Declaration officielle
Autres déclarations de cette vidéo 20 ▾
- □ Comment Google indexe-t-il réellement le contenu des iframes ?
- □ Faut-il vraiment privilégier une structure hiérarchique pour les grands sites ?
- □ Bloquer le crawl via robots.txt : solution miracle contre les liens toxiques ?
- □ Faut-il traduire ses URLs pour améliorer son référencement international ?
- □ Pourquoi Googlebot ignore-t-il la balise meta prerender-status-code 404 dans les applications JavaScript ?
- □ Pourquoi les migrations de sites échouent-elles si souvent malgré une préparation SEO ?
- □ Les doubles slashes dans les URLs sont-ils un problème pour le SEO ?
- □ Pourquoi Google pénalise-t-il les vidéos hors du viewport et comment y remédier ?
- □ Comment transférer efficacement le classement de vos images vers de nouvelles URLs ?
- □ Faut-il vraiment s'inquiéter des erreurs 404 sur son site ?
- □ HTTP 200 sur une page 404 : soft 404 ou cloaking ?
- □ Faut-il forcer l'indexation de son fichier sitemap dans Google ?
- □ L'accessibilité web est-elle vraiment un facteur de classement Google ou un écran de fumée ?
- □ L'achat de liens reste-t-il vraiment sanctionné par Google ?
- □ Faut-il encore signaler les mauvais backlinks à Google ?
- □ Pourquoi bloquer le crawl via robots.txt empêche-t-il Google de voir votre directive noindex ?
- □ Pourquoi Google refuse-t-il l'idée d'une formule magique pour ranker ?
- □ Pourquoi Google affiche-t-il mal vos caractères spéciaux dans ses résultats ?
- □ Google Analytics et Search Console : pourquoi ces différences de données posent-elles problème ?
- □ Faut-il vraiment viser le SEO parfait ?
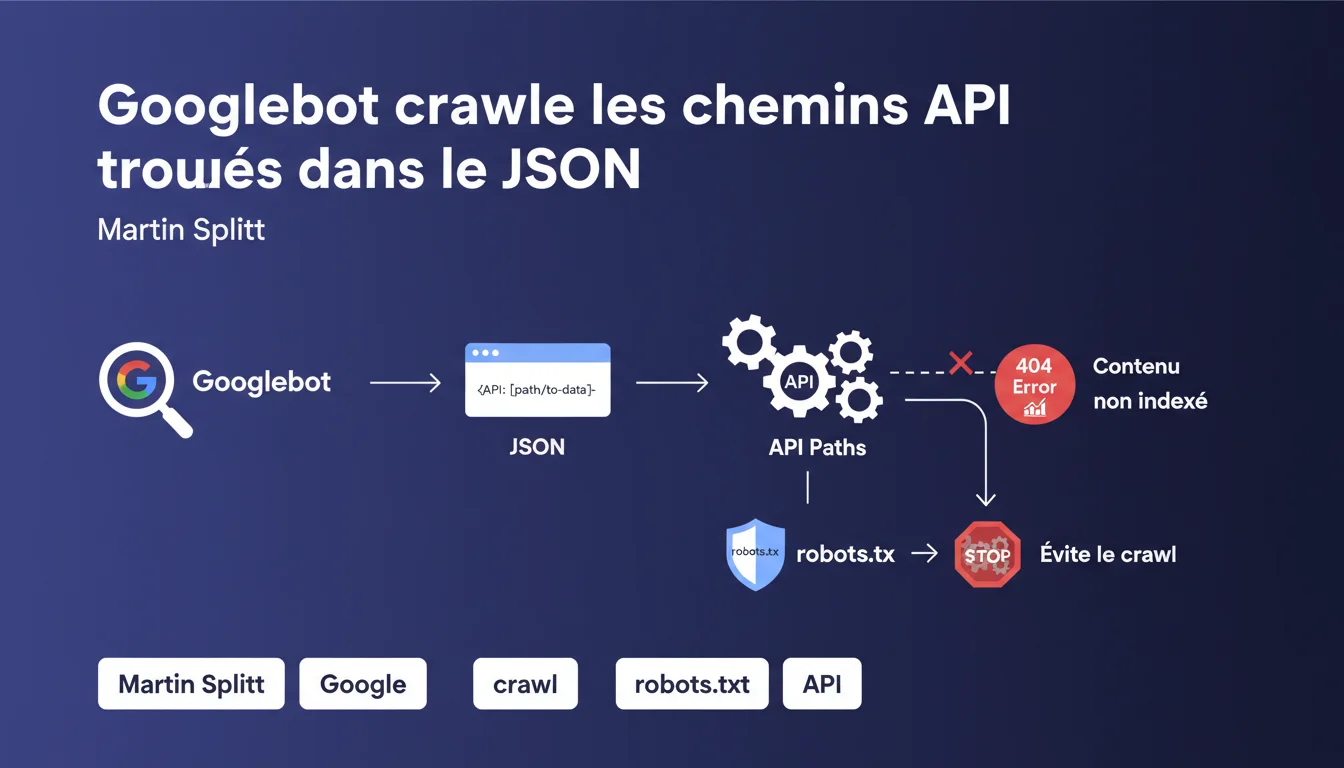
Googlebot peut crawler des URLs d'API découvertes dans du JSON brut et générer des erreurs 404. Ce comportement est normal et sans danger pour l'indexation. Si ces erreurs parasitent vos logs, bloquez ces chemins via robots.txt.
Ce qu'il faut comprendre
Pourquoi Googlebot crawle-t-il des endpoints API trouvés dans du JSON ?
Googlebot analyse le contenu des pages, y compris les structures JSON exposées. Lorsqu'il détecte des chaînes de caractères ressemblant à des URLs, il peut tenter de les crawler, même s'il s'agit de chemins API internes non destinés à être indexés.
Ce comportement s'explique par la nature exploratoire du bot : il suit les liens et les références qu'il trouve, sans distinguer automatiquement une URL de page web d'un endpoint REST. Si votre JSON expose des chemins comme /api/v2/products/{id}, Googlebot peut les considérer comme des ressources potentielles.
Les erreurs 404 générées impactent-elles le référencement ?
Non. Martin Splitt est clair : obtenir un 404 signifie simplement que le contenu ne sera pas indexé. Il n'y a pas de pénalité liée à ces erreurs, et elles n'affectent pas le crawl budget de manière significative si elles restent proportionnelles au volume global du site.
Le vrai problème se situe ailleurs : ces 404 peuvent polluer vos rapports Search Console et vos logs serveur, rendant difficile l'identification d'erreurs légitimes sur des pages importantes. C'est une question de clarté analytique, pas de sanction algorithmique.
Comment empêcher Googlebot de crawler ces chemins API ?
La solution recommandée par Google est d'utiliser le fichier robots.txt. En ajoutant une directive Disallow pour les chemins API concernés, vous évitez que Googlebot ne tente de les crawler.
Exemple typique :
- User-agent: *
- Disallow: /api/
- Disallow: /v1/
- Disallow: /v2/
Cette approche préventive évite l'accumulation d'erreurs parasites sans nécessiter de modifications côté applicatif.
Avis d'un expert SEO
Cette déclaration correspond-elle aux observations terrain ?
Oui, ce comportement est documenté depuis des années dans les logs serveur. Les crawlers de Google sont particulièrement gourmands en extraction de patterns d'URLs, surtout sur les sites utilisant massivement des API REST exposées dans le DOM ou dans des blocs JSON-LD.
Ce qui surprend encore certains praticiens, c'est que Googlebot ne se limite pas aux balises <a href>. Il parse aussi les attributs data-, les scripts JavaScript, et toute structure JSON visible. Si vous exposez un schéma OpenAPI ou Swagger en clair, attendez-vous à voir ces chemins dans vos logs.
Y a-t-il des cas où ces 404 peuvent devenir problématiques ?
Rarement, mais ça arrive. Si votre architecture génère des milliers d'endpoints API dynamiques et que Googlebot les découvre tous, vous risquez une inflation artificielle du crawl budget. Sur des sites de taille modeste, l'impact est négligeable. Sur des plateformes avec des millions de pages, ça peut diluer l'attention du bot.
Autre cas limite : si vos endpoints API retournent du HTML par erreur au lieu d'un 404 propre, Googlebot peut tenter de les indexer. Vérifiez que vos routes API renvoient bien des codes HTTP corrects et pas des pages d'erreur génériques en 200.
Faut-il systématiquement bloquer les chemins API via robots.txt ?
Pas forcément. Si vos endpoints API sont déjà protégés par authentification ou renvoient des 401/403, Googlebot ne pourra pas y accéder de toute façon. Le blocage via robots.txt devient pertinent quand ces chemins sont publiquement accessibles mais non indexables.
Soyons honnêtes : beaucoup de sites exposent leurs API de manière trop permissive. C'est souvent une question de configuration infrastructure — les équipes dev ne pensent pas toujours aux implications crawl. [À vérifier] sur votre propre architecture : auditez vos logs pour identifier les patterns de crawl sur /api/ ou /v1/ avant de décider.
Impact pratique et recommandations
Que faut-il vérifier en priorité sur votre site ?
Commencez par analyser vos logs serveur et la Search Console. Recherchez les erreurs 404 sur des chemins contenant /api/, /v1/, /v2/, /graphql/, ou tout pattern d'endpoint REST. Si vous trouvez des volumes significatifs, c'est que Googlebot crawle ces ressources.
Ensuite, inspectez votre code front-end et vos fichiers JSON exposés. Cherchez les endroits où des URLs d'API sont écrites en dur dans le HTML, les scripts ou les données structurées. Ce sont autant de points d'entrée pour le bot.
Quelles actions correctives mettre en place ?
Si le volume d'erreurs 404 sur les API est faible (quelques dizaines par mois), ne faites rien. C'est du bruit acceptable. En revanche, si vous constatez des centaines ou milliers de requêtes parasites, ajoutez des directives Disallow dans robots.txt pour les chemins concernés.
Exemple de configuration minimale :
- Disallow: /api/
- Disallow: /rest/
- Disallow: /graphql/
- Disallow: /v1/
- Disallow: /v2/
Attention : ne bloquez pas par erreur des chemins qui servent du contenu indexable. Certains sites utilisent /api/ pour des pages réelles. Vérifiez chaque pattern avant de l'interdire.
Comment éviter ce problème en amont ?
Si vous concevez une nouvelle architecture, isolez vos API sur un sous-domaine dédié (ex : api.votresite.com). Cela simplifie la gestion du crawl : un robots.txt global sur le sous-domaine suffit, sans risque de conflit avec les pages publiques.
Autre bonne pratique : ne jamais exposer d'URLs d'API complètes dans le HTML ou le JSON-LD. Utilisez des chemins relatifs internes côté application, et réservez les endpoints REST aux appels JavaScript authentifiés.
En résumé : les 404 sur les chemins API sont bénins mais peuvent polluer vos logs. Bloquez-les via robots.txt si le volume devient gênant. Vérifiez que vos routes API renvoient bien des codes HTTP appropriés. Et idéalement, isolez vos API sur un sous-domaine pour simplifier la gestion.
Ces optimisations techniques peuvent nécessiter une coordination entre équipes dev, infra et SEO. Si votre architecture est complexe ou si vous manquez de ressources internes pour auditer finement les logs et ajuster la configuration, un accompagnement par une agence SEO spécialisée peut accélérer la mise en conformité et éviter les erreurs de manipulation sur robots.txt.
❓ Questions frequentes
Les erreurs 404 sur les chemins API nuisent-elles au référencement ?
Dois-je bloquer tous les chemins /api/ par défaut ?
Googlebot crawle-t-il aussi les API protégées par authentification ?
Un sous-domaine dédié aux API est-il vraiment nécessaire ?
Comment savoir si Googlebot crawle mes endpoints API ?
🎥 De la même vidéo 20
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 18/12/2023
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.