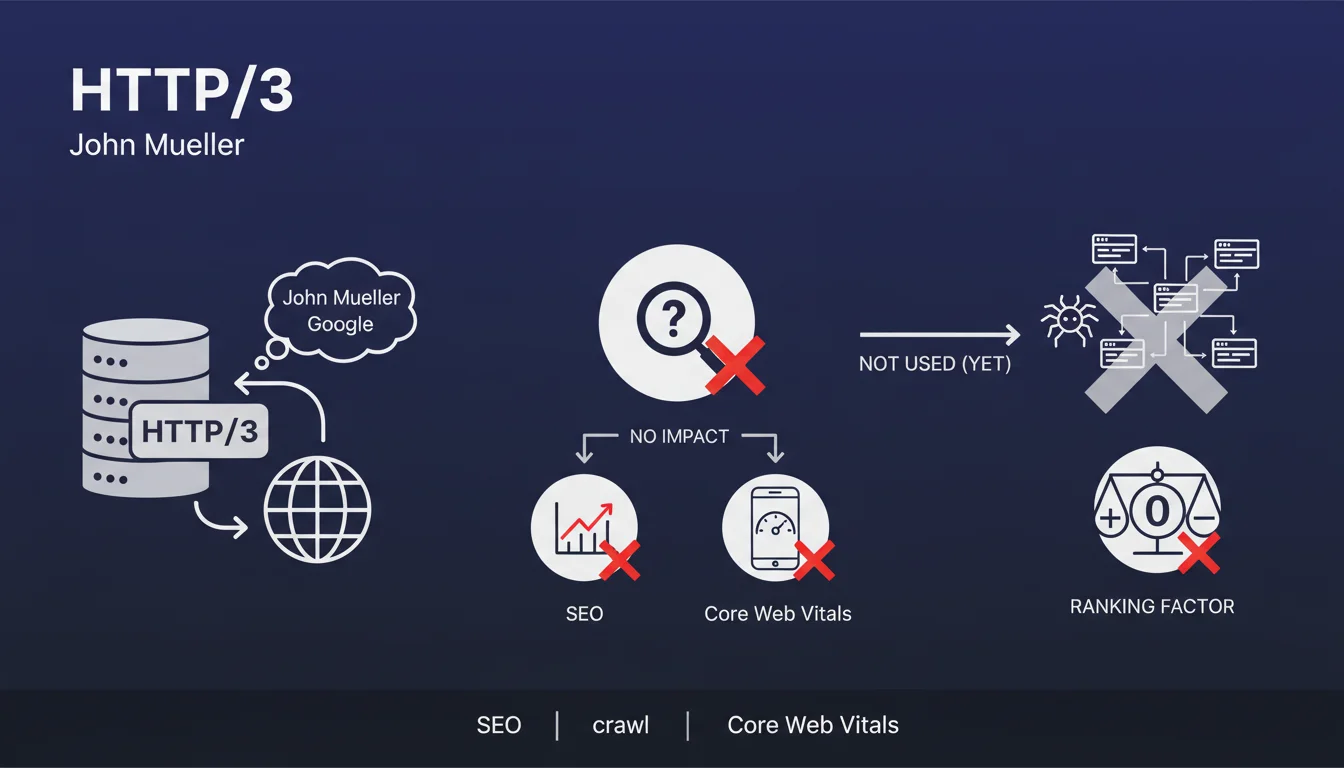
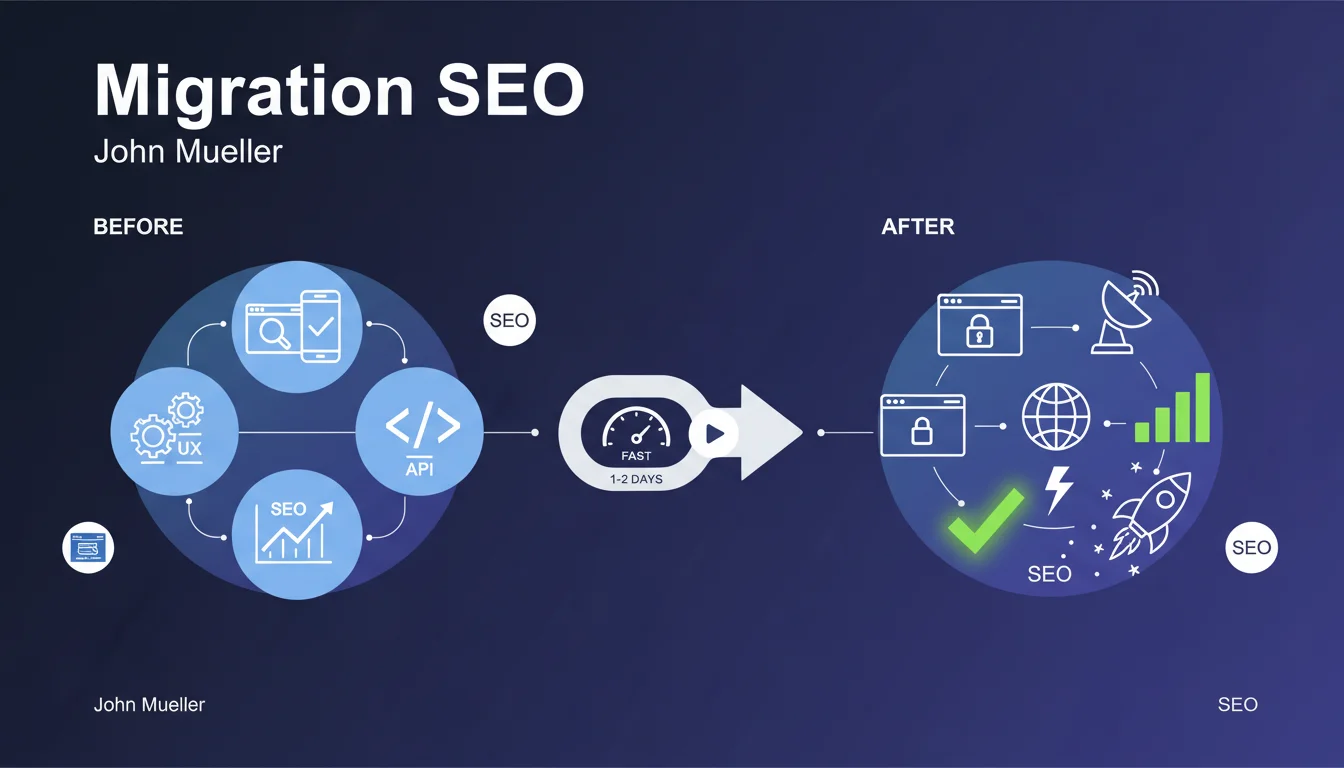
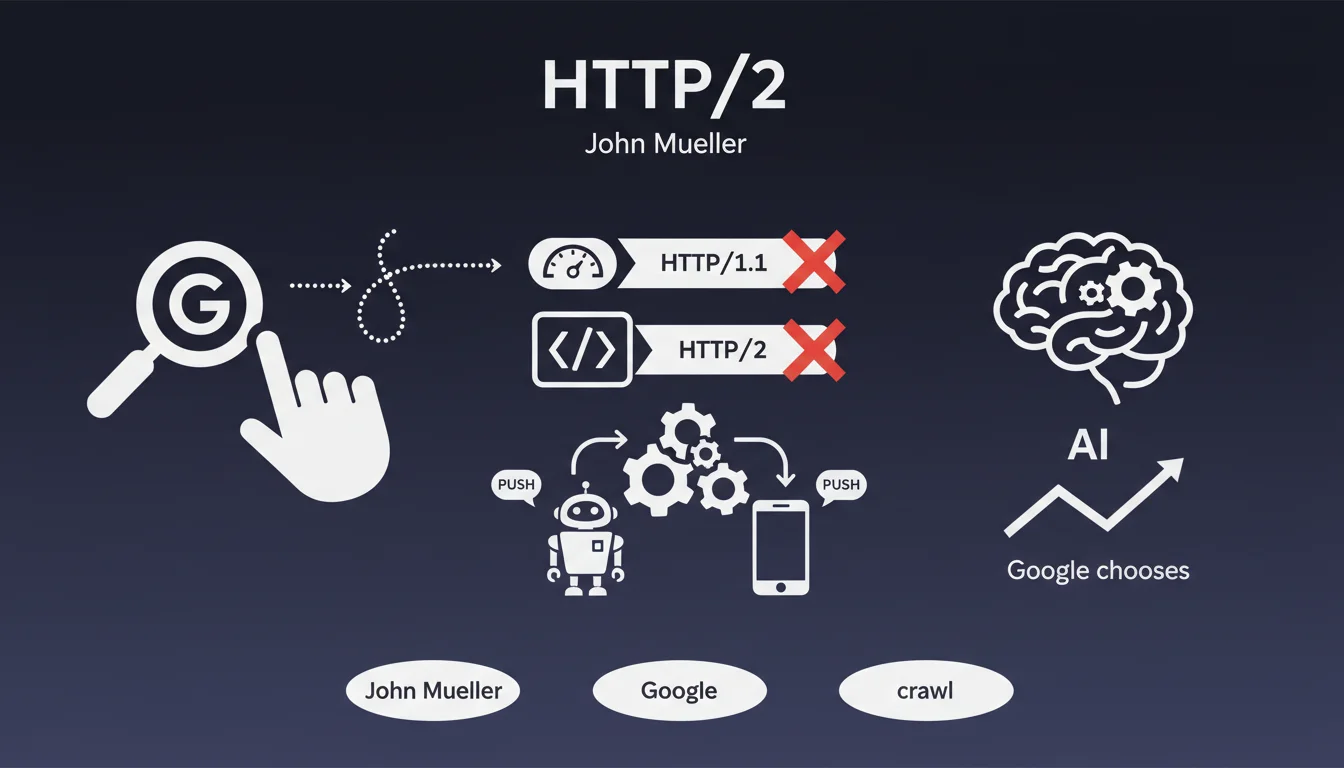
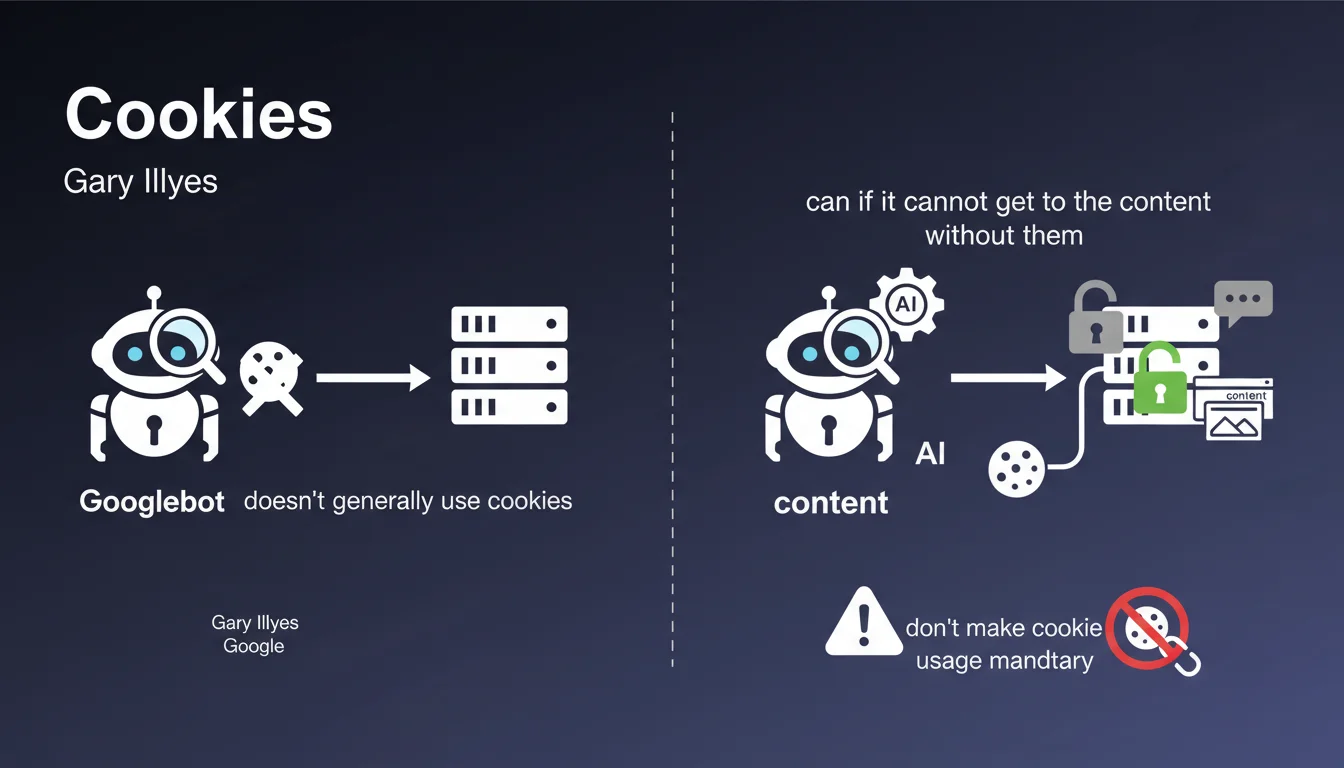
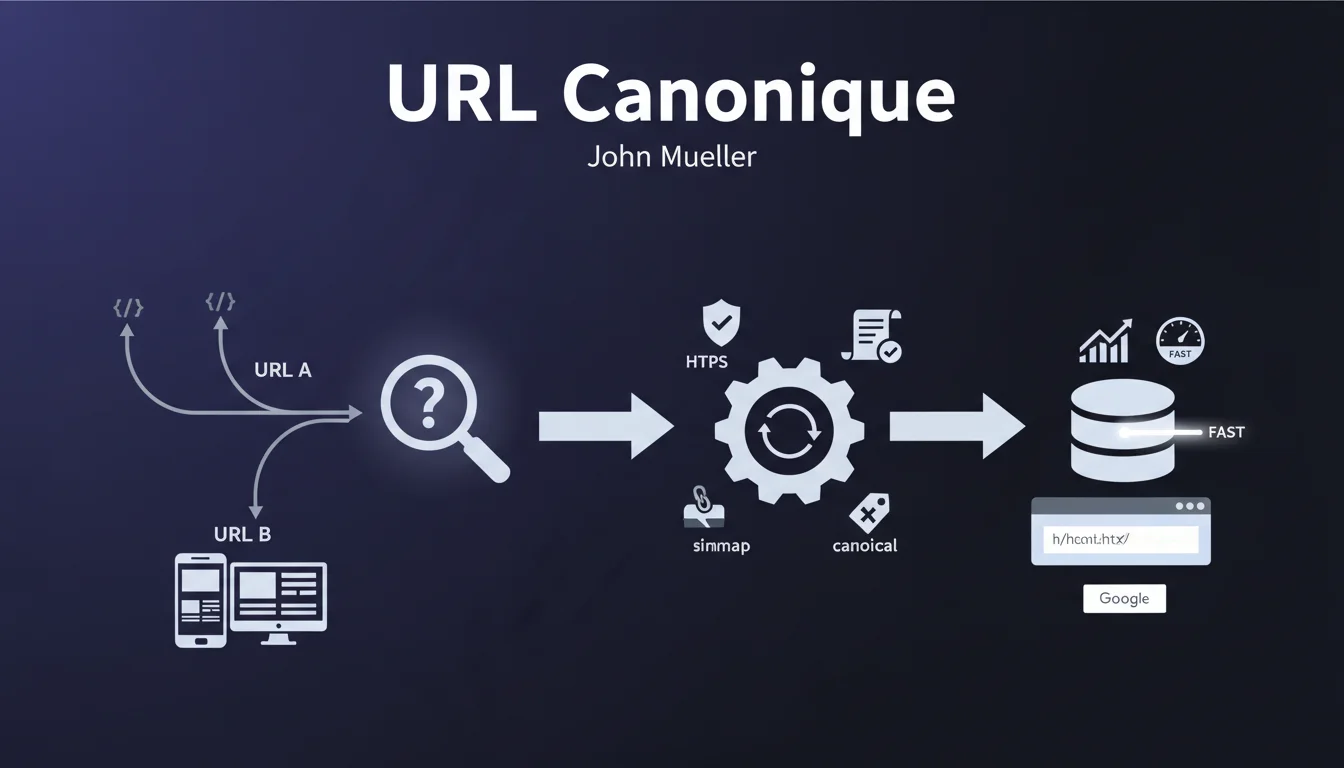
Comment Google choisit-il réellement l'URL canonique à indexer quand plusieurs versions existent ?
John Mueller
09/09/2019
★★★
John Mueller, dans une nouvelle vidéo de sa chaîne #AskGoogleWebmasters, explique comment Google choisit les URL canoniques. En effet, il ar...