Declaration officielle
Autres déclarations de cette vidéo 8 ▾
- □ Googlebot stocke-t-il les cookies lors de l'exploration de votre site ?
- □ Pourquoi les robots d'exploration ignorent-ils systématiquement vos cookies ?
- □ Le dynamic rendering avec parité de contenu est-il vraiment sans risque pour l'indexation ?
- □ Les crawlers Google se comportent-ils vraiment comme de vrais navigateurs ?
- □ Pourquoi tester votre site avec un crawler est-il indispensable pour le SEO ?
- □ Pourquoi Google refuse-t-il la pagination basée sur les cookies ?
- □ Les cookies bloquent-ils vraiment l'accès des bots à votre contenu ?
- □ Les sites qui dépendent des cookies sont-ils invisibles pour Googlebot ?
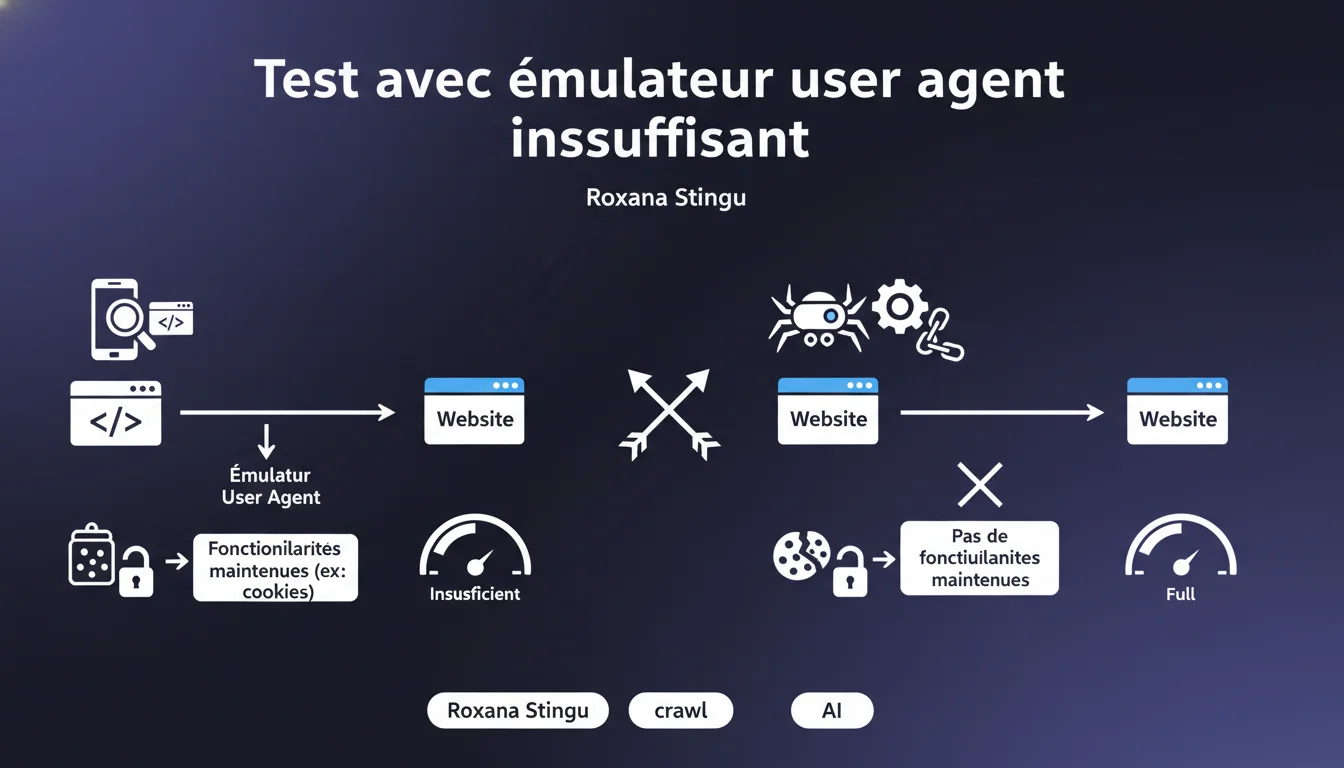
Google rappelle qu'émuler un user agent de bot dans un navigateur classique ne reproduit pas fidèlement le comportement d'un vrai crawler. Les navigateurs conservent des fonctionnalités comme les cookies, le cache ou le JavaScript complet que Googlebot n'utilise pas forcément de la même manière. Résultat : vous ratez des problèmes qui n'apparaissent qu'en conditions réelles.
Ce qu'il faut comprendre
Quelle différence entre un navigateur avec user agent modifié et un vrai crawler ?
Quand vous changez le user agent dans Chrome DevTools pour simuler Googlebot, vous ne faites que modifier l'en-tête HTTP User-Agent. Le reste du moteur de rendu reste intact : cookies actifs, cache navigateur, stockage local, capacités JavaScript complètes.
Or Googlebot ne fonctionne pas comme ça. Il ne gère pas les cookies de session, ne conserve pas de cache entre deux visites de pages différentes, et son environnement d'exécution JavaScript — bien que basé sur Chromium — a ses propres limites et comportements. Certains scripts qui tournent sans broncher dans votre navigateur peuvent planter ou ne pas s'exécuter du tout côté bot.
Pourquoi Google fait cette mise en garde maintenant ?
Parce que l'émulation user agent est devenue un réflexe chez beaucoup de SEO. C'est rapide, accessible, et ça donne l'impression de voir "comme Googlebot". Sauf que cette fausse impression rassure à tort.
Des sites entiers passent des audits sur cette base, alors que des redirections conditionnelles, des contenus servis différemment selon les cookies, ou des erreurs JavaScript silencieuses ne sont jamais détectés. Google a probablement vu passer trop de tickets Support où les webmasters jurent que "ça marche dans mon navigateur avec le user agent Googlebot".
Quels problèmes concrets passent sous le radar ?
- Redirections basées sur les cookies : Si votre site redirige les utilisateurs sans cookie vers une page d'accueil ou un onboarding, Googlebot ne verra jamais le contenu réel — votre navigateur si.
- Contenu conditionnel : Du contenu affiché uniquement aux visiteurs identifiés, stocké en localStorage, ou dépendant d'un état de session.
- Scripts qui échouent en silence : Un JS qui fonctionne dans Chrome 120 mais plante dans l'environnement Googlebot basé sur une version légèrement différente ou bridée.
- Caching agressif : Votre navigateur peut servir une version en cache qui masque un problème de génération serveur.
- Lazy loading mal implémenté : Certains frameworks détectent les "vrais" bots autrement que par le user agent — votre émulation rate ce cas.
Avis d'un expert SEO
Cette déclaration est-elle vraiment une surprise ?
Non. Tout SEO technique un peu expérimenté sait que changer le user agent ne reproduit pas l'environnement complet d'un crawler. Mais soyons honnêtes : combien d'audits sont encore faits uniquement avec DevTools et une extension de user agent switcher ?
Google ne dit rien de neuf ici — c'est un rappel utile pour ceux qui prennent des raccourcis. Le vrai sujet, c'est que Google ne fournit toujours pas d'outil officiel simple pour tester son site exactement comme Googlebot le voit, en dehors de la Search Console (outil d'inspection d'URL) qui ne couvre qu'une URL à la fois et reste une boîte noire.
Quelles nuances faut-il apporter à ce conseil ?
L'émulation user agent garde une utilité pour des vérifications rapides : vérifier qu'un contenu n'est pas caché en CSS pour un bot, tester une version mobile/desktop, repérer une redirection évidente. C'est un premier filtre, pas une validation finale.
Le vrai problème se situe ailleurs : trop de SEO s'arrêtent là. Ils ne croisent pas avec les logs serveur, ne regardent pas le rendu réel dans Search Console, ne testent pas avec des crawlers tiers (Screaming Frog, OnCrawl, Botify) qui eux aussi ont leurs limites mais s'approchent mieux du comportement réel.
Et c'est là que ça coince — Google dit "l'émulateur ne suffit pas", mais ne dit pas explicitement ce qu'il faut faire à la place. [À vérifier] : jusqu'où les tests via l'outil d'inspection d'URL de la Search Console sont-ils fiables pour détecter tous les cas limites ? Google ne documente pas précisément les différences entre cet outil et le crawl de production.
Dans quels cas cette règle pose-t-elle le plus de problèmes ?
Les sites à forte personnalisation (e-commerce, médias, plateformes SaaS) sont les plus exposés. Ils servent du contenu différent selon le profil utilisateur, l'historique de navigation, les A/B tests. Un émulateur user agent ne détectera aucun de ces cas.
Idem pour les Single Page Applications (SPA) modernes : le rendu côté client peut foirer de mille façons invisibles dans un navigateur classique mais fatales pour un bot. Si votre framework JS attend un cookie ou un token pour hydrater le DOM, Googlebot verra du vide.
Impact pratique et recommandations
Que faut-il faire concrètement pour tester comme Googlebot ?
Première étape : utiliser l'outil d'inspection d'URL de la Search Console. C'est l'outil le plus proche du crawl réel de Google, même s'il n'est pas parfait. Il montre le rendu HTML final, les ressources bloquées, les erreurs JavaScript critiques.
Deuxième étape : analyser vos logs serveur. Regardez quelles URLs Googlebot demande réellement, avec quels codes de retour, quelles redirections, quels temps de réponse. Comparez avec ce que vous voyez dans un navigateur. Les écarts révèlent les pièges.
Troisième étape : crawler votre site avec un outil tiers sérieux configuré pour désactiver les cookies, limiter le JavaScript, simuler un environnement dégradé. Screaming Frog, Sitebulb, OnCrawl ou Botify selon votre budget. Croisez les résultats avec la Search Console.
Quelles erreurs éviter absolument ?
- Ne jamais valider un site uniquement avec un user agent switcher dans Chrome/Firefox.
- Ne pas ignorer les différences entre le rendu Search Console et ce que vous voyez en navigateur — c'est un signal d'alarme.
- Ne pas tester uniquement la homepage ou quelques pages clés — les problèmes de cookies/session apparaissent souvent en profondeur (fiches produit, articles).
- Ne pas oublier de tester en mode navigation privée ET sans cookies pour reproduire l'absence d'état de Googlebot.
- Ne pas se fier aux outils qui promettent "un test 100% comme Google" — aucun outil tiers ne peut parfaitement répliquer l'environnement interne de Google.
Comment mettre en place un processus de test fiable ?
Intégrez plusieurs couches de validation dans votre workflow. Avant chaque déploiement majeur : test user agent (premier filtre rapide), inspection d'URL Search Console (validation Google), crawl outil tiers (détection d'anomalies à l'échelle), analyse logs post-déploiement (vérification réelle).
Documentez les écarts observés entre navigateur et bot pour chaque type de contenu ou fonctionnalité. Créez une checklist spécifique à votre stack technique : si vous utilisez React/Vue/Angular, si vous avez un paywall, si vous servez du contenu personnalisé.
❓ Questions frequentes
L'outil d'inspection d'URL de la Search Console reproduit-il exactement le crawl de Googlebot ?
Les crawlers tiers comme Screaming Frog voient-ils la même chose que Googlebot ?
Pourquoi un site peut-il fonctionner parfaitement dans mon navigateur avec user agent Googlebot mais poser problème en crawl réel ?
Faut-il désactiver tous les cookies sur mon site pour être sûr que Googlebot accède au contenu ?
Comment savoir si un script JavaScript plante silencieusement pour Googlebot mais pas dans mon navigateur ?
🎥 De la même vidéo 8
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 15/11/2022
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.