Declaration officielle
Autres déclarations de cette vidéo 8 ▾
- □ Pourquoi les robots d'exploration ignorent-ils systématiquement vos cookies ?
- □ Le dynamic rendering avec parité de contenu est-il vraiment sans risque pour l'indexation ?
- □ Les crawlers Google se comportent-ils vraiment comme de vrais navigateurs ?
- □ Pourquoi tester votre site avec un émulateur de user agent ne suffit-il pas à détecter les problèmes de crawl ?
- □ Pourquoi tester votre site avec un crawler est-il indispensable pour le SEO ?
- □ Pourquoi Google refuse-t-il la pagination basée sur les cookies ?
- □ Les cookies bloquent-ils vraiment l'accès des bots à votre contenu ?
- □ Les sites qui dépendent des cookies sont-ils invisibles pour Googlebot ?
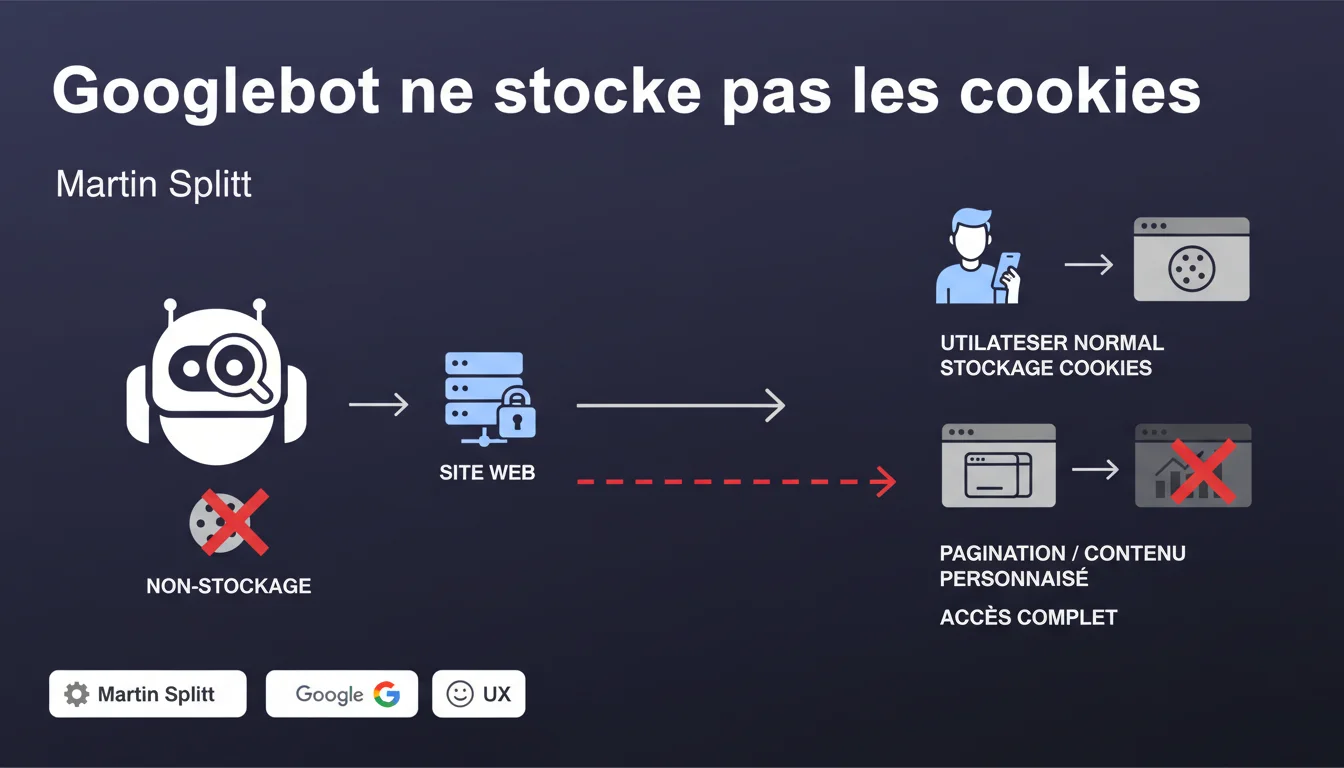
Googlebot ne stocke aucun cookie pendant le crawl. Conséquence directe : toute pagination, personnalisation ou gestion de contenu reposant sur des cookies reste invisible au bot. Si votre architecture dépend de sessions cookies, Google ne verra qu'une fraction du site.
Ce qu'il faut comprendre
Pourquoi Googlebot refuse-t-il de stocker les cookies ?
Google a conçu son bot pour explorer le web de manière stateless — sans mémoire de session. Chaque requête HTTP est traitée de façon isolée, comme si c'était la première visite. Cette approche simplifie le crawl à grande échelle et évite les biais liés aux sessions utilisateur.
Concrètement, si votre site utilise des cookies pour gérer l'affichage de produits, débloquer du contenu premium ou paginer des listes, Googlebot ne verra que l'état par défaut — celui accessible sans cookie. Le reste disparaît purement et simplement de son radar.
Quelles fonctionnalités sont concernées par cette limitation ?
Les sites e-commerce utilisant des sessions panier pour afficher des recommandations, les plateformes de contenu gérant l'accès via cookies d'authentification, ou encore les CMS qui conditionnent la pagination au stockage de préférences utilisateur — tous ces mécanismes sont aveugles pour Googlebot.
Les popups de consentement RGPD qui bloquent l'accès au contenu tant qu'un cookie n'est pas accepté posent un problème similaire. Si le contenu principal est masqué derrière ce mur, Google n'y accède pas.
Cette déclaration invalide-t-elle certaines pratiques courantes ?
Absolument. Nombre de développeurs pensent encore que Googlebot « simule » un navigateur classique et donc gère les cookies comme Chrome ou Firefox. C'est faux. Le bot n'a jamais eu cette capacité, et Martin Splitt le rappelle ici sans ambiguïté.
Résultat : des milliers de sites perdent du contenu indexable sans même le savoir. Les tests avec Search Console ou des outils tiers qui eux stockent les cookies donnent une image trompeuse de ce que Google voit réellement.
- Googlebot = exploration sans état — aucun cookie n'est conservé entre deux requêtes
- Pagination, personnalisation et gating via cookies restent invisibles au crawl
- Les outils de test classiques ne reproduisent pas fidèlement cette limitation
- RGPD mal implémenté peut bloquer l'accès au contenu principal pour le bot
Avis d'un expert SEO
Cette règle s'applique-t-elle aussi au rendu JavaScript ?
Oui, même lors de la phase de rendu avec Chromium headless, les cookies ne sont pas stockés. Si votre JavaScript génère du contenu dynamique en se basant sur des cookies (sessions, préférences, A/B testing), Googlebot ne verra que la version par défaut — celle sans cookie.
Attention toutefois : certains scripts tiers peuvent déposer des cookies pendant le rendu, mais ils ne seront pas réutilisés lors des requêtes suivantes. Chaque page reste isolée dans sa propre session éphémère.
Peut-on contourner cette limitation avec des solutions techniques ?
Techniquement, oui — mais souvent au prix d'une complexité architecturale. Remplacer les cookies par des paramètres GET pour la pagination fonctionne, tout comme l'usage de fragments URL (#) ou de mécanismes de scroll infini bien implémentés. Mais ces solutions demandent un refactoring profond.
Le crawl via prerender ou des snapshots HTML pré-générés peut aussi compenser, surtout pour les sites à fort contenu dynamique. Reste que ces approches ajoutent de la dette technique — et ne résolvent pas le problème fondamental : une architecture dépendante des cookies est structurellement incompatible avec Googlebot. [À vérifier] : certains affirment que Google détecte et ignore les workarounds trop artificiels, mais aucune donnée officielle ne vient étayer cette affirmation.
Cette limitation explique-t-elle des chutes d'indexation inexpliquées ?
Probablement plus souvent qu'on ne le pense. J'ai vu des sites e-commerce perdre 40% de leurs pages indexées après une migration CMS — simplement parce que le nouveau système gérait la pagination via cookies au lieu de paramètres URL. Google ne suivait plus les liens, fin de l'histoire.
Même constat sur des sites d'actualité qui conditionnent l'accès aux articles complets à l'acceptation d'un bandeau cookie. Si le contenu principal n'est visible qu'après clic sur « Accepter », Googlebot ne le voit jamais. Et Search Console ne remontera aucune erreur — le bot reçoit un 200 OK avec un DOM vide ou partiel.
Impact pratique et recommandations
Comment auditer rapidement si votre site dépend des cookies ?
Ouvrez Chrome en navigation privée, désactivez JavaScript et les cookies dans les DevTools (onglet Application > Storage > cochez « Block cookies »), puis naviguez manuellement sur votre site. Toute pagination, filtrage ou contenu qui disparaît ou devient inaccessible révèle une dépendance problématique.
Utilisez ensuite l'outil d'inspection d'URL de Search Console pour vérifier le rendu réel. Comparez le HTML brut avec la version rendue — si des blocs entiers manquent, c'est probablement lié aux cookies ou à du JavaScript qui attend une session active.
Quelles modifications architecturales privilégier ?
Remplacez les cookies de session par des paramètres GET persistants pour la pagination et les filtres. Exemple : /produits?page=2&tri=prix au lieu d'un système qui incrémente un cookie page_offset. Les liens deviennent crawlables, les pages indexables.
Pour le contenu personnalisé, séparez la logique client-side (user experience) de la logique serveur-side (SEO). Servez une version générique sans cookie à Googlebot, enrichie ensuite côté client pour les visiteurs humains via JavaScript. C'est du travail, mais c'est la seule approche durable.
Que faire si votre CMS impose des cookies par défaut ?
Certains CMS (notamment des solutions SaaS) gèrent nativement pagination et sessions via cookies. Si vous ne pouvez pas refactorer l'architecture, plusieurs options :
- Implémenter un système de prerendering (Prerender.io, Rendertron) qui génère des snapshots HTML sans cookies pour Googlebot
- Configurer des règles serveur (Apache, Nginx) pour servir une version épurée aux user-agents identifiés comme bots
- Utiliser des sitemaps XML enrichis avec toutes les URLs paginées explicitement listées — force le crawl même si les liens internes sont cassés
- Vérifier que les bandeaux RGPD n'empêchent pas l'accès au contenu principal avant acceptation cookies
- Tester régulièrement avec l'outil d'inspection d'URL et un crawl manuel cookies désactivés
L'absence de gestion des cookies par Googlebot n'est pas une nouveauté, mais reste largement sous-estimée. Des pans entiers de contenu disparaissent de l'index sans qu'aucune alerte ne remonte — le bot reçoit un 200 OK, tout semble normal.
Les architectures modernes reposant sur sessions, personnalisation et gating complexe sont particulièrement exposées. Refactorer ces mécanismes demande des compétences techniques pointues et une vision SEO globale — d'où l'intérêt de s'appuyer sur une agence SEO spécialisée capable d'auditer finement ces dépendances et de proposer des solutions adaptées à votre stack technique. Les enjeux d'indexation justifient largement cet investissement.
❓ Questions frequentes
Googlebot accepte-t-il les cookies même sans les stocker ?
Les paramètres UTM dans les URLs sont-ils affectés par cette limitation ?
Un site en JavaScript pur peut-il contourner cette règle ?
Les cookies de consentement RGPD bloquent-ils réellement l'indexation ?
Peut-on forcer Googlebot à accepter des cookies via robots.txt ou des directives serveur ?
🎥 De la même vidéo 8
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 15/11/2022
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.