Official statement
Other statements from this video 9 ▾
- □ Données structurées : Google ouvre-t-il vraiment de nouvelles opportunités ou complique-t-il encore la tâche ?
- □ Les données structurées garantissent-elles vraiment un affichage en résultats enrichis ?
- □ Pourquoi Google simplifie-t-il le rapport d'expérience de page dans Search Console ?
- □ Pourquoi Google a-t-il déplacé l'outil de test robots.txt dans Search Console ?
- □ Comment ralentir Googlebot quand il explore trop votre site ?
- □ Quelles sont les vraies priorités derrière les dernières mises à jour algorithmiques de Google ?
- □ Google-Extended dans robots.txt : faut-il bloquer l'IA générative de Google ?
- □ La fin des cookies tiers menace-t-elle vos conversions e-commerce ?
- □ Pourquoi Google élargit-il soudainement ses rapports Search Console aux données structurées ?
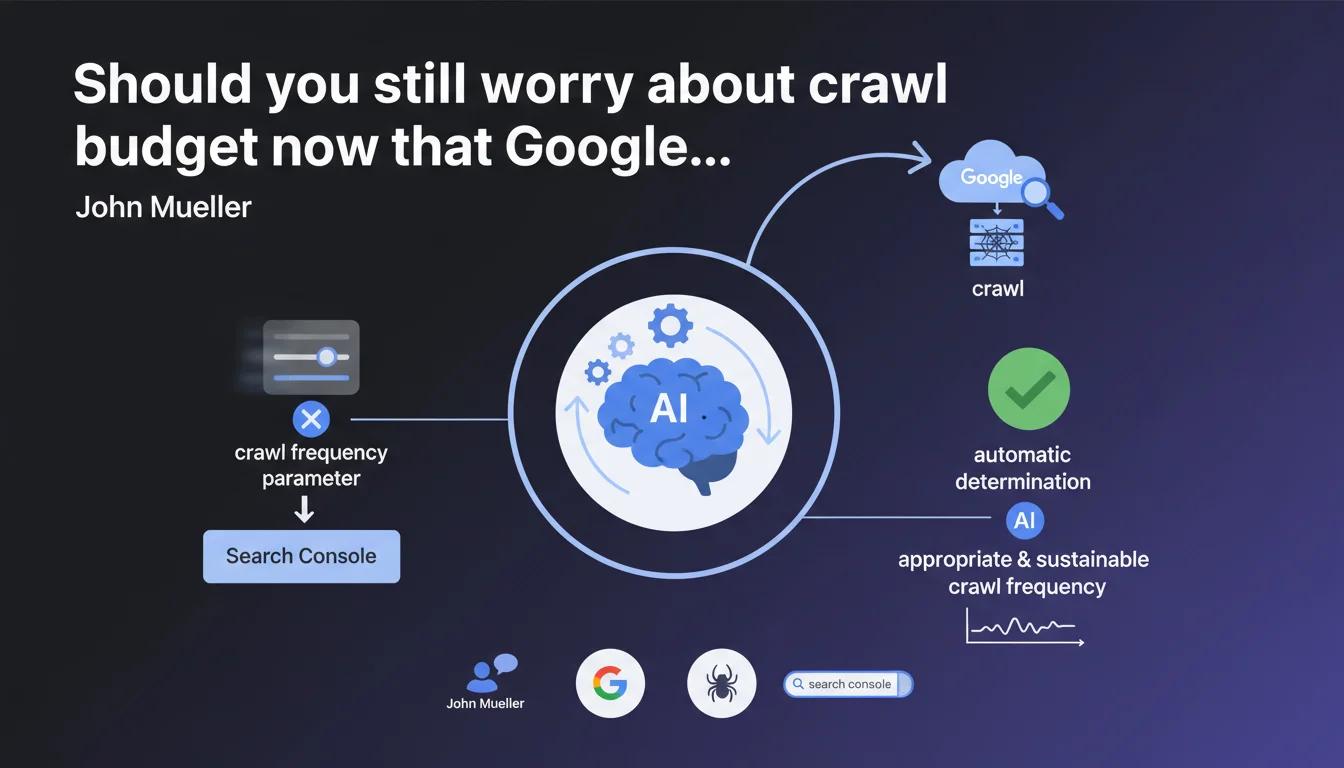
Google is removing the crawl frequency tool from Search Console, claiming that its algorithms now automatically manage optimal crawl rates. For SEOs, this means a loss of direct control, but also — according to Google — less need to micromanage these technical parameters.
What you need to understand
Why is Google removing this parameter now?
Google justifies this decision by the improvement of its automatic crawling systems. According to John Mueller, the algorithms determine by themselves a frequency suited to each site, making manual intervention obsolete.
Concretely? The tool allowed slowing down Googlebot in case of server overload. Its disappearance implies that Google believes its systems are smart enough to detect and respect the technical limits of a site without external instruction.
What does "appropriate and sustainable frequency" mean in Google's jargon?
This vague wording probably hides several criteria: server capacity, fresh content volume, domain authority, and user traffic. Google doesn't index everything — it prioritizes according to its internal crawl budget.
For an average site, this changes nothing. For large sites with millions of URLs or fragile infrastructure, it's more problematic. Total delegation to Google means accepting that it decides which pages deserve to be crawled.
Do webmasters still have any control levers?
Technically, yes — but indirectly. Robots.txt, XML sitemaps, and crawl-delay directives (for non-Google bots) remain functional. Noindex tags and URL parameter management also help guide Googlebot.
Let's be honest: the removal of this tool mainly reflects Google's desire to centralize decisions. Fewer manual parameters = less risk that webmasters artificially slow down crawling for questionable strategic reasons.
- Google claims that its automatic systems are now mature enough to manage crawl budget alone
- This decision reflects a general trend: less manual control, more AI-driven automation
- High-volume sites or those with fragile infrastructure lose a direct protection lever
- Indirect methods (robots.txt, sitemap, architecture) remain the main crawl optimization levers
SEO Expert opinion
Is this statement consistent with practices observed in the field?
Partially. Well-optimized sites indeed observe that Google adapts its crawl without manual intervention — this is observable in server logs. However, technically complex sites (multi-faceted e-commerce, content aggregators) still encounter situations where Googlebot gets stuck in pagination traps or filters.
The problem is that Google presents this removal as a neutral technical evolution, while it also removes a safety net for system administrators. If a site experiences abnormal crawl spikes, there's no longer an emergency button in Search Console.
What nuances should be added to this claim?
[To verify] Google claims its systems automatically detect server limits. In practice, some sites still experience occasional saturation linked to overly aggressive crawling — especially after migrations or major overhauls.
The notion of "appropriate frequency" remains vague. Google doesn't specify whether this means optimal for the site (technical capacity) or optimal for Google (fresh content discovery). These two objectives don't always coincide.
And that's where it gets tricky: a site might have an interest in slowing crawl on certain sections (archives, technical duplicate content) while accelerating it on others (strategic categories). Google's total automation doesn't allow this granularity.
In what cases does this removal cause problems?
Three critical situations emerge. First, sites hosted on shared infrastructure where a crawl spike can degrade performance for all server clients. Second, sites with limited server budgets (bandwidth-based billing) that could previously control their consumption.
Finally — and this is rarely mentioned — sites in delicate SEO overhaul phases where teams preferred to temporarily slow Googlebot down to prevent it from indexing transitory states. This possibility disappears.
Practical impact and recommendations
What should you do concretely to optimize crawl without this parameter?
First step: analyze your server logs (or your crawl analytics tools) to identify current exploration patterns. Identify over-crawled sections with low SEO value and under-crawled ones despite their strategic importance.
Next, strengthen your information architecture. Coherent internal linking, reduced click depth, and well-structured XML sitemaps guide Googlebot toward your priority content. Robots.txt remains your blocking tool — use it to exclude unnecessary sections (infinite facets, admin spaces, redundant media files).
Technically, optimize server response times. If Google detects that your site responds quickly, it naturally increases its crawl frequency. Conversely, slow servers trigger automatic slowdown — which can penalize indexing of new content.
What mistakes should you avoid now that the tool is gone?
Don't massively block sections in robots.txt out of fear of excessive crawl. This is counterproductive: Google must at least discover the URLs to understand their structure, even if you don't want them indexed (use noindex instead).
Another trap: neglecting URL consolidation. Sites with thousands of parameter variants (sorting, filters, sessions) waste crawl budget. Google removed the URL parameter management tool in 2022 — clean architecture and canonicals become even more critical.
Also avoid over-optimizing to the point of hiding strategic content. Some SEOs, obsessed with crawl budget, block too aggressively — and end up with entire sections ignored by Google.
How can you verify that Google is exploring your site effectively?
Three main indicators. First, the coverage report in Search Console: if important pages remain in "Discovered, currently not indexed" for weeks, that's a warning signal. Either Google doesn't prioritize them, or it can't crawl them efficiently.
Next, monitor the time between publication and indexation. Fresh content taking more than 48 hours to appear in the index suggests a problem with crawl frequency or internal prioritization.
Finally, use server logs to detect anomalies: sections crawled 10 times a day without updates, or conversely strategic pages visited once a month. It's in these gaps that optimizations lie.
- Analyze your server logs to identify current crawl imbalances
- Optimize your internal link architecture and reduce click depth
- Clean up your robots.txt: block only what must be blocked, not excessively out of caution
- Consolidate your URLs via canonicals and strict parameter management
- Improve server response times to encourage more frequent crawling
- Monitor the Search Console coverage report and indexing delay for your fresh content
- Use XML sitemaps to prioritize your strategic pages
❓ Frequently Asked Questions
Le paramètre de fréquence d'exploration était-il vraiment utile avant sa suppression ?
Puis-je encore ralentir Googlebot si mon serveur sature ?
Google va-t-il vraiment respecter mes limites serveur automatiquement ?
Cette suppression impacte-t-elle le crawl budget des gros sites ?
Faut-il modifier quelque chose immédiatement sur mon site ?
🎥 From the same video 9
Other SEO insights extracted from this same Google Search Central video · published on 19/12/2023
🎥 Watch the full video on YouTube →
💬 Comments (0)
Be the first to comment.