Declaration officielle
Autres déclarations de cette vidéo 8 ▾
- □ Googlebot stocke-t-il les cookies lors de l'exploration de votre site ?
- □ Pourquoi les robots d'exploration ignorent-ils systématiquement vos cookies ?
- □ Le dynamic rendering avec parité de contenu est-il vraiment sans risque pour l'indexation ?
- □ Pourquoi tester votre site avec un émulateur de user agent ne suffit-il pas à détecter les problèmes de crawl ?
- □ Pourquoi tester votre site avec un crawler est-il indispensable pour le SEO ?
- □ Pourquoi Google refuse-t-il la pagination basée sur les cookies ?
- □ Les cookies bloquent-ils vraiment l'accès des bots à votre contenu ?
- □ Les sites qui dépendent des cookies sont-ils invisibles pour Googlebot ?
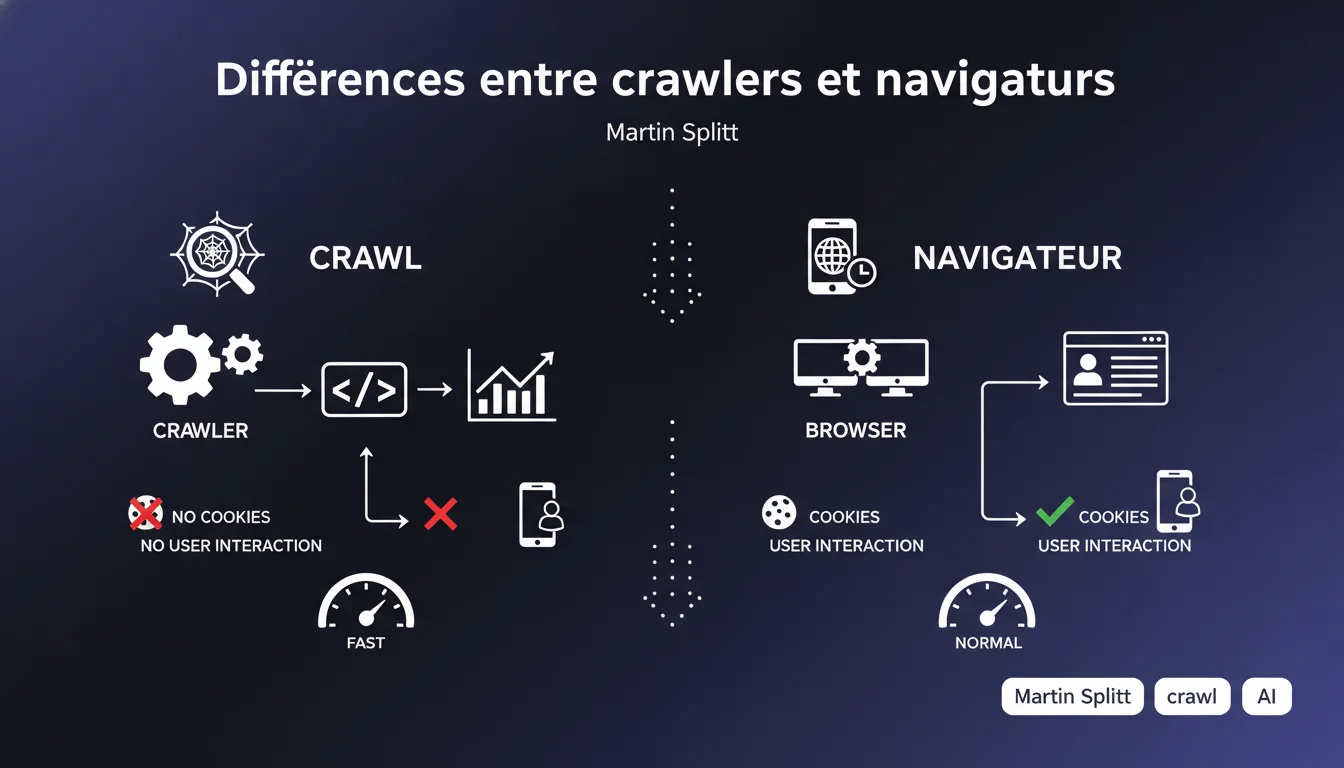
Google confirme que ses crawlers ne fonctionnent pas exactement comme des navigateurs classiques, même en utilisant le même user agent. La différence majeure : les crawlers ne gèrent pas les cookies, ce qui peut créer des expériences utilisateur complètement différentes de celles observées lors du rendu côté serveur. Cette nuance technique a des implications directes sur la façon dont votre contenu peut être perçu par Googlebot.
Ce qu'il faut comprendre
Pourquoi Google précise-t-il cette distinction maintenant ?
Martin Splitt insiste sur un point technique que beaucoup de SEO négligent : user agent identique ne signifie pas comportement identique. Les développeurs supposent souvent qu'un crawler avec le même user agent que Chrome reproduira fidèlement l'expérience d'un navigateur classique.
La réalité est plus nuancée. Les crawlers comme Googlebot ne supportent pas certaines fonctionnalités natives des navigateurs modernes. Les cookies en sont l'exemple le plus flagrant — et potentiellement le plus problématique pour le rendu des pages.
Quelles fonctionnalités spécifiques sont concernées ?
Google mentionne explicitement les cookies, mais ne dresse pas une liste exhaustive. C'est typique de leur communication : on vous donne un indice, à vous de creuser pour identifier les autres gaps potentiels.
Au-delà des cookies, on peut raisonnablement suspecter d'autres limitations : gestion du stockage local, interactions JavaScript complexes qui dépendent de sessions persistantes, ou encore certaines APIs web modernes. Mais Google reste flou sur le périmètre exact.
Comment cela affecte-t-il le rendu des pages ?
Une page qui adapte son contenu selon la présence ou l'absence de cookies peut présenter deux visages radicalement différents : celui vu par l'utilisateur avec cookies, celui vu par Googlebot sans. Si votre architecture repose sur des cookies pour charger du contenu critique, vous êtes dans la zone rouge.
Les expériences personnalisées sont particulièrement vulnérables. Une homepage qui affiche un contenu générique pour les nouveaux visiteurs (sans cookies) et du contenu enrichi pour les visiteurs connus pourrait involontairement cacher du contenu important à Google.
- Les crawlers ne gèrent pas les cookies, même avec un user agent Chrome identique
- Cette limitation crée des expériences différentes entre utilisateurs réels et Googlebot
- Les sites avec logique de contenu dépendante des cookies doivent auditer leur rendu côté crawler
- Google ne fournit pas de liste exhaustive des fonctionnalités non supportées
Avis d'un expert SEO
Cette déclaration est-elle cohérente avec les observations terrain ?
Absolument. Les tests avec Google Search Console et l'outil d'inspection d'URL montrent régulièrement des écarts entre le rendu utilisateur et le rendu Googlebot. Les cookies sont souvent le coupable — mais pas toujours identifié immédiatement.
Ce qui est frustrant, c'est que Google aurait pu documenter cette limitation de façon exhaustive il y a des années. Au lieu de ça, on découvre ces nuances au fil de déclarations éparses. Pour un SEO qui debug un problème d'indexation, cette opacité coûte du temps.
Quelles nuances faut-il apporter à cette affirmation ?
Google parle de "certaines fonctionnalités" sans préciser lesquelles au-delà des cookies. [A vérifier] sur votre propre infrastructure : est-ce que le localStorage, le sessionStorage, ou certaines APIs JavaScript sont également ignorées par Googlebot ?
La réalité : vous devez tester. L'outil "Tester l'URL en direct" dans Search Console est votre allié, mais il ne capture pas tout. Comparez systématiquement avec des tests en environnement anonyme (navigation privée, cookies désactivés).
Dans quels cas cette règle crée-t-elle des problèmes réels ?
Les sites e-commerce avec personnalisation avancée sont en première ligne. Si vous affichez des recommandations produits uniquement pour les visiteurs avec historique (cookies), Googlebot voit une page vide ou appauvrie.
Même chose pour les sites avec paywalls : si votre logique de blocage repose sur des cookies pour identifier les abonnés, assurez-vous que Googlebot accède bien à la version publique prévue, pas à une version vide ou cassée.
Impact pratique et recommandations
Que faut-il faire concrètement pour éviter les pièges ?
Première étape : auditer toutes les parties de votre site qui utilisent des cookies ou du stockage client pour afficher du contenu. Identifiez les pages où la logique JavaScript dépend de ces mécanismes.
Testez systématiquement ces pages dans Search Console avec l'outil d'inspection d'URL. Comparez le rendu avec ce que vous voyez dans un navigateur en mode privé, cookies désactivés. Si l'écart est significatif, vous avez un problème.
Quelles erreurs éviter absolument ?
Ne partez jamais du principe que "user agent Chrome = rendu Chrome". Ce raccourci mental coûte cher. Googlebot n'est pas un navigateur standard, c'est un crawler avec des contraintes spécifiques.
Évitez de cacher du contenu critique derrière une logique de cookies. Si vous devez personnaliser, faites-le de façon additive : affichez une version de base accessible sans cookies, enrichissez ensuite pour les visiteurs connus.
Comment s'assurer que votre site est conforme ?
Mettez en place un monitoring régulier du rendu Googlebot via Search Console. Automatisez des captures d'écran comparées entre user réel et crawler. Si vous utilisez un CMS ou un framework JavaScript moderne, documentez les dépendances aux cookies.
Côté développement, imposez une règle : tout contenu important doit être accessible sans dépendance stricte aux cookies. Les cookies peuvent enrichir l'expérience, mais ne doivent jamais bloquer l'accès au contenu principal.
- Auditer les pages avec logique de contenu dépendante des cookies
- Tester le rendu dans Search Console ("Tester l'URL en direct")
- Comparer avec un navigateur en mode privé, cookies désactivés
- Identifier les écarts de contenu entre rendu user et rendu Googlebot
- Refactoriser les pages critiques pour afficher le contenu principal sans cookies
- Mettre en place un monitoring régulier du rendu côté crawler
- Former les équipes dev sur les limitations des crawlers (pas des navigateurs standards)
❓ Questions frequentes
Googlebot gère-t-il le localStorage et le sessionStorage ?
Comment tester si mon site affiche du contenu différent à Googlebot ?
Les sites e-commerce avec recommandations personnalisées sont-ils pénalisés ?
Faut-il désactiver toutes les fonctionnalités basées sur les cookies ?
Cette limitation concerne-t-elle aussi les autres moteurs de recherche ?
🎥 De la même vidéo 8
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 15/11/2022
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.