Declaration officielle
Autres déclarations de cette vidéo 8 ▾
- □ Googlebot stocke-t-il les cookies lors de l'exploration de votre site ?
- □ Pourquoi les robots d'exploration ignorent-ils systématiquement vos cookies ?
- □ Le dynamic rendering avec parité de contenu est-il vraiment sans risque pour l'indexation ?
- □ Les crawlers Google se comportent-ils vraiment comme de vrais navigateurs ?
- □ Pourquoi tester votre site avec un émulateur de user agent ne suffit-il pas à détecter les problèmes de crawl ?
- □ Pourquoi Google refuse-t-il la pagination basée sur les cookies ?
- □ Les cookies bloquent-ils vraiment l'accès des bots à votre contenu ?
- □ Les sites qui dépendent des cookies sont-ils invisibles pour Googlebot ?
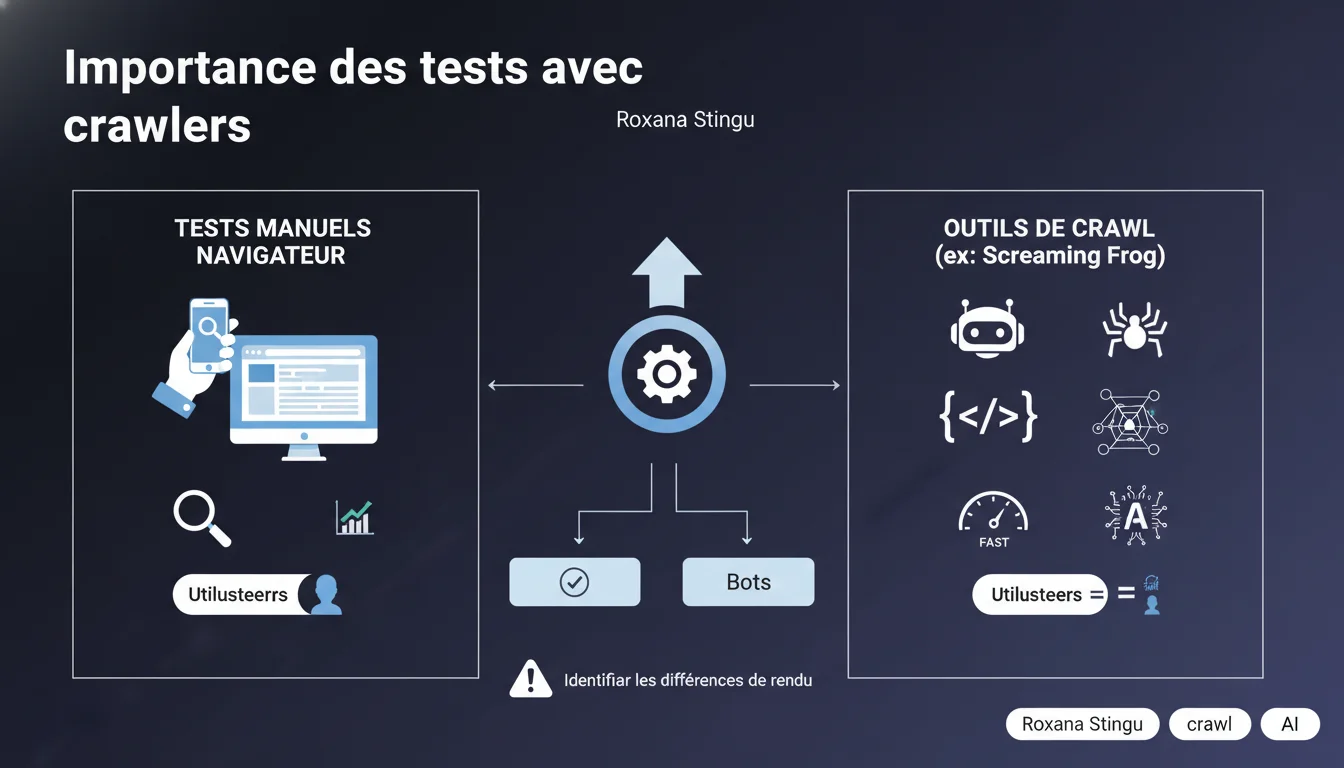
Google rappelle que les tests manuels dans un navigateur ne suffisent pas. Les crawlers comme Screaming Frog révèlent les différences de rendu entre bots et utilisateurs — des écarts qui peuvent impacter directement votre indexation et votre positionnement.
Ce qu'il faut comprendre
Pourquoi un navigateur ne suffit-il pas pour diagnostiquer les problèmes SEO ?
Votre navigateur charge JavaScript, CSS, ressources tierces — bref, tout ce qui compose l'expérience utilisateur finale. Le problème ? Googlebot ne se comporte pas exactement comme Chrome. Il a ses propres règles de timeout, de parsing, d'exécution JS.
Résultat : ce que vous voyez en navigation humaine ne correspond pas toujours à ce que Google crawle et indexe. Certains contenus peuvent être invisibles pour le bot, d'autres mal interprétés. Tester uniquement avec un navigateur, c'est se priver d'une partie critique du diagnostic.
Quels écarts de rendu peuvent passer inaperçus sans crawler ?
Un crawler comme Screaming Frog simule le comportement d'un bot : il suit les liens, analyse le DOM rendu, détecte les redirections, les erreurs HTTP, les balises meta. Concrètement, il repère ce qu'un test manuel rate systématiquement.
Les cas classiques ? Un contenu chargé en AJAX qui n'apparaît pas dans le HTML source, une redirection JavaScript invisible pour le bot, des ressources bloquées par robots.txt qui cassent le rendu. Sans crawler, vous passez à côté de ces problèmes — et Google aussi, mais dans l'autre sens.
Quelle méthodologie de test adopter ?
La démarche ne se limite pas à lancer un crawl et attendre. Il faut comparer : le HTML brut, le rendu côté serveur, le rendu après JavaScript. Identifier où les divergences apparaissent.
- Crawlez votre site avec un outil qui simule Googlebot (Screaming Frog, OnCrawl, Botify)
- Comparez le rendu bot vs navigateur — notamment pour les pages stratégiques
- Testez les URLs problématiques avec Google Search Console (outil d'inspection d'URL)
- Vérifiez les ressources bloquées qui pourraient empêcher le rendu complet
- Automatisez ces tests dans votre workflow de déploiement pour éviter les régressions
Avis d'un expert SEO
Cette recommandation est-elle vraiment suivie par les professionnels SEO ?
Soyons honnêtes : oui, par les aguerris. Mais une large partie des sites — y compris des sites corporate de taille moyenne — ne testent jamais avec un crawler. Ils se fient aux tests manuels, aux validateurs HTML, au meilleur des cas à Lighthouse.
Le problème, c'est que ces outils ne révèlent pas les divergences de traitement entre bot et utilisateur. Et c'est précisément ce que Google pointe ici. Roxana Stingu ne découvre pas l'eau chaude — elle rappelle une base que beaucoup négligent encore.
Quelles nuances faut-il apporter à cette déclaration ?
Tous les crawlers ne se valent pas. Screaming Frog est excellent pour auditer la structure, les balises, les redirections. Mais il a des limites sur le rendu JavaScript complexe — là où des outils comme Botify ou OnCrawl vont plus loin en simulant un navigateur headless complet.
Autre nuance : Google lui-même évolue. Son crawler JavaScript s'améliore, mais reste soumis à des contraintes de temps et de ressources. Ce qu'il indexe aujourd'hui n'est pas forcément ce qu'il indexera demain si votre JS devient trop lourd. [A vérifier] régulièrement, donc — pas une fois tous les 18 mois.
Dans quels cas cette règle ne s'applique-t-elle pas strictement ?
Si votre site est 100% statique, HTML pur, sans JS côté client, les écarts bot/navigateur sont quasi inexistants. Mais combien de sites répondent encore à ce profil en 2025 ? Même un WordPress basique charge des scripts tiers.
Impact pratique et recommandations
Que faut-il faire concrètement pour aligner bot et utilisateur ?
D'abord, identifier les pages stratégiques : celles qui génèrent du trafic organique, celles qui convertissent, celles qui structurent votre maillage. Ce sont elles qu'il faut tester en priorité.
Ensuite, comparer le rendu : lancez un crawl, extrayez le HTML brut, comparez avec ce que vous voyez dans le navigateur et avec ce que Google Search Console affiche dans l'outil d'inspection. Les écarts vous montrent où agir.
Quelles erreurs éviter lors de ces tests ?
Première erreur : crawler une fois, puis oublier. Les sites évoluent — un déploiement, une MAJ de thème, un nouveau script tiers, et tout peut se casser côté bot. Intégrez le crawl dans votre cycle de QA.
Deuxième erreur : ne tester qu'en mode "navigateur" dans Screaming Frog. Utilisez aussi le mode rendu JavaScript pour voir ce que Googlebot voit réellement après exécution des scripts. Les deux vues sont complémentaires.
Troisième erreur : ignorer les ressources bloquées. Si votre CSS ou JS critique est bloqué par robots.txt, le rendu sera cassé pour le bot — même si tout fonctionne parfaitement pour l'utilisateur.
Comment vérifier que votre site est conforme ?
- Crawlez votre site avec Screaming Frog (mode JavaScript activé)
- Comparez le contenu extrait par le crawler avec ce qu'affiche Google Search Console (inspection d'URL)
- Vérifiez que les balises title, meta description, H1 sont identiques bot vs navigateur
- Testez les URLs clés avec l'outil Mobile-Friendly Test pour voir le rendu mobile
- Auditez les ressources bloquées dans robots.txt — rien de critique ne doit être interdit
- Automatisez ces vérifications dans votre pipeline CI/CD pour détecter les régressions avant mise en prod
- Documentez les écarts acceptables vs ceux qui nécessitent correction immédiate
❓ Questions frequentes
Screaming Frog est-il le seul outil capable de détecter les différences bot/utilisateur ?
Google Search Console suffit-il pour diagnostiquer ces problèmes ?
Faut-il crawler son site à chaque modification ?
Les différences de rendu affectent-elles directement le ranking ?
Quels signaux indiquent un problème de rendu bot vs utilisateur ?
🎥 De la même vidéo 8
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 15/11/2022
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.