Declaration officielle
Ce qu'il faut comprendre
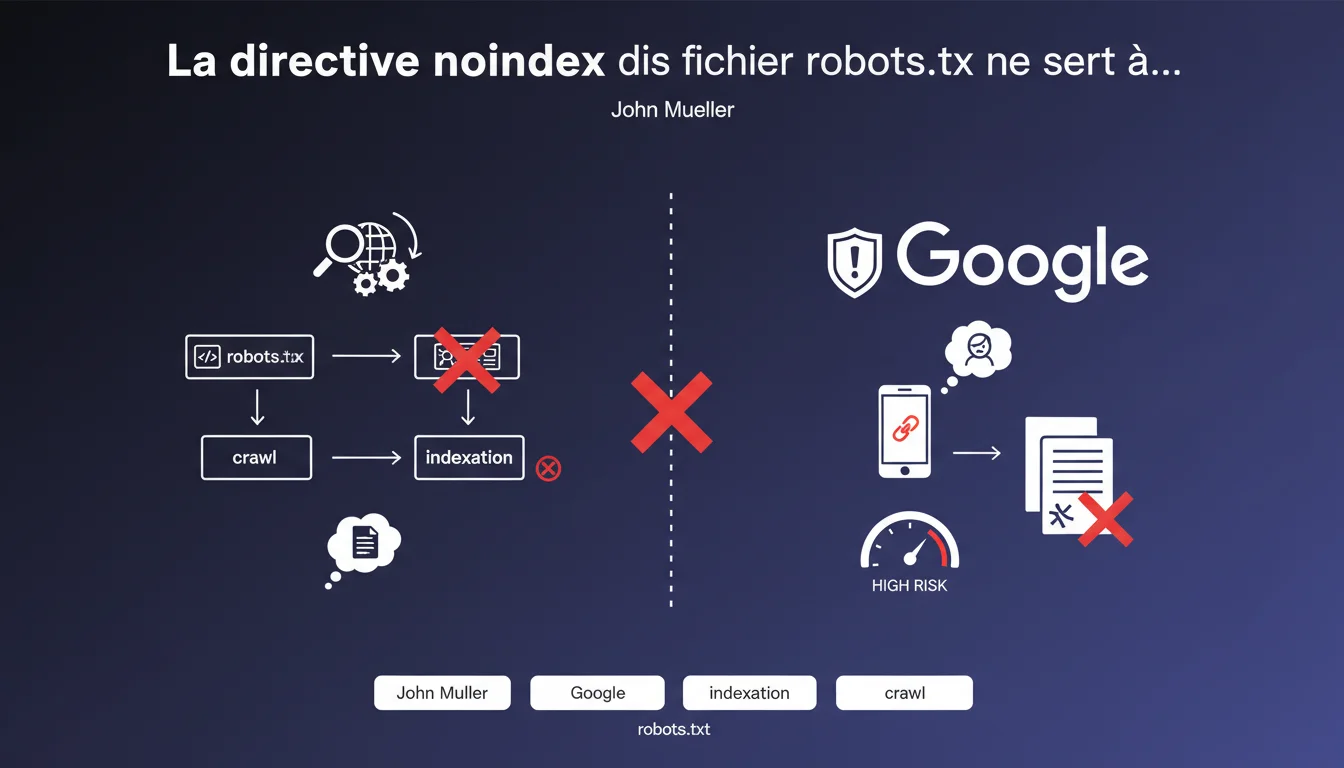
La directive noindex dans le fichier robots.txt est une pratique qui a circulé dans la communauté SEO pendant des années. L'idée était séduisante : bloquer simultanément le crawl et l'indexation des pages via un seul fichier de configuration.
Cependant, Google a officiellement confirmé que cette directive n'est pas prise en compte par son moteur de recherche. L'entreprise a même révélé avoir envisagé de la supporter, mais y a finalement renoncé pour des raisons de sécurité et d'expérience utilisateur.
Le principal risque identifié concerne les erreurs de manipulation accidentelles. De nombreux propriétaires de sites copient-collent des fichiers robots.txt sans en comprendre toutes les implications, ce qui pourrait entraîner la désindexation involontaire de sections critiques de leur site.
- La directive noindex n'est reconnue que dans les balises meta HTML ou les en-têtes HTTP X-Robots-Tag
- Le fichier robots.txt contrôle uniquement le crawl, pas l'indexation
- Bloquer le crawl avec robots.txt peut empêcher Google de voir une balise noindex, créant un effet inverse
- Cette confusion persiste car certains anciens outils SEO mentionnaient encore cette pratique
Avis d'un expert SEO
Cette position de Google est parfaitement cohérente avec l'architecture technique de leur système d'indexation. Le fichier robots.txt est lu par le crawler (Googlebot) avant même d'accéder au contenu de la page, tandis que les directives d'indexation nécessitent l'analyse du contenu lui-même.
Ce qui intrigue la communauté SEO, c'est que cette directive apparaissait sur le site personnel d'un représentant officiel de Google. Cela illustre un décalage entre les anciennes pratiques et les standards actuels. Il peut s'agir d'un vestige historique, d'une configuration héritée, ou même d'un test technique sans impact réel.
La vraie nuance à comprendre : bloquer une URL dans robots.txt n'empêche pas son indexation. Google peut indexer une page sans la crawler, notamment si elle reçoit des backlinks. Pour vraiment empêcher l'indexation, il faut que Google puisse accéder à la page et lire la directive noindex.
Impact pratique et recommandations
- Auditez votre fichier robots.txt actuel : supprimez toute directive noindex qui s'y trouverait, elle ne sert à rien
- Vérifiez que vos pages avec balise noindex sont accessibles au crawl : elles ne doivent pas être bloquées dans robots.txt
- Utilisez la balise meta robots noindex dans le HTML de vos pages pour empêcher leur indexation de manière fiable
- Pour les contenus dynamiques, privilégiez l'en-tête HTTP X-Robots-Tag: noindex plutôt que robots.txt
- Documentez votre stratégie d'indexation pour éviter les erreurs lors de modifications futures du site
- Testez vos directives avec Google Search Console pour vérifier que Google interprète correctement vos instructions
- Formez vos équipes techniques sur la différence entre contrôle du crawl (robots.txt) et contrôle de l'indexation (meta robots)
La gestion fine du crawl budget et des directives d'indexation fait partie des optimisations techniques avancées en SEO. Ces configurations demandent une expertise approfondie pour éviter des erreurs aux conséquences parfois dramatiques sur la visibilité.
Si votre site présente une architecture complexe avec des milliers de pages, ou si vous hésitez sur la meilleure approche pour gérer votre indexation, l'accompagnement d'une agence SEO spécialisée peut s'avérer précieux pour sécuriser votre stratégie et éviter les pièges courants.
💬 Commentaires (0)
Soyez le premier à commenter.