Official statement
Other statements from this video 10 ▾
- □ Pourquoi la navigation à facettes cause-t-elle la moitié des problèmes de crawl ?
- □ Les paramètres d'action dans vos URLs sabotent-ils votre crawl budget ?
- □ Pourquoi Google intervient-il directement dans le code des plugins WordPress ?
- □ Les paramètres d'URL courts mettent-ils vraiment votre crawl budget en danger ?
- □ Faut-il vraiment se débarrasser des session IDs dans vos URLs ?
- □ Pourquoi vos paramètres de calendrier WordPress sabotent-ils votre crawl budget ?
- □ Le double encodage d'URLs tue-t-il vraiment votre crawl budget ?
- □ Pourquoi Googlebot doit-il crawler massivement un nouveau site avant de savoir s'il vaut le coup ?
- □ Faut-il attendre 24 heures pour qu'une modification de robots.txt soit prise en compte ?
- □ Faut-il abandonner les paramètres GET pour sécuriser son crawl budget ?
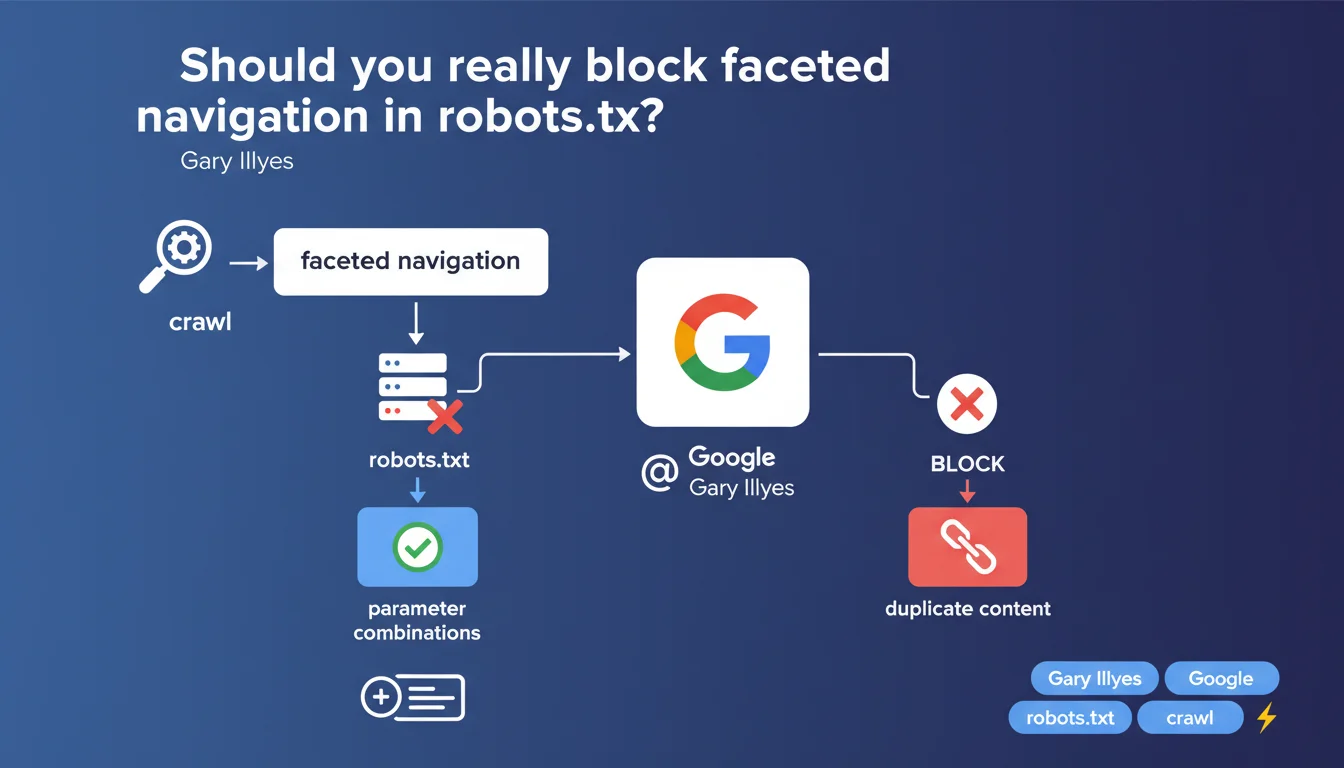
Google recommends using robots.txt to control the crawling of faceted navigation. Blocking these paths via robots.txt remains, according to Gary Illyes, the most reasonable method to avoid crawl budget waste. This position reaffirms a classical approach, although other mechanisms exist.
What you need to understand
What is faceted navigation and why does it pose a problem?
Faceted navigation generates multiple URLs to filter products or content according to various criteria — size, color, price, brand. An e-commerce site with 3 filters each having 5 options can easily create hundreds of URL combinations.
These pages often duplicate the same base content, dilute crawl budget, and can saturate the index with marginally relevant variants. Google wastes time crawling URLs with no real added value.
Why does Gary Illyes favor robots.txt?
The robots.txt file blocks Googlebot directly before it even loads resources. It's radical: no crawling, no server bandwidth waste, no accidental indexing via external links.
Illyes mentions that Google's own robots.txt file provides examples of parameter combinations to block. In other words: if Google applies it internally, it's because they consider this approach robust.
What are the limitations of this recommendation?
Blocking via robots.txt prevents all crawling — including that of faceted pages that could have real SEO value (long tail, search volume). Once blocked, these URLs no longer pass internal PageRank.
Other methods exist: noindex tags, canonicals, URL parameters via Search Console. Robots.txt remains binary — it's all or nothing.
- robots.txt blocks crawling before any content retrieval
- Avoids crawl budget waste on URLs without value
- Also prevents crawling of potentially useful faceted pages
- Possible alternative: noindex, canonical, URL parameter management
- Google applies this method internally on its own properties
SEO Expert opinion
Is this statement consistent with observed field practices?
Yes and no. On sites with explosive faceted navigation (thousands of combinations), blocking via robots.txt remains effective for stopping parasitic crawling outright. It's documented, tested, it works.
But many high-performing e-commerce sites selectively index certain facets — those targeting long-tail search queries with high potential. Systematically blocking via robots.txt deprives you of this lever. [To verify]: the statement doesn't specify how to arbitrate between useful and parasitic facets.
In what cases doesn't this rule apply?
If your faceted pages generate measurable organic traffic, blocking them would be counterproductive. Certain filter combinations correspond to specific search intents — "women's black running shoes size 8" can match a faceted page.
In this case, it's better to use canonicals pointing to the neutral version, or strategic noindex on aberrant combinations, while still allowing crawling of facets with added value. Robots.txt is too blunt.
What nuance should be added to this recommendation?
The phrasing "most reasonable method" is debatable. Reasonable doesn't mean optimal. It's the simplest and safest solution when you want to avoid all risk — but not necessarily the most effective.
A detailed audit often identifies 10-20% of indexable facets that generate qualified traffic. Sacrificing this potential to simplify management is a choice — but not a technical inevitability.
Practical impact and recommendations
What should you concretely do on a site with faceted navigation?
Start by auditing your faceted URLs: how many are being crawled? Which ones generate organic traffic? Which ones unnecessarily saturate server logs? Google Search Console and your logs will give you this data.
If the majority of facets generate no traffic and pollute the index, robots.txt is indeed the most direct solution. Identify the URL patterns to block — for example: Disallow: /*?color=, Disallow: /*?size=.
What mistakes should you absolutely avoid?
Don't block all facets by default without prior analysis. Certain combinations can be strategic SEO entry points. Check first in Analytics and Search Console.
Also avoid blocking via robots.txt URLs that are already indexed without prior deindexing. A blocked but still-indexed URL can remain visible in SERPs with a truncated snippet — poor user experience.
How do you verify the configuration is correct?
Test your robots.txt with Google Search Console's testing tool. Verify that parasitic faceted URLs are properly blocked, and that strategic pages remain accessible.
Monitor the evolution of crawl budget in server logs. After implementation, the number of Googlebot hits on facets should drop. If not, the robots.txt syntax is probably incorrect.
- Audit faceted URLs in Search Console and server logs
- Identify URL patterns to block (parameters, recurring paths)
- Add appropriate Disallow rules to robots.txt
- Test the configuration with the Search Console tool
- Monitor impact on crawl budget for 2-4 weeks
- Plan Analytics tracking to detect any unexpected traffic loss
- Consider a hybrid approach: robots.txt for bulk, noindex/canonical for edge cases
❓ Frequently Asked Questions
Peut-on utiliser noindex au lieu de robots.txt pour la navigation à facettes ?
Bloquer des facettes dans robots.txt empêche-t-il leur désindexation ?
Les canonicals suffisent-ils à gérer la navigation à facettes ?
Comment identifier les facettes qui méritent d'être indexées ?
Faut-il bloquer les facettes même sur un petit site ?
🎥 From the same video 10
Other SEO insights extracted from this same Google Search Central video · published on 03/02/2026
🎥 Watch the full video on YouTube →
💬 Comments (0)
Be the first to comment.