Declaration officielle
Autres déclarations de cette vidéo 8 ▾
- □ Googlebot stocke-t-il les cookies lors de l'exploration de votre site ?
- □ Pourquoi les robots d'exploration ignorent-ils systématiquement vos cookies ?
- □ Le dynamic rendering avec parité de contenu est-il vraiment sans risque pour l'indexation ?
- □ Les crawlers Google se comportent-ils vraiment comme de vrais navigateurs ?
- □ Pourquoi tester votre site avec un émulateur de user agent ne suffit-il pas à détecter les problèmes de crawl ?
- □ Pourquoi tester votre site avec un crawler est-il indispensable pour le SEO ?
- □ Les cookies bloquent-ils vraiment l'accès des bots à votre contenu ?
- □ Les sites qui dépendent des cookies sont-ils invisibles pour Googlebot ?
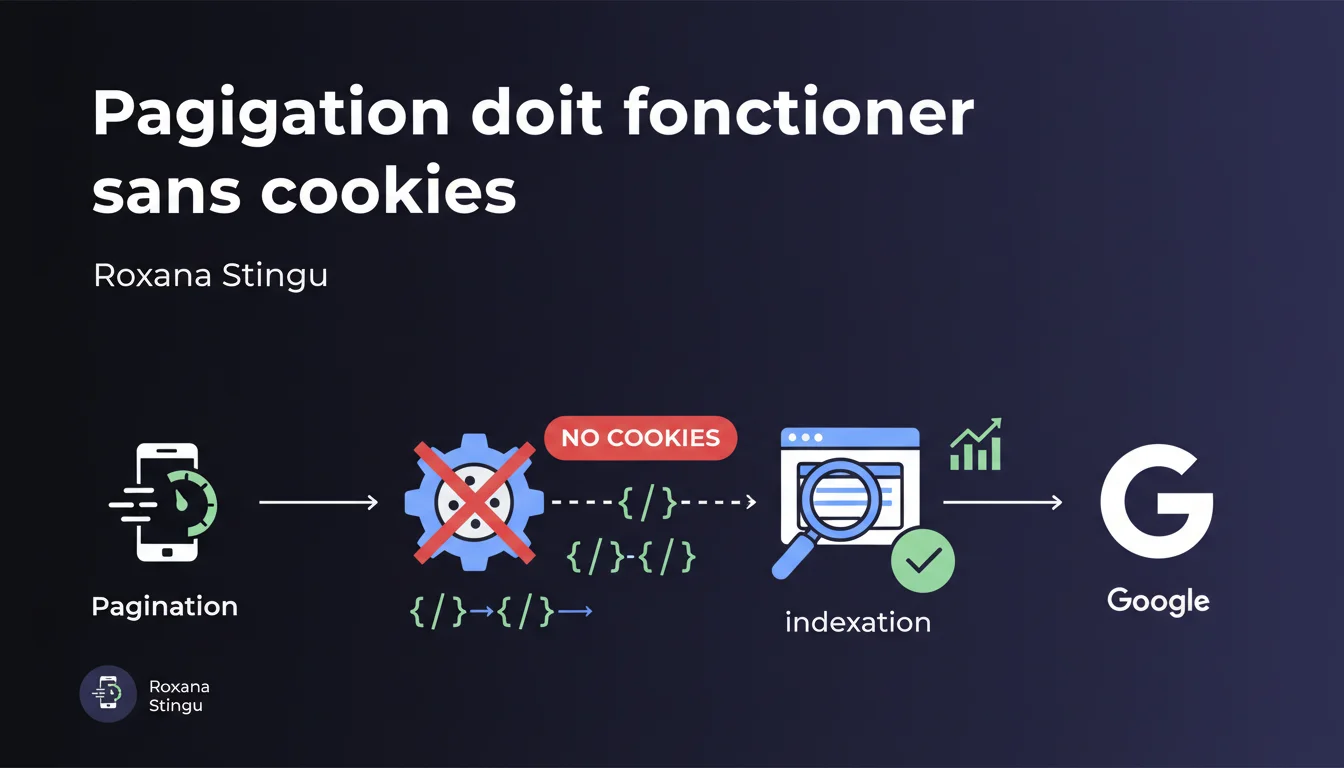
Google affirme que les systèmes de pagination qui dépendent de cookies créent des incohérences pour Googlebot et bloquent l'indexation des pages paginées. La pagination doit fonctionner sans cookie pour garantir un crawl cohérent. En clair : si votre pagination nécessite une session, Googlebot ne verra probablement qu'une fraction de vos contenus.
Ce qu'il faut comprendre
Pourquoi Googlebot ne gère-t-il pas les cookies comme un navigateur classique ?
Googlebot se comporte différemment d'un utilisateur humain. Contrairement à un navigateur qui conserve les sessions actives et stocke les cookies entre les pages, le bot de Google traite chaque URL de manière isolée.
Concrètement ? Quand Googlebot visite votre page 1, puis votre page 2, il ne « se souvient » pas forcément de son passage sur la page précédente. Si votre pagination repose sur un cookie de session pour afficher le bon ensemble de résultats, le bot risque de voir des contenus incohérents ou de tomber sur une erreur.
Quel type de pagination pose problème ?
Les systèmes qui stockent l'état de pagination dans un cookie — par exemple, pour mémoriser les filtres appliqués, le tri choisi ou la position dans un flux infini — créent des dépendances invisibles pour Googlebot.
Imaginons un site e-commerce où la page 2 d'une catégorie ne s'affiche correctement que si un cookie « filter_state » existe. Googlebot arrive directement sur /categorie?page=2 sans ce cookie. Résultat : page vide, erreur 404, ou pire — du contenu aléatoire qui n'a rien à voir avec l'URL.
Quelles sont les conséquences concrètes sur l'indexation ?
Si Googlebot ne peut pas accéder aux pages paginées de manière cohérente, vos contenus restent invisibles dans l'index. Vous avez beau générer un sitemap XML impeccable avec toutes vos pages, si le bot tombe sur des incohérences à chaque visite, il finit par abandonner.
Le crawl budget s'épuise sur des URLs qui ne renvoient rien de stable. Les signaux de qualité deviennent inexploitables. Et au final, des centaines ou des milliers de pages ne sont jamais indexées — alors qu'elles contiennent du contenu pertinent.
- Googlebot n'utilise pas de cookies persistants entre les crawls d'URLs différentes
- Les systèmes de pagination qui dépendent d'un état stocké côté client créent des incohérences d'affichage
- Une pagination mal conçue peut bloquer l'indexation de centaines de pages
- Le problème touche surtout les filtres dynamiques, le scroll infini géré en JS et les systèmes de tri complexes
- La solution : exposer la pagination via des paramètres d'URL explicites, pas via des cookies
Avis d'un expert SEO
Cette déclaration est-elle cohérente avec les observations terrain ?
Totalement. Depuis des années, on observe que les sites qui implémentent une pagination « propre » — avec des URLs distinctes et des paramètres GET explicites — s'en sortent nettement mieux à l'indexation que ceux qui tentent des approches exotiques.
Le problème, c'est que beaucoup de frameworks modernes (React, Vue, Next.js mal configuré) génèrent par défaut des systèmes de pagination qui reposent sur du state côté client. Le développeur ne pense même pas au SEO quand il code ça — et le site se retrouve avec un gouffre d'indexation.
Dans quels cas cette règle peut-elle sembler contre-intuitive ?
Certains développeurs pensent que stocker l'état de pagination dans un cookie améliore l'expérience utilisateur — et c'est vrai pour un humain qui navigue. Mais pour Googlebot, c'est une catastrophe.
Il y a aussi le cas des sites qui utilisent des cookies pour gérer des préférences de tri ou de filtrage. L'intention est louable, mais si ces préférences modifient le contenu affiché sans changer l'URL, Google ne voit qu'une seule version — souvent la version par défaut. Les autres combinaisons restent invisibles.
Quelles nuances faut-il apporter à cette déclaration ?
Google ne dit pas que les cookies sont interdits sur votre site. Il dit que la pagination elle-même ne doit pas en dépendre pour fonctionner. Vous pouvez tout à fait utiliser des cookies pour mémoriser des préférences utilisateur, du tracking analytics ou des sessions connectées — tant que ça n'affecte pas l'affichage de base des pages paginées.
La règle d'or : chaque page de pagination doit être accessible directement via son URL, sans prérequis, sans dépendance à un état antérieur. Si vous collez l'URL de la page 5 dans un navigateur en navigation privée, vous devez voir exactement le même contenu que Googlebot.
Impact pratique et recommandations
Que faut-il faire concrètement pour corriger une pagination basée sur cookies ?
Première étape : auditer votre système actuel. Ouvrez une navigation privée, allez directement sur une URL de page 2, 3, 10. Est-ce que le contenu s'affiche correctement ? Si vous tombez sur une page vide, une redirection ou un message d'erreur, c'est que votre pagination dépend d'un état stocké ailleurs — probablement un cookie.
Deuxième étape : refactoriser le code pour que chaque page paginée ait une URL unique et explicite. Les paramètres GET classiques (?page=2, ?offset=20, ?p=3) fonctionnent parfaitement. Évitez les systèmes où l'URL ne change pas et où seul le contenu est rechargé en AJAX sans mise à jour de l'historique du navigateur.
Comment vérifier que Googlebot accède correctement à vos pages paginées ?
Utilisez l'outil Test d'URL dans Google Search Console. Collez l'URL d'une page paginée (ex : /blog?page=5) et lancez le test en direct. Regardez le rendu HTML et le screenshot — vous devez voir exactement les contenus attendus, pas une page vide ou la page 1 par défaut.
Consultez aussi les rapports de couverture d'index. Si vous voyez des URLs de pagination marquées comme « Détectée, actuellement non indexée » ou « Crawlée, actuellement non indexée », c'est souvent le signe que Googlebot ne parvient pas à obtenir un contenu cohérent.
Quelles erreurs techniques faut-il éviter absolument ?
- Ne jamais rediriger Googlebot vers la page 1 quand il tente d'accéder à une page paginée sans cookie
- Éviter les systèmes où l'URL reste identique et où seul le DOM change via JavaScript
- Ne pas utiliser de fragment (#) pour la pagination — Google ignore généralement ce qui suit le #
- Proscrire les CAPTCHAs ou messages d'erreur qui s'affichent uniquement en l'absence de cookie
- Vérifier que le statut HTTP des pages paginées est bien 200, pas 302 ou 404
- Tester chaque URL de pagination en navigation privée et avec l'outil d'inspection d'URL de la Search Console
- Implémenter des balises rel="next" et rel="prev" si pertinent (même si Google ne les utilise plus officiellement, ça aide d'autres moteurs)
- S'assurer que le contenu des pages paginées est bien rendu côté serveur ou via un hydratation JS compatible Googlebot
❓ Questions frequentes
Est-ce que je peux utiliser des cookies pour d'autres fonctionnalités sans affecter le SEO ?
Les paramètres GET dans l'URL nuisent-ils au SEO ou diluent-ils le jus de lien ?
Mon site utilise un scroll infini en JavaScript, est-ce compatible avec cette recommandation ?
Dois-je indexer toutes mes pages paginées ou utiliser des canonicals vers la page 1 ?
Comment tester si Googlebot rencontre des incohérences sur mes pages paginées ?
🎥 De la même vidéo 8
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 15/11/2022
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.