Official statement
Other statements from this video 10 ▾
- □ Faut-il encore optimiser ses meta descriptions si Google les ignore ?
- □ Faut-il encore optimiser les meta descriptions pour le SEO ?
- □ Faut-il encore utiliser rel=prev/next pour la pagination ?
- □ Le contenu boilerplate nuit-il vraiment au référencement de vos pages ?
- □ Le boilerplate est-il vraiment un danger pour votre référencement naturel ?
- □ Les redirections IP géolocalisées tuent-elles votre crawl Google ?
- □ Comment Google détermine-t-il vraiment la localisation d'un utilisateur pour le SEO local ?
- □ Les bases de données IP pour la géolocalisation sont-elles vraiment fiables pour le SEO international ?
- □ Google peut-il vraiment afficher des rich results sans schema markup ?
- □ Faut-il configurer le header Content-Language pour les PDF et fichiers non-HTML ?
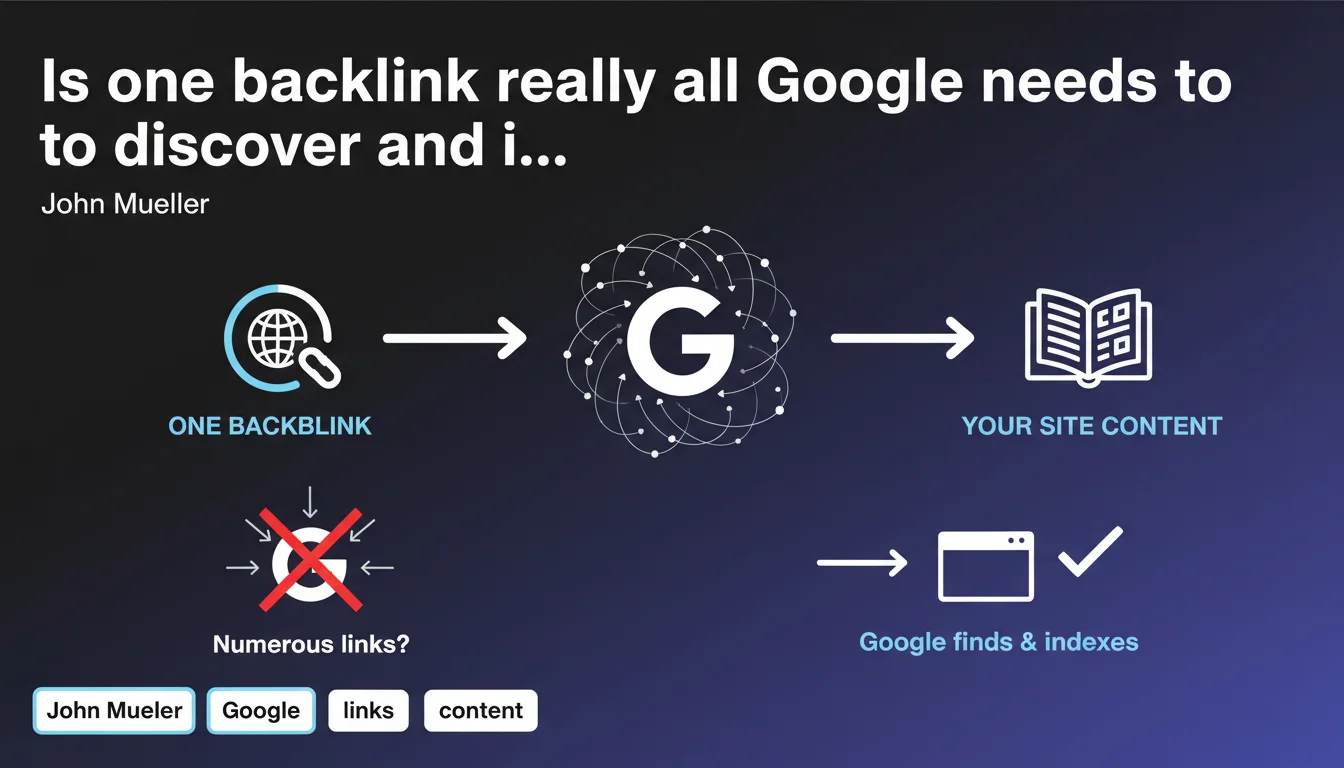
Google claims that a single incoming link is sufficient to discover a new website. There's no need to artificially multiply initial backlinks to be crawled — the priority lies elsewhere. This statement challenges certain SEO bootstrapping practices inherited from an era when crawling functioned differently.
What you need to understand
What does John Mueller's statement concretely mean?
Google has a crawl network that is dense enough for a single link — even from a modest website — to enable the discovery of a new URL. The notion of a "critical mass" of backlinks needed to trigger indexation is more myth than technical reality.
This does not mean that all sites will be indexed instantly. Discovery is one thing, indexation is another. Google can absolutely discover your content and decide not to index it if it judges that it brings nothing useful or lacks quality signals.
Why does this misconception persist among professionals?
Historically, how crawling functioned conditioned generations of SEO professionals to value the number of incoming links to accelerate discovery. This logic was valid 10-15 years ago, when crawl budget was more limited and Google relied heavily on links to map the web.
Today, with XML sitemaps, Google Search Console, the Indexing API (for certain content types), and far more efficient crawling, this race for initial backlinks no longer makes sense. The real battle is fought elsewhere: on the perceived value of content and the site's ability to generate engagement signals.
What are the direct implications for a new website?
You do not need a prior link-building campaign to be discovered. A simple link from a clean directory, a social media profile, or even your own submission via Google Search Console will be sufficient.
What really matters is what Google does after discovery: does it judge your site worthy of indexation? Do your pages answer a clear search intent? Do they comply with basic technical standards? That's where the real work lies.
- One link is enough for discovery, but does not imply automatic indexation
- XML sitemaps and Google Search Console render the dependency on initial backlinks obsolete
- Perceived content quality takes priority over link volume to trigger indexation
- Modern Google crawling is efficient enough to explore the web without requiring numerous entry signals
SEO Expert opinion
Is this statement consistent with practices observed in the field?
Yes, largely. Since the introduction of XML sitemaps and improvements to Search Console tools, we can observe that a properly configured site can be discovered within hours, even without external backlinks. Google now prioritizes its own discovery channels (direct submissions, Indexing API for certain content) rather than depending solely on the link graph.
Let's be honest: discovery has never been the real problem. The bottleneck occurs at the indexation stage. Google can perfectly crawl your site and decide not to index your pages because they are judged as low-quality, duplicated, or perceived as lacking utility. Mueller's statement obscures this nuance — whether intentionally or not.
What nuances should we add to this statement?
One link is technically sufficient, but not all links are equal. A link from a site that Google crawls rarely will mechanically delay discovery. Conversely, a link from a page frequently visited by Googlebot will accelerate the process.
Furthermore, this statement says nothing about indexation speed or the depth of crawl once the site is discovered. A site with only one backlink but no authority or engagement signals will certainly be discovered, but potentially processed with low priority — and therefore indexed partially or belatedly.
In what cases does this rule not really apply?
For extremely large-scale sites (millions of pages), the discovery of an isolated URL does not guarantee that Google will crawl the entire site. Crawl budget becomes a real constraint again, and there, multiplying entry points through strategic backlinks can indeed accelerate the indexation of deep sections.
Similarly, for content extremely time-sensitive (news, events), relying on a single link to trigger rapid discovery is risky. In these cases, using the Indexing API or submitting manually via Google Search Console remains the best approach.
Practical impact and recommendations
What should you concretely do to ensure discovery of a new website?
No need to waste time multiplying artificial backlinks from questionable directories. Focus on technical fundamentals: a clean XML sitemap, submission via Google Search Console, and possibly a link from a trusted site you control (social media profile, other web property).
Make sure your robots.txt file does not prevent crawling, that your important pages are accessible within 2-3 clicks maximum from the homepage, and that your server responds correctly to Googlebot requests. This is more than sufficient to trigger discovery.
What errors should you avoid after initial discovery?
Do not confuse discovery with indexation. Once your site is crawled, Google will evaluate the value of your content. If your pages are generic, duplicated, or perceived as lacking real utility, they risk being discovered but never indexed — or quickly deindexed.
Also avoid creating thousands of low-quality pages hoping that "Google will eventually index some of them." This strategy dilutes quality signals and can harm your entire site. Prioritize depth and expertise on a few topics rather than dispersal.
How do you verify that your discovery strategy is working?
Use Google Search Console to track crawl evolution: the "Crawl Statistics" section to see if Googlebot visits your site regularly, and the "Pages" section to identify those discovered but not indexed. This is where the real issues are revealed.
If strategic pages remain "Discovered - currently not indexed," that's a red flag. It means Google found them but judges they bring nothing new. Work on editorial differentiation and relevance signals before seeking more backlinks.
- Set up a comprehensive XML sitemap and submit it via Google Search Console
- Verify that your robots.txt file allows crawling of important sections
- Ensure you have at least one external link (even modest) pointing to your homepage
- Monitor crawl statistics to detect any crawling anomalies
- Identify pages "Discovered - not indexed" and improve their editorial quality
- Optimize internal structure so strategic pages are accessible within 2-3 clicks maximum
- Don't waste time on artificial backlink campaigns to trigger discovery
Discovery is no longer a critical technical issue thanks to modern submission tools. The real battle is fought over perceived content quality and the ability to generate relevance signals once the site is crawled. If this optimization phase seems complex to pilot alone — between log analysis, editorial improvement, and technical structuring — calling on a specialized SEO agency can significantly accelerate your compliance and save you months of trial and error.
❓ Frequently Asked Questions
Un lien depuis un site de faible autorité suffit-il pour déclencher la découverte ?
Dois-je quand même soumettre mon sitemap XML si j'ai déjà un backlink ?
Pourquoi mon site est-il découvert mais pas indexé ?
Combien de temps après la découverte Google indexe-t-il généralement un site ?
Faut-il utiliser l'API Indexing pour accélérer la découverte ?
🎥 From the same video 10
Other SEO insights extracted from this same Google Search Central video · published on 25/04/2024
🎥 Watch the full video on YouTube →
💬 Comments (0)
Be the first to comment.