Declaration officielle
Autres déclarations de cette vidéo 10 ▾
- □ Faut-il encore optimiser ses meta descriptions si Google les ignore ?
- □ Faut-il encore optimiser les meta descriptions pour le SEO ?
- □ Faut-il encore utiliser rel=prev/next pour la pagination ?
- □ Le contenu boilerplate nuit-il vraiment au référencement de vos pages ?
- □ Le boilerplate est-il vraiment un danger pour votre référencement naturel ?
- □ Les redirections IP géolocalisées tuent-elles votre crawl Google ?
- □ Comment Google détermine-t-il vraiment la localisation d'un utilisateur pour le SEO local ?
- □ Les bases de données IP pour la géolocalisation sont-elles vraiment fiables pour le SEO international ?
- □ Google peut-il vraiment afficher des rich results sans schema markup ?
- □ Faut-il configurer le header Content-Language pour les PDF et fichiers non-HTML ?
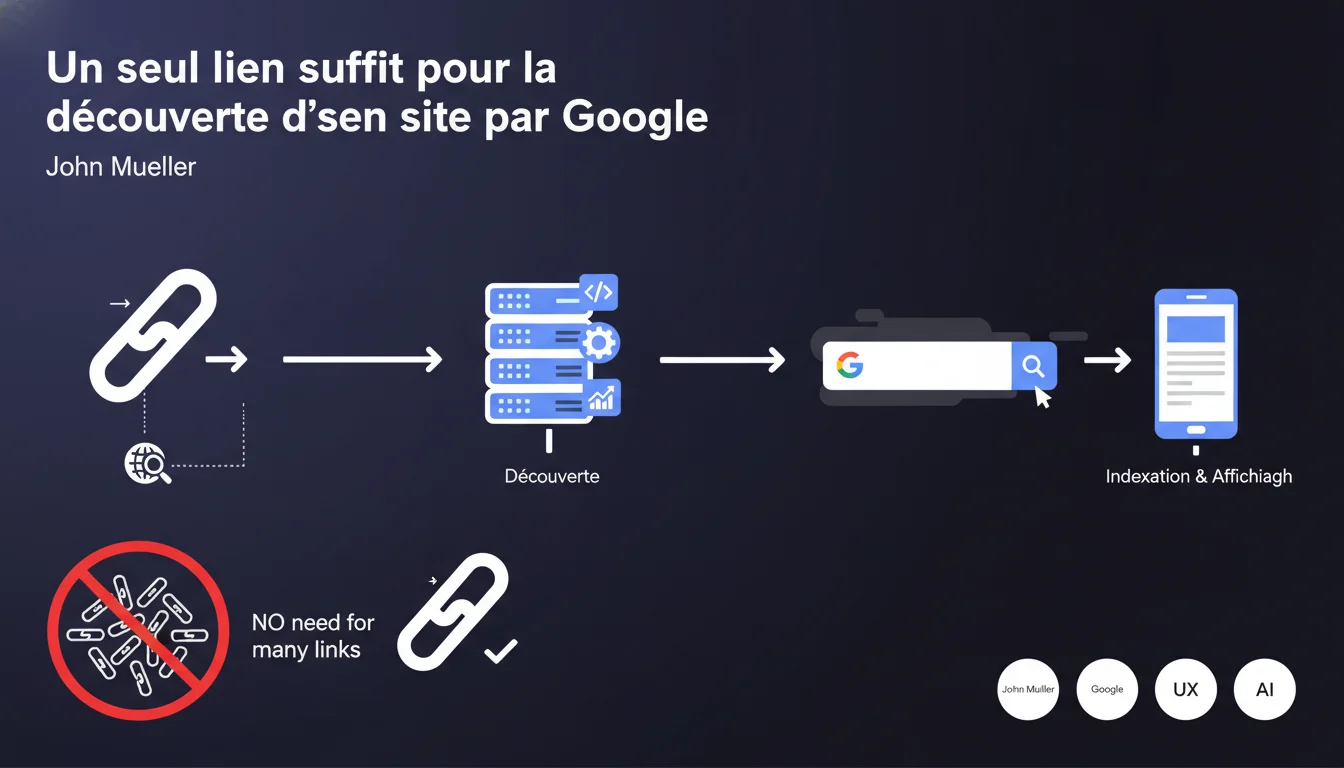
Google affirme qu'un unique lien entrant suffit pour découvrir un nouveau site web. Inutile donc de multiplier artificiellement les backlinks initiaux pour être crawlé — la priorité est ailleurs. Cette déclaration remet en question certaines pratiques d'amorçage SEO héritées d'une époque où le crawl fonctionnait différemment.
Ce qu'il faut comprendre
Que signifie concrètement cette affirmation de John Mueller ?
Google dispose d'un réseau de crawl suffisamment dense pour qu'un seul lien — même depuis un site modeste — permette la découverte d'une nouvelle URL. La notion de "masse critique" de backlinks pour déclencher l'indexation relève du mythe plus que de la réalité technique.
Cela ne signifie pas que tous les sites seront indexés instantanément. La découverte est une chose, l'indexation en est une autre. Google peut parfaitement découvrir votre contenu et décider de ne pas l'indexer s'il juge qu'il n'apporte rien d'utile ou qu'il manque de signaux de qualité.
Pourquoi cette idée reçue persiste-t-elle chez les professionnels ?
Historiquement, le fonctionnement du crawl a conditionné des générations de SEO à valoriser le nombre de liens entrants pour accélérer la découverte. Cette logique était valable il y a 10-15 ans, quand le budget crawl était plus limité et que Google s'appuyait massivement sur les liens pour cartographier le web.
Aujourd'hui, avec les sitemaps XML, la Search Console, l'API Indexing (pour certains types de contenus), et un crawl bien plus efficace, cette course aux premiers backlinks n'a plus de sens. La vraie bataille se joue ailleurs : sur la valeur perçue du contenu et la capacité du site à générer des signaux d'engagement.
Quelles sont les implications directes pour un nouveau site ?
Vous n'avez pas besoin d'une campagne de netlinking préalable pour être découvert. Un simple lien depuis un annuaire propre, un profil social, ou même votre propre soumission via la Search Console fera l'affaire.
Ce qui compte réellement, c'est ce que Google fait après la découverte : est-ce qu'il juge votre site digne d'être indexé ? Est-ce que vos pages répondent à une intention de recherche claire ? Est-ce qu'elles respectent les standards techniques de base ? C'est là que se situe le vrai travail.
- Un lien suffit pour la découverte, mais n'implique pas l'indexation automatique
- Les sitemaps XML et la Search Console rendent la dépendance aux backlinks initiaux obsolète
- La qualité perçue du contenu prime sur le volume de liens pour déclencher l'indexation
- Le crawl moderne de Google est suffisamment efficace pour explorer le web sans nécessiter de nombreux signaux d'entrée
Avis d'un expert SEO
Cette déclaration est-elle cohérente avec les pratiques observées sur le terrain ?
Oui, largement. Depuis l'introduction des sitemaps XML et l'amélioration des outils Search Console, on constate qu'un site correctement configuré peut être découvert en quelques heures, même sans backlinks externes. Google privilégie désormais ses propres canaux de découverte (soumissions directes, API Indexing pour certains contenus) plutôt que de dépendre uniquement du graphe de liens.
Soyons honnêtes : la découverte n'a jamais été le vrai problème. Le blocage se situe au moment de l'indexation. Google peut parfaitement crawler votre site et décider de ne pas indexer vos pages parce qu'elles sont jugées low-quality, dupliquées, ou sans utilité perçue. La déclaration de Mueller occulte cette nuance — volontairement ou non.
Quelles nuances faut-il apporter à cette affirmation ?
Un lien suffit techniquement, mais tous les liens ne se valent pas. Un lien depuis un site que Google crawle rarement retardera mécaniquement la découverte. À l'inverse, un lien depuis une page fréquemment visitée par Googlebot accélérera le processus.
De plus, cette déclaration ne dit rien sur la vitesse d'indexation ni sur la profondeur du crawl une fois le site découvert. Un site avec un seul backlink mais sans autorité ni signaux d'engagement sera certes découvert, mais potentiellement traité avec une priorité basse — et donc indexé partiellement ou tardivement.
Dans quels cas cette règle ne s'applique-t-elle pas vraiment ?
Pour les sites à très grande échelle (millions de pages), la découverte d'une URL isolée ne garantit pas que Google crawlera l'ensemble du site. Le budget crawl redevient une contrainte réelle, et là, multiplier les points d'entrée via des backlinks stratégiques peut effectivement accélérer l'indexation des sections profondes.
De même, pour des contenus ultra-sensibles au temps (actualités, événements), compter sur un seul lien pour déclencher une découverte rapide est risqué. Dans ces cas, utiliser l'API Indexing ou soumettre manuellement via la Search Console reste la meilleure approche.
Impact pratique et recommandations
Que faut-il faire concrètement pour assurer la découverte d'un nouveau site ?
Inutile de perdre du temps à multiplier les backlinks artificiels depuis des annuaires douteux. Concentrez-vous sur les fondamentaux techniques : un sitemap XML propre, une soumission via la Search Console, et éventuellement un lien depuis un site de confiance que vous contrôlez (profil social, autre propriété web).
Assurez-vous que votre fichier robots.txt n'empêche pas le crawl, que vos pages importantes sont accessibles en 2-3 clics maximum depuis la homepage, et que votre serveur répond correctement aux requêtes Googlebot. C'est largement suffisant pour déclencher la découverte.
Quelles erreurs éviter après la découverte initiale ?
Ne confondez pas découverte et indexation. Une fois votre site crawlé, Google va évaluer la valeur de vos contenus. Si vos pages sont du contenu générique, dupliqué, ou sans réelle utilité, elles risquent d'être découvertes mais jamais indexées — ou désindexées rapidement.
Évitez aussi de créer des milliers de pages de faible qualité en espérant que "Google finira bien par en indexer quelques-unes". Cette stratégie dilue les signaux de qualité et peut nuire à l'ensemble du site. Privilégiez la profondeur et l'expertise sur quelques sujets plutôt que la dispersion.
Comment vérifier que votre stratégie de découverte fonctionne ?
Utilisez la Search Console pour suivre l'évolution du crawl : section "Statistiques d'exploration" pour voir si Googlebot visite régulièrement votre site, et "Pages" pour identifier celles qui sont découvertes mais non indexées. C'est là que se révèlent les vrais problèmes.
Si des pages stratégiques restent en "Découverte - actuellement non indexée", c'est un signal d'alarme. Cela signifie que Google les a trouvées mais juge qu'elles n'apportent rien. Travaillez sur la différenciation éditoriale et les signaux de pertinence avant de chercher plus de backlinks.
- Configurez un sitemap XML exhaustif et soumettez-le via la Search Console
- Vérifiez que le fichier robots.txt autorise le crawl des sections importantes
- Assurez-vous d'avoir au moins un lien externe (même modeste) pointant vers votre homepage
- Surveillez les statistiques d'exploration pour détecter les anomalies de crawl
- Identifiez les pages "Découvertes - non indexées" et améliorez leur qualité éditoriale
- Optimisez la structure interne pour que les pages stratégiques soient accessibles en 2-3 clics maximum
- Ne perdez pas de temps sur des campagnes de backlinks artificiels pour déclencher la découverte
La découverte n'est plus un enjeu technique critique grâce aux outils modernes de soumission. L'essentiel se joue sur la qualité perçue des contenus et la capacité à générer des signaux de pertinence une fois le site crawlé. Si cette phase d'optimisation vous semble complexe à piloter seul — entre analyse des logs, amélioration éditoriale et structuration technique — faire appel à une agence SEO spécialisée peut accélérer significativement votre mise en conformité et vous éviter des mois d'errances.
❓ Questions frequentes
Un lien depuis un site de faible autorité suffit-il pour déclencher la découverte ?
Dois-je quand même soumettre mon sitemap XML si j'ai déjà un backlink ?
Pourquoi mon site est-il découvert mais pas indexé ?
Combien de temps après la découverte Google indexe-t-il généralement un site ?
Faut-il utiliser l'API Indexing pour accélérer la découverte ?
🎥 De la même vidéo 10
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 25/04/2024
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.