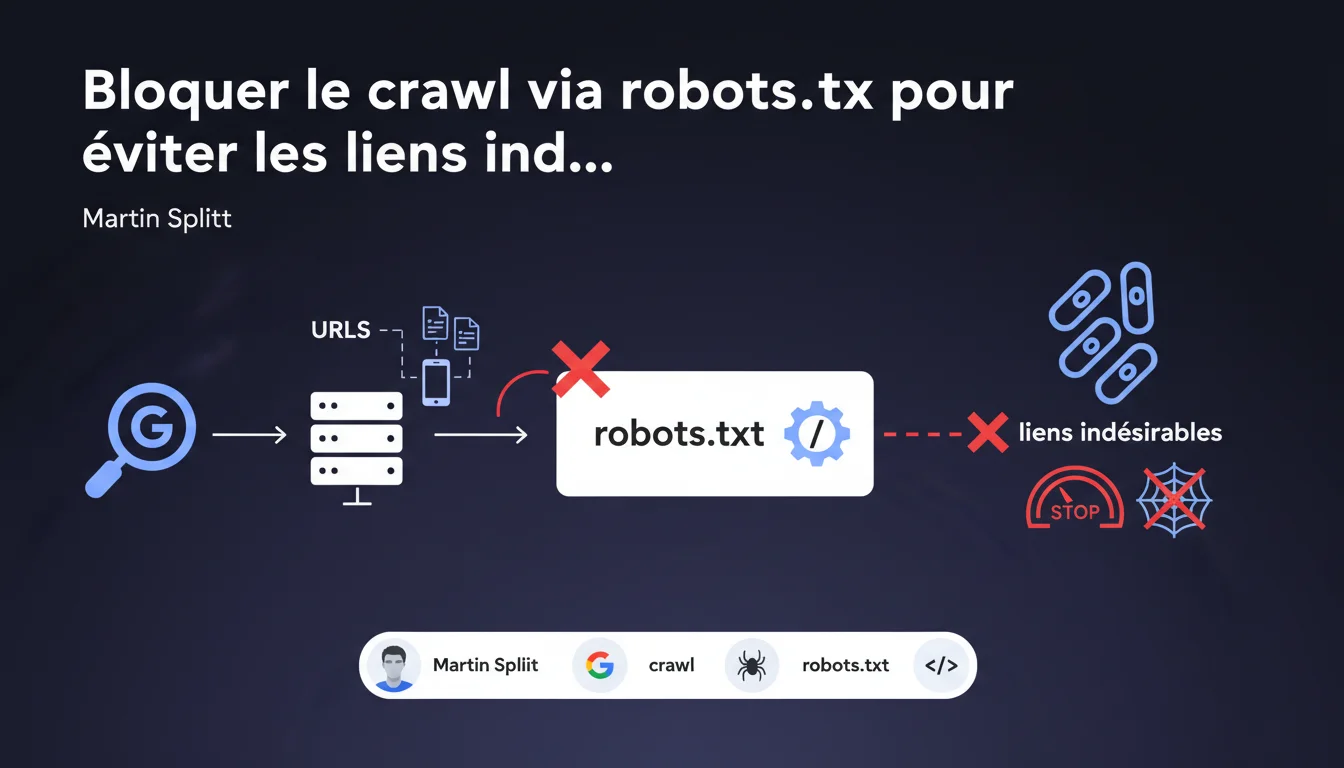
Martin Splitt confirme que bloquer une URL dans robots.txt empêche Googlebot de la crawler et donc de découvrir les liens qu'elle contient. Pas de crawl = pas de suivi de liens sortants. C'est la base, mais attention : cette méthode ne désindexe pas une page déjà crawlée et peut avoir des effets de bord sur votre budget crawl.
Ce qu'il faut comprendre
Que dit exactement cette déclaration ?
La logique est simple : si vous interdisez une URL dans robots.txt, Googlebot ne peut pas faire de requête vers cette ressource. Sans requête, pas d'accès au HTML, donc pas de découverte des liens sortants présents dans cette page.
Cela signifie que si une page de votre site contient des liens vers des sites douteux ou des URLs que vous ne souhaitez pas associer à votre domaine, le blocage robots.txt empêche Google de suivre ces liens. En théorie, vous coupez la transmission de « jus » ou de signal vers ces destinations.
Pourquoi Google insiste sur ce point ?
Parce que beaucoup de webmasters confondent blocage du crawl et désindexation. Bloquer dans robots.txt n'empêche pas une URL d'apparaître dans les résultats si elle a déjà été indexée via d'autres signaux (backlinks externes, sitemaps).
L'objectif ici est de contrôler ce que Googlebot explore, pas forcément ce qu'il indexe. Si votre problème est la présence de liens sortants indésirables, robots.txt est effectivement une solution.
Quels sont les cas d'usage concrets ?
- Pages de redirection tierces : URLs de tracking, affiliations douteuses, redirections temporaires vers des sites peu recommandables.
- Sections compromises : parties du site hackées avec injection de liens spammy que vous n'avez pas encore nettoyées.
- Contenus générés par utilisateurs : forums, commentaires avec liens nofollow insuffisants ou zones à risque.
- Pages d'archive ou de test contenant des liens expérimentaux que vous ne voulez pas voir crawlés.
Avis d'un expert SEO
Cette déclaration est-elle cohérente avec les observations terrain ?
Oui, et c'est même l'un des rares points sur lesquels Google est parfaitement transparent. Bloquer dans robots.txt = pas de crawl = pas de suivi de liens. C'est vérifiable dans Search Console et dans les logs serveur.
Mais — et c'est là que ça coince — cette approche ne résout qu'une partie du problème. Si la page bloquée était déjà crawlée avant l'ajout de la règle, Google conserve en mémoire les liens qu'il a découverts. Il faut donc agir vite ou combiner avec d'autres actions (nofollow, suppression physique du lien).
Quelles nuances faut-il apporter ?
Première nuance : robots.txt bloque le crawl, pas l'indexation. Si des backlinks externes pointent vers l'URL bloquée, elle peut toujours apparaître dans l'index avec une description générique type « Aucune information disponible ». Pour désindexer, il faut un noindex en HTTP header ou en meta tag — mais pour ça, il faut autoriser le crawl. Le paradoxe classique.
Deuxième point : bloquer massivement dans robots.txt peut créer des zones opaques pour Googlebot. Si vous bloquez des sections entières sans stratégie claire, vous risquez de cacher involontairement des contenus légitimes ou de compliquer l'exploration de votre architecture de liens. Le budget crawl se redistribue ailleurs, pas toujours là où vous le souhaitez.
Dans quels cas cette règle ne suffit-elle pas ?
Si les liens indésirables sont sur des pages que vous voulez indexer, robots.txt n'est pas la solution. Vous devez alors utiliser l'attribut rel="nofollow" ou rel="ugc" sur les liens concernés, voire rel="sponsored" si c'est du contenu affilié.
Autre limite : les liens en JavaScript. Si vos liens sont injectés côté client après le rendu initial, Googlebot peut les découvrir lors du second passage de rendu. Bloquer la page en robots.txt empêche le crawl initial, mais si le JS charge des URLs depuis une ressource externe non bloquée, le signal peut quand même transiter. [À vérifier] selon votre stack technique.
Impact pratique et recommandations
Que faut-il faire concrètement ?
Identifiez d'abord les URLs problématiques. Utilisez Screaming Frog ou un crawler équivalent pour lister toutes les pages contenant des liens sortants suspects. Croisez avec vos logs serveur pour voir si Googlebot a crawlé ces pages récemment.
Ensuite, ajoutez les chemins concernés dans votre fichier robots.txt avec une directive Disallow claire. Testez via l'outil de test robots.txt dans Search Console pour vérifier que la règle fonctionne. Surveillez ensuite vos logs : si Googlebot continue de tenter d'accéder, c'est qu'il y a une erreur de syntaxe ou un conflit de règles.
Quelles erreurs éviter ?
Ne bloquez pas une URL qui contient du contenu de valeur uniquement pour masquer quelques liens sortants. Vous perdriez le bénéfice SEO de cette page. Préférez nettoyer les liens ou les passer en nofollow.
Évitez aussi les règles trop larges type Disallow: /blog/ si seule une poignée d'articles pose problème. Soyez chirurgical. Un robots.txt mal configuré peut bloquer des sections entières de votre site et provoquer une chute de visibilité brutale.
Comment vérifier que votre stratégie fonctionne ?
- Testez chaque règle Disallow avec l'outil robots.txt de Search Console
- Analysez vos logs serveur après déploiement : les hits Googlebot doivent disparaître sur les URLs bloquées
- Vérifiez dans Search Console (onglet Couverture) que les pages bloquées ne génèrent pas d'erreurs d'indexation inattendues
- Contrôlez avec un crawler externe (Screaming Frog) que les liens sortants des pages bloquées ne sont plus découverts
- Surveillez votre budget crawl global : si vous bloquez beaucoup, Googlebot doit redistribuer son activité sur d'autres sections prioritaires
❓ Questions frequentes
Bloquer une page dans robots.txt empêche-t-il son indexation ?
Puis-je bloquer uniquement certains liens sortants d'une page sans la bloquer entièrement ?
Si je bloque une page déjà crawlée, Google oublie-t-il les liens qu'il y a découverts ?
Bloquer des sections entières dans robots.txt impacte-t-il mon budget crawl ?
Les liens en JavaScript sont-ils concernés par le blocage robots.txt ?
🎥 De la même vidéo 20
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 18/12/2023
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.