Declaration officielle
Autres déclarations de cette vidéo 20 ▾
- □ Comment Google indexe-t-il réellement le contenu des iframes ?
- □ Faut-il vraiment privilégier une structure hiérarchique pour les grands sites ?
- □ Bloquer le crawl via robots.txt : solution miracle contre les liens toxiques ?
- □ Faut-il traduire ses URLs pour améliorer son référencement international ?
- □ Pourquoi Googlebot ignore-t-il la balise meta prerender-status-code 404 dans les applications JavaScript ?
- □ Pourquoi les migrations de sites échouent-elles si souvent malgré une préparation SEO ?
- □ Les doubles slashes dans les URLs sont-ils un problème pour le SEO ?
- □ Pourquoi Google pénalise-t-il les vidéos hors du viewport et comment y remédier ?
- □ Comment transférer efficacement le classement de vos images vers de nouvelles URLs ?
- □ Faut-il vraiment s'inquiéter des erreurs 404 sur son site ?
- □ HTTP 200 sur une page 404 : soft 404 ou cloaking ?
- □ Faut-il forcer l'indexation de son fichier sitemap dans Google ?
- □ Faut-il s'inquiéter si Googlebot crawle vos endpoints API et génère des 404 ?
- □ L'accessibilité web est-elle vraiment un facteur de classement Google ou un écran de fumée ?
- □ L'achat de liens reste-t-il vraiment sanctionné par Google ?
- □ Faut-il encore signaler les mauvais backlinks à Google ?
- □ Pourquoi Google refuse-t-il l'idée d'une formule magique pour ranker ?
- □ Pourquoi Google affiche-t-il mal vos caractères spéciaux dans ses résultats ?
- □ Google Analytics et Search Console : pourquoi ces différences de données posent-elles problème ?
- □ Faut-il vraiment viser le SEO parfait ?
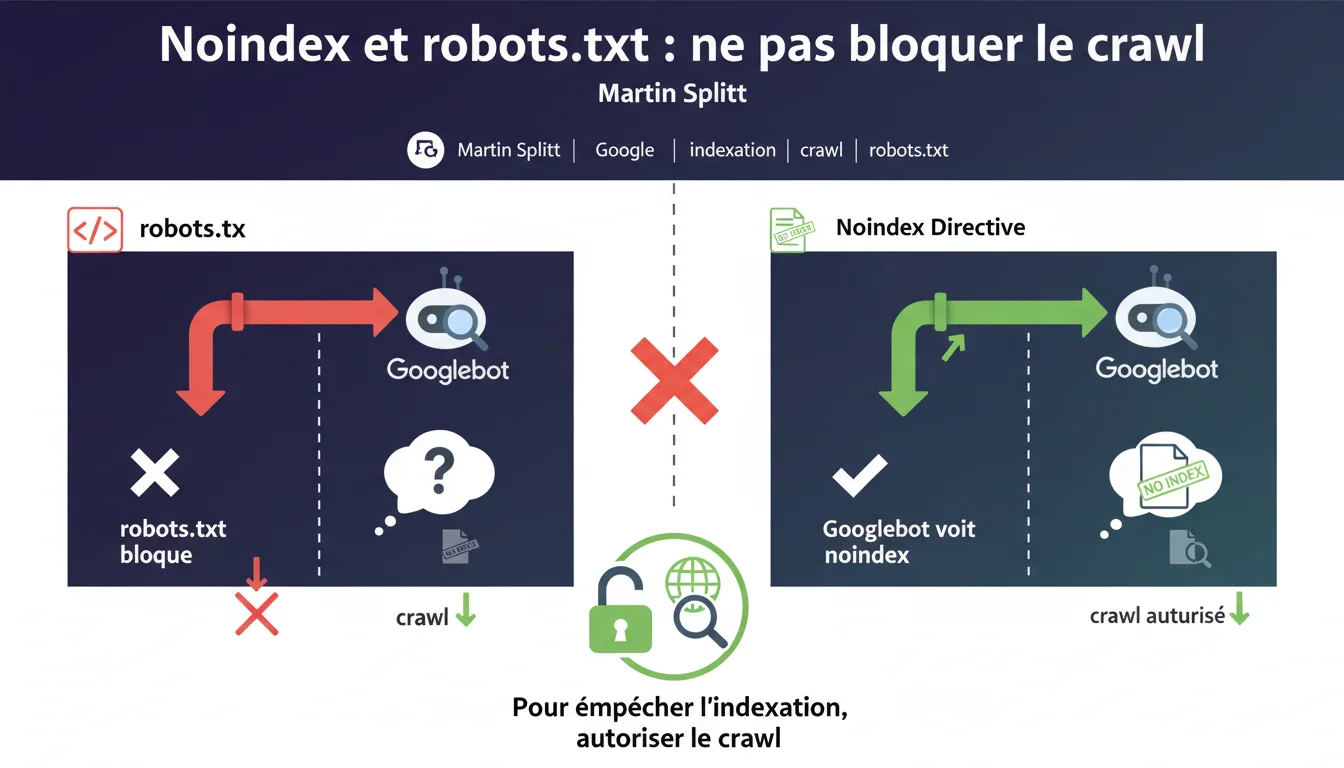
Si vous bloquez une URL dans robots.txt, Googlebot ne peut pas la crawler et donc jamais détecter la balise noindex présente sur cette page. Pour désindexer efficacement, il faut au contraire autoriser le crawl pour que Google puisse lire l'instruction noindex. C'est un piège technique courant qui produit l'effet inverse de celui recherché.
Ce qu'il faut comprendre
Quelle est l'erreur technique derrière ce problème ?
Le robots.txt intervient avant que Googlebot ne fasse la moindre requête HTTP vers votre serveur. C'est un filtre en amont qui dit « tu peux y aller » ou « tu passes ton chemin ».
Si vous bloquez une URL dans robots.txt, Googlebot ne charge jamais la page. Il ne voit donc jamais le code HTML, ni l'en-tête HTTP, ni la balise meta noindex que vous avez soigneusement placée. Résultat : l'URL peut rester indexée indéfiniment, avec un snippet vide ou générique, parce que Google n'a jamais reçu l'ordre de la retirer.
Pourquoi Google indexe-t-il des URLs bloquées par robots.txt ?
Parce que le robots.txt ne contrôle que le crawl, pas l'indexation. Google peut découvrir une URL via un lien externe, un sitemap, ou une mention quelque part sur le web.
Si cette URL est bloquée par robots.txt, Google peut décider de l'indexer quand même — sans contenu, juste l'URL et éventuellement un anchor text récupéré depuis les liens pointant vers elle. C'est particulièrement visible sur des pages sensibles (admin, staging, paramètres) qu'on croyait protégées.
Comment fonctionne réellement la directive noindex ?
La balise meta robots noindex (ou l'en-tête HTTP X-Robots-Tag) ne peut être lue que si Googlebot accède effectivement à la page. C'est une instruction située dans la réponse serveur.
Une fois lue, Google retire progressivement l'URL de son index. Mais cette lecture n'a lieu que si le crawl est autorisé. D'où la règle de base : pour désindexer proprement, laissez crawler puis bloquez après retrait de l'index si besoin.
- Robots.txt = contrôle du crawl, pas de l'indexation
- Noindex = instruction d'indexation, nécessite un crawl pour être vue
- Bloquer le crawl d'une page noindexée empêche Google de lire cette instruction
- Une URL bloquée par robots.txt peut quand même être indexée si Google la découvre ailleurs
- Pour désindexer : autoriser le crawl, attendre le retrait, puis bloquer si nécessaire
Avis d'un expert SEO
Cette déclaration est-elle cohérente avec les pratiques observées sur le terrain ?
Totalement. C'est même l'une des erreurs les plus fréquentes que je vois en audit technique. Des équipes qui veulent cacher des pages sensibles (environnements de dev, pages de test, contenus dupliqués) les bloquent dans robots.txt en pensant qu'elles ne seront jamais indexées.
Sauf qu'elles le sont — avec un snippet qui indique « Aucune information disponible pour cette page ». Et elles restent là, parfois des mois, parce que Google n'a jamais pu lire la directive noindex qu'on avait pourtant mise en place. Le robots.txt devient alors un verrou contre la désindexation, pas une protection.
Faut-il toujours privilégier noindex sur robots.txt pour contrôler l'indexation ?
Pas systématiquement. Si vous avez des milliers de pages à faible valeur ajoutée (facettes de filtres, résultats de recherche interne, paginations infinies), le noindex va forcer Googlebot à crawler toutes ces URLs pour lire l'instruction.
Résultat : vous consommez du crawl budget pour rien. Dans ce cas, robots.txt peut être plus efficace — à condition d'accepter qu'une partie de ces URLs reste potentiellement indexée si elles ont été découvertes avant le blocage. [A vérifier] : Google affirme que le crawl budget n'est pas un problème pour la majorité des sites, mais sur des sites à forte volumétrie, l'observation terrain montre le contraire.
Que faire si une page est déjà indexée et bloquée par robots.txt ?
C'est le cas le plus délicat. Vous devez retirer temporairement le blocage robots.txt, ajouter une balise noindex, puis attendre que Google crawle la page et la retire de l'index.
Une fois désindexée (vérifiez via Search Console ou un site:), vous pouvez remettre le blocage robots.txt si vous ne voulez vraiment plus qu'elle soit crawlée. Mais gardez en tête qu'un lien externe découvert plus tard pourrait la réindexer — sans contenu cette fois, juste l'URL.
Impact pratique et recommandations
Que faut-il faire concrètement pour gérer noindex et robots.txt ?
D'abord, auditer les URLs bloquées dans robots.txt et vérifier si elles apparaissent dans l'index Google (requête site: ou Search Console). Si c'est le cas, vous avez un problème de configuration à corriger.
Ensuite, établir une règle claire : pour toute page que vous voulez désindexer, vous devez autoriser le crawl le temps que Google lise la balise noindex. Ce n'est qu'après retrait confirmé que vous pouvez éventuellement bloquer le crawl — si ça a vraiment du sens.
Pour les pages sensibles (admin, staging), la vraie protection c'est l'authentification HTTP ou le blocage IP, pas robots.txt. Robots.txt est un fichier public que n'importe qui peut lire — y compris pour découvrir des URLs que vous préfériez garder discrètes.
Quelles erreurs éviter absolument ?
Ne jamais se dire « je bloque tout dans robots.txt, comme ça rien ne sera indexé ». C'est faux. Google peut indexer sans crawler, et il le fera si l'URL est mentionnée quelque part.
Évitez aussi de basculer constamment entre robots.txt et noindex sur les mêmes URLs — ça crée de la confusion dans le traitement de Google et rallonge les délais de désindexation. Choisissez une stratégie et tenez-vous-y.
Comment vérifier que votre configuration est correcte ?
- Extraire toutes les URLs bloquées dans robots.txt via un crawler (Screaming Frog, Oncrawl)
- Croiser avec un export Search Console (Couverture) pour voir si certaines sont indexées
- Pour chaque URL indexée + bloquée, retirer temporairement le blocage et ajouter noindex
- Vérifier après 2-4 semaines que l'URL a bien disparu de l'index (site: ou GSC)
- Remettre robots.txt uniquement si nécessaire (souvent, noindex suffit)
- Tester l'inspection d'URL dans GSC pour confirmer que Google voit bien la directive noindex
- Documenter la logique (quelles sections en noindex, lesquelles en robots.txt, pourquoi)
❓ Questions frequentes
Peut-on utiliser robots.txt pour empêcher l'indexation ?
Si une page est déjà indexée et bloquée par robots.txt, comment la désindexer ?
Noindex en meta ou en HTTP header : y a-t-il une différence face à robots.txt ?
Faut-il toujours laisser crawler les pages noindex pour le crawl budget ?
Google peut-il ignorer robots.txt et crawler quand même ?
🎥 De la même vidéo 20
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 18/12/2023
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.