Declaration officielle
Autres déclarations de cette vidéo 20 ▾
- □ Comment Google indexe-t-il réellement le contenu des iframes ?
- □ Bloquer le crawl via robots.txt : solution miracle contre les liens toxiques ?
- □ Faut-il traduire ses URLs pour améliorer son référencement international ?
- □ Pourquoi Googlebot ignore-t-il la balise meta prerender-status-code 404 dans les applications JavaScript ?
- □ Pourquoi les migrations de sites échouent-elles si souvent malgré une préparation SEO ?
- □ Les doubles slashes dans les URLs sont-ils un problème pour le SEO ?
- □ Pourquoi Google pénalise-t-il les vidéos hors du viewport et comment y remédier ?
- □ Comment transférer efficacement le classement de vos images vers de nouvelles URLs ?
- □ Faut-il vraiment s'inquiéter des erreurs 404 sur son site ?
- □ HTTP 200 sur une page 404 : soft 404 ou cloaking ?
- □ Faut-il forcer l'indexation de son fichier sitemap dans Google ?
- □ Faut-il s'inquiéter si Googlebot crawle vos endpoints API et génère des 404 ?
- □ L'accessibilité web est-elle vraiment un facteur de classement Google ou un écran de fumée ?
- □ L'achat de liens reste-t-il vraiment sanctionné par Google ?
- □ Faut-il encore signaler les mauvais backlinks à Google ?
- □ Pourquoi bloquer le crawl via robots.txt empêche-t-il Google de voir votre directive noindex ?
- □ Pourquoi Google refuse-t-il l'idée d'une formule magique pour ranker ?
- □ Pourquoi Google affiche-t-il mal vos caractères spéciaux dans ses résultats ?
- □ Google Analytics et Search Console : pourquoi ces différences de données posent-elles problème ?
- □ Faut-il vraiment viser le SEO parfait ?
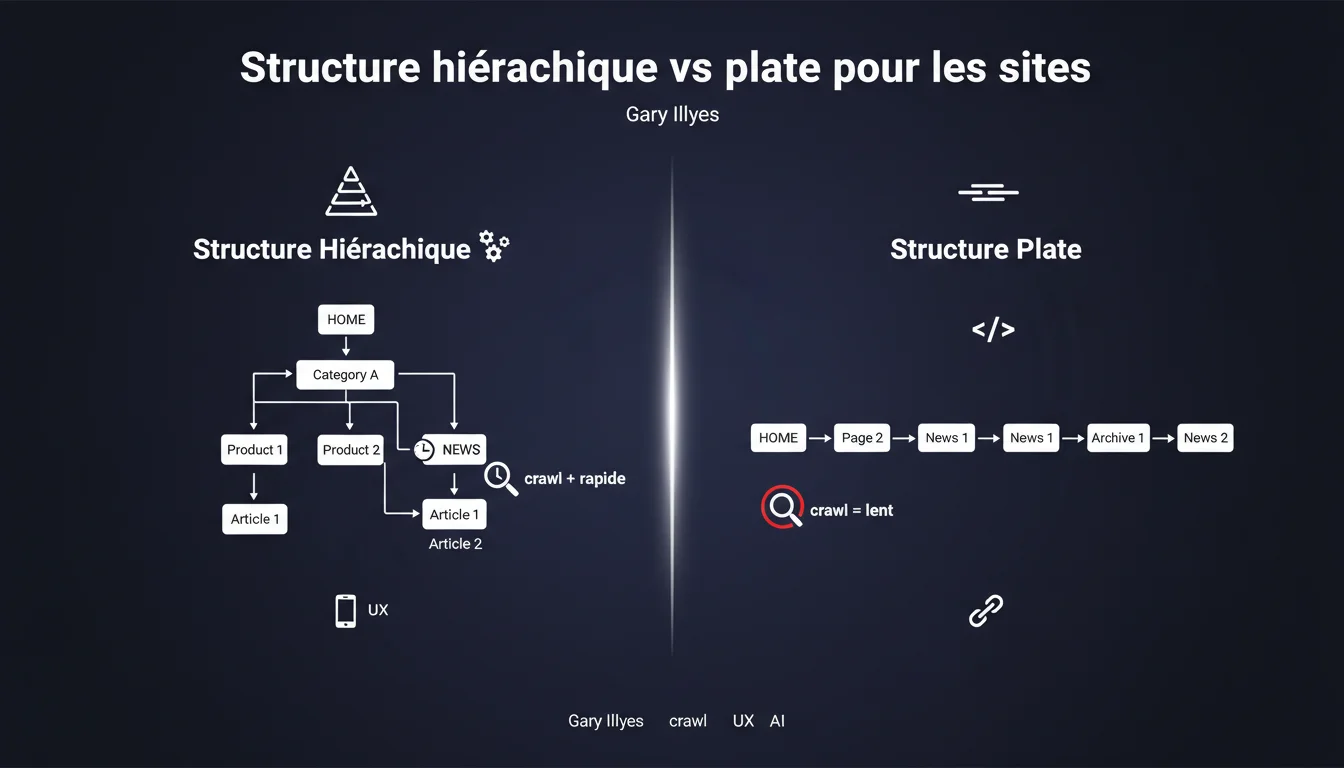
Google recommande explicitement une structure hiérarchique pour les grands sites car elle permet de différencier le traitement du crawl selon les sections. Sans cette organisation en répertoires distincts (ex: /news/ vs /archives/), impossible d'optimiser la fréquence de crawl par typologie de contenu.
Ce qu'il faut comprendre
Pourquoi Google insiste-t-il sur la structure hiérarchique pour les grands sites ?
La réponse de Gary Illyes est claire : la structure hiérarchique offre un levier de contrôle du crawl que la structure plate ne permet pas. Concrètement, en isolant vos contenus dans des répertoires dédiés (/news/, /blog/, /produits/), vous donnez des indices structurels à Googlebot pour adapter sa stratégie de crawl.
L'exemple du répertoire 'news' est révélateur. Si votre contenu d'actualité se trouve dans /news/, Google peut crawler ces URLs plus fréquemment que vos archives statiques. Si tout est au même niveau (structure plate), cette différenciation devient impossible — ou du moins, beaucoup plus complexe à gérer via d'autres signaux.
Qu'est-ce qui caractérise une structure plate vs hiérarchique ?
Structure plate : toutes les pages au même niveau (exemple.com/page1, exemple.com/page2, exemple.com/page3). Aucune organisation logique visible dans l'URL. Pertinent pour les petits sites de 20-50 pages maximum où cette distinction n'a pas d'impact mesurable.
Structure hiérarchique : organisation en répertoires et sous-répertoires qui reflète la logique du contenu (exemple.com/categorie/sous-categorie/page). Cette approche facilite la gestion du crawl budget et la compréhension thématique par les moteurs.
Dans quels cas cette recommandation s'applique-t-elle vraiment ?
Google parle explicitement de "grands sites". Soyons honnêtes : si vous gérez 100 pages, cette problématique ne vous concerne probablement pas. Le seuil critique se situe plutôt autour de 1000+ pages, ou dès que vous avez des contenus à cycles de vie différents (news, produits, archives, blog, etc.).
Les sites e-commerce, les médias, les plateformes de contenu et les sites corporate multi-sections sont directement concernés. Pour un site vitrine de 30 pages, cette optimisation reste anecdotique.
- Structure hiérarchique = contrôle granulaire du crawl par section
- Structure plate = aucune différenciation possible basée sur l'architecture
- Le seuil critique se situe autour de 1000+ pages ou contenus multi-typologies
- L'exemple /news/ illustre l'optimisation de fréquence de crawl différenciée
- Sans hiérarchie, Google doit s'appuyer uniquement sur d'autres signaux (fraîcheur, popularité, etc.)
Avis d'un expert SEO
Cette déclaration est-elle cohérente avec les observations terrain ?
Absolument. Les tests empiriques confirment que Google crawle différemment selon la profondeur et la localisation des URLs. Les répertoires identifiés comme "news" ou "blog" bénéficient effectivement d'une fréquence de passage supérieure, à condition que le contenu y soit effectivement frais et régulièrement mis à jour.
Mais attention — et c'est là que ça coince. Créer un répertoire /news/ ne suffit pas : si vous y publiez un article par mois, Google ajustera sa fréquence à la baisse. La structure donne l'indice, mais c'est le comportement éditorial qui valide ou invalide cet indice.
Quelles nuances faut-il apporter à cette recommandation ?
Gary Illyes ne précise pas un point crucial : la hiérarchie doit rester logique et peu profonde. Une structure /categorie/sous-categorie/sous-sous-categorie/sous-sous-sous-categorie/page devient contre-productive. Au-delà de 3-4 niveaux de profondeur, vous diluez le crawl budget et compliquez l'indexation.
Autre limite : cette approche suppose que vos sections soient clairement définies. Si vous avez des contenus hybrides (un article de blog qui est aussi une actualité produit), la structuration devient plus délicate. [À vérifier] Google n'a jamais précisé comment il gère les contenus cross-sections dans ce contexte.
Dans quels cas cette règle ne s'applique-t-elle pas ?
Pour les sites de moins de 500 pages, l'impact reste marginal. La structure plate peut même être préférable si elle réduit la profondeur de crawl — un produit accessible en 1 clic plutôt qu'en 3 clics via une arborescence complexe.
Les sites monolingues à fort PageRank interne peuvent aussi se permettre une structure plate : si chaque page reçoit suffisamment de jus via le maillage, Googlebot les crawlera fréquemment quelle que soit leur position. Mais soyons clairs : c'est un cas de figure minoritaire.
Impact pratique et recommandations
Que faut-il faire concrètement sur un grand site ?
Auditez votre architecture actuelle. Listez vos typologies de contenu (actualités, produits, articles de fond, pages institutionnelles) et vérifiez si elles sont isolées dans des répertoires distincts. Si tout est mélangé au même niveau, vous laissez de l'optimisation sur la table.
Définissez une stratégie de répertoires cohérente : /news/ pour l'actualité mise à jour quotidiennement, /blog/ pour les contenus evergreen, /produits/ pour le catalogue, etc. Chaque répertoire doit correspondre à une réalité éditoriale et une fréquence de mise à jour homogène.
Comment vérifier que votre structure est efficace ?
Analysez les logs serveur ou Google Search Console pour identifier la fréquence de crawl par répertoire. Si /news/ est crawlé aussi rarement que /archives/, soit votre rythme de publication ne justifie pas cette section, soit Google n'a pas encore compris sa nature.
Utilisez les sitemaps XML différenciés : un sitemap pour /news/ avec une fréquence quotidienne, un autre pour les archives avec une fréquence mensuelle. Cela renforce les signaux structurels donnés par vos URLs.
Quelles erreurs éviter lors d'une refonte d'architecture ?
Ne créez pas une hiérarchie artificielle juste pour "faire joli". Si vos catégories n'ont pas de logique métier ou éditoriale forte, vous complexifiez l'arborescence sans gain. La structure doit refléter l'usage réel, pas un idéal théorique.
Évitez la sur-segmentation : 15 répertoires racine pour 200 pages totales n'a aucun sens. Concentrez-vous sur les grandes masses de contenu (100+ pages par section) qui justifient une séparation nette.
- Auditer l'architecture actuelle et identifier les typologies de contenu
- Créer des répertoires distincts pour chaque typologie éditoriale (/news/, /blog/, /produits/)
- Limiter la profondeur à 3-4 niveaux maximum
- Analyser les logs pour vérifier la fréquence de crawl par répertoire
- Utiliser des sitemaps XML différenciés avec des fréquences adaptées
- Éviter la sur-segmentation (trop de répertoires pour peu de pages)
- S'assurer que la structure URL reflète la réalité éditoriale (fréquence de mise à jour)
- Mettre en place des redirections 301 propres en cas de refonte
❓ Questions frequentes
Un site de 300 pages doit-il obligatoirement adopter une structure hiérarchique ?
Peut-on changer de structure sans perdre du trafic ?
Comment Google sait-il qu'un répertoire /news/ contient de l'actualité ?
Une structure plate peut-elle être plus performante dans certains cas ?
Faut-il créer un répertoire distinct pour chaque catégorie de produits ?
🎥 De la même vidéo 20
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 18/12/2023
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.