Declaration officielle
Ce qu'il faut comprendre
Qu'est-ce qu'un protocole stateless et pourquoi Google l'utilise-t-il ?
Un protocole stateless signifie que Googlebot ne conserve aucune information de session entre ses différentes requêtes. Contrairement à un utilisateur classique qui navigue avec des cookies stockés dans son navigateur, le robot de Google efface toute donnée après chaque page visitée.
Cette approche garantit une exploration neutre et standardisée de tous les sites web. Google souhaite ainsi évaluer le contenu tel qu'il est réellement accessible, sans dépendre de paramètres personnalisés ou de sessions utilisateur.
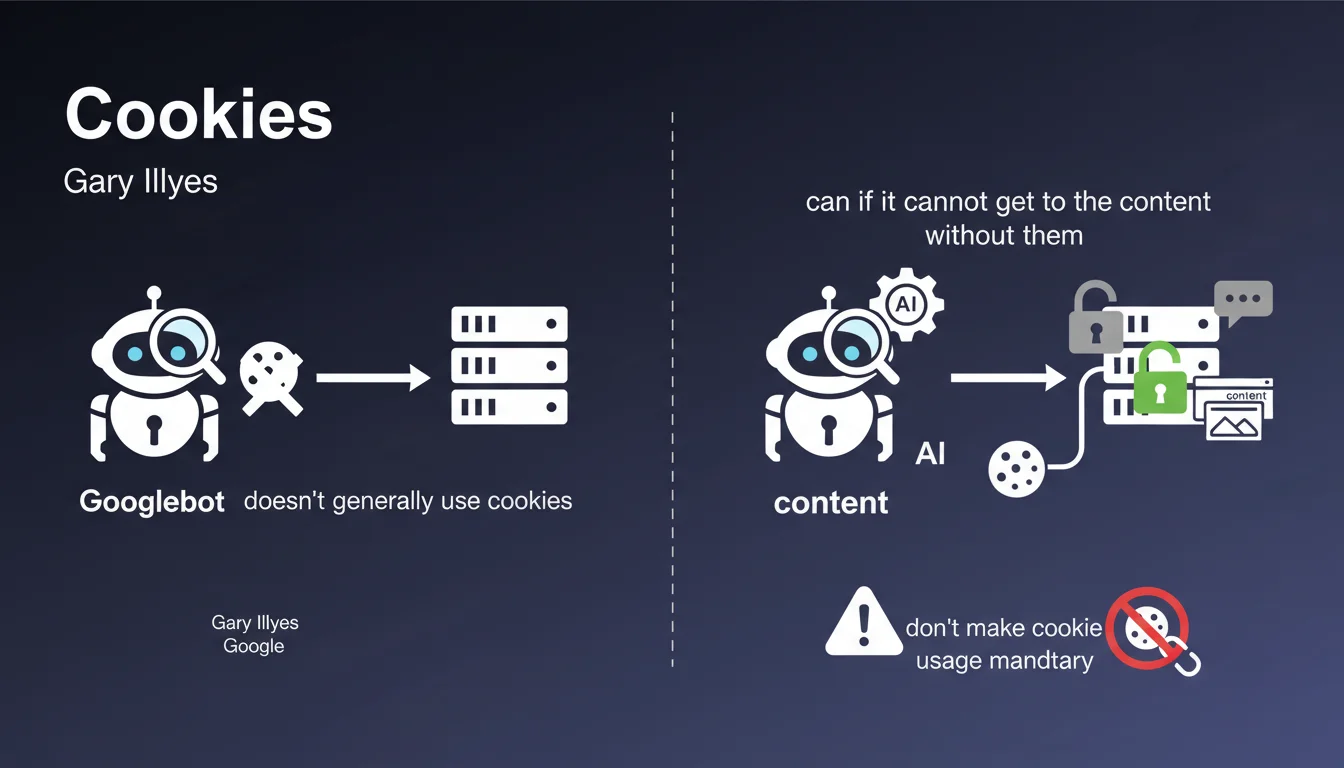
Pourquoi les cookies posent-ils problème pour le crawl ?
De nombreux sites web utilisent des cookies pour contrôler l'affichage du contenu. Si votre site nécessite des cookies pour afficher des pages ou des éléments importants, Googlebot ne pourra pas y accéder.
Les bannières de consentement aux cookies, les murs de connexion, ou les contenus conditionnels peuvent ainsi bloquer complètement l'indexation de vos pages. Google ne voit alors qu'une version incomplète ou vide de votre site.
Quelles sont les conséquences concrètes pour l'indexation ?
Les pages qui dépendent de cookies pour s'afficher correctement risquent de ne jamais apparaître dans les résultats de recherche. Le contenu masqué derrière des mécanismes basés sur les cookies reste invisible pour Google.
- Googlebot ne peut pas accepter, refuser ou gérer les cookies comme un utilisateur humain
- Le contenu affiché conditionnellement via cookies devient inaccessible à l'indexation
- Les éléments de navigation ou de structure dépendant de cookies peuvent fragmenter le crawl
- Les tests A/B basés sur cookies peuvent créer des incohérences d'indexation
Avis d'un expert SEO
Cette limitation de Googlebot est-elle cohérente avec les observations terrain ?
Absolument. Les audits SEO révèlent régulièrement des problèmes d'indexation liés aux cookies. Les sites e-commerce utilisant des cookies pour gérer les préférences d'affichage ou les catalogues régionaux rencontrent fréquemment ces difficultés.
La Search Console montre souvent des erreurs d'exploration pour des pages parfaitement fonctionnelles en navigation classique. L'explication se trouve généralement dans une dépendance excessive aux cookies pour le rendu du contenu.
Quelles nuances faut-il apporter à cette déclaration ?
Google précise que Googlebot peut techniquement recevoir des cookies envoyés par le serveur, mais ne les renvoie jamais lors des requêtes suivantes. Cette distinction technique est importante pour comprendre le comportement du crawler.
Certains systèmes de tracking et analytics peuvent donc enregistrer le passage de Googlebot, mais aucune personnalisation basée sur ces données ne fonctionnera. Le robot reste dans un état perpétuel de première visite.
Dans quels cas cette règle devient-elle particulièrement critique ?
Les sites avec bannières de consentement RGPD/cookies représentent le cas le plus problématique. Si votre site masque tout le contenu derrière un mur de consentement, Googlebot ne verra qu'une page vide.
Les plateformes nécessitant une authentification par cookies, les contenus géo-localisés, et les systèmes de préférences utilisateur posent également des défis majeurs pour le référencement. Ces architectures doivent être repensées pour rester compatibles avec le crawl.
Impact pratique et recommandations
Comment vérifier que votre site est accessible sans cookies ?
Utilisez le mode navigation privée de votre navigateur et désactivez complètement les cookies dans les paramètres. Naviguez sur votre site comme le ferait Googlebot : tout le contenu important doit rester visible et accessible.
L'outil Inspection d'URL dans la Search Console vous montre exactement ce que Google voit lors du crawl. Testez vos pages stratégiques et comparez avec l'affichage normal pour identifier les écarts.
- Tester l'affichage du site avec les cookies désactivés dans le navigateur
- Vérifier que les bannières de cookies n'occultent pas le contenu principal
- S'assurer que la navigation complète fonctionne sans session active
- Utiliser l'outil d'inspection d'URL de Google Search Console régulièrement
- Analyser les logs serveur pour identifier les pages que Googlebot ne peut pas crawler
- Implémenter des alternatives serveur pour le contenu conditionnel
Quelles erreurs techniques faut-il absolument éviter ?
Ne cachez jamais du contenu essentiel derrière des bannières de cookies qui bloquent toute la page. Les solutions de consentement doivent permettre au contenu de rester lisible, même si l'utilisateur n'a pas encore fait de choix.
Évitez les redirections conditionnelles basées sur cookies qui pourraient créer des boucles infinies pour Googlebot. Le robot doit toujours accéder à une version stable et complète de chaque URL.
Que faut-il mettre en place concrètement sur votre site ?
Privilégiez une architecture serveur-side pour les fonctionnalités critiques plutôt que de dépendre uniquement des cookies côté client. Les paramètres d'URL, les en-têtes HTTP, et la géolocalisation IP offrent des alternatives compatibles avec le crawl.
Pour les bannières de consentement, implémentez des solutions qui affichent un overlay transparent plutôt qu'un mur bloquant. Le contenu doit rester techniquement accessible dans le DOM, même si visuellement une notification apparaît.
- Refondre les bannières de cookies pour qu'elles n'obstruent pas le contenu
- Migrer les fonctionnalités critiques vers des mécanismes serveur-side
- Documenter les dépendances aux cookies dans l'architecture technique
- Former les équipes de développement aux contraintes du crawl sans état
- Établir des tests automatisés simulant un environnement sans cookies
- Auditer régulièrement les nouvelles fonctionnalités ajoutées au site
L'accessibilité sans cookies représente un prérequis fondamental pour le référencement moderne. Cette contrainte technique peut sembler simple en théorie, mais s'avère complexe à implémenter sur des sites existants avec des architectures déjà établies.
La refonte de systèmes de consentement, la migration de fonctionnalités serveur-side, et l'audit complet des dépendances techniques nécessitent une expertise approfondie en SEO technique. Face à ces enjeux critiques pour votre visibilité, l'accompagnement par une agence SEO spécialisée permet d'identifier rapidement les problèmes, de prioriser les corrections selon leur impact business, et d'éviter les erreurs coûteuses qui pourraient compromettre votre indexation.
💬 Commentaires (0)
Soyez le premier à commenter.