Official statement
Other statements from this video 9 ▾
- □ Données structurées : Google ouvre-t-il vraiment de nouvelles opportunités ou complique-t-il encore la tâche ?
- □ Les données structurées garantissent-elles vraiment un affichage en résultats enrichis ?
- □ Pourquoi Google simplifie-t-il le rapport d'expérience de page dans Search Console ?
- □ Pourquoi Google a-t-il déplacé l'outil de test robots.txt dans Search Console ?
- □ Faut-il encore se soucier du crawl budget maintenant que Google supprime le paramètre de fréquence d'exploration ?
- □ Comment ralentir Googlebot quand il explore trop votre site ?
- □ Quelles sont les vraies priorités derrière les dernières mises à jour algorithmiques de Google ?
- □ La fin des cookies tiers menace-t-elle vos conversions e-commerce ?
- □ Pourquoi Google élargit-il soudainement ses rapports Search Console aux données structurées ?
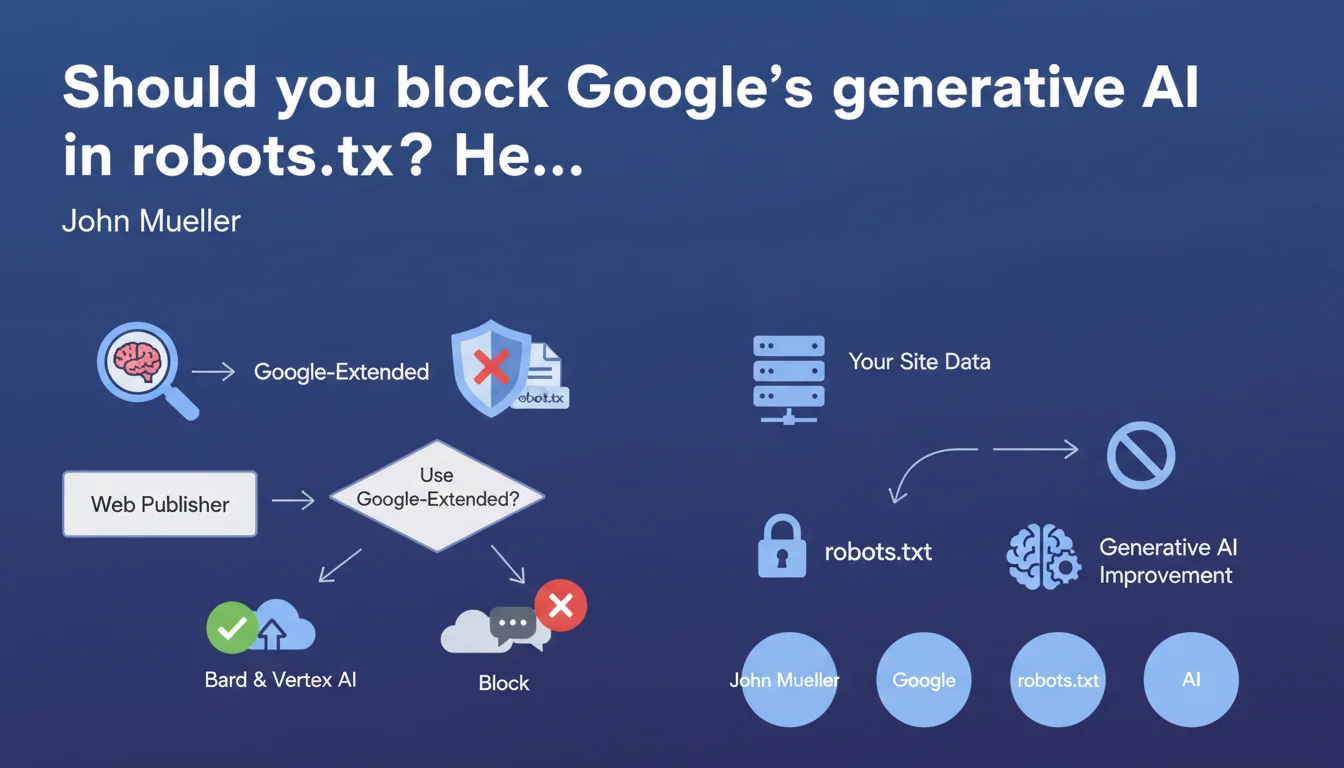
Google introduces a distinct user agent, Google-Extended, allowing publishers to specifically block their content from being used by Bard and Vertex AI without impacting search engine crawling. In concrete terms, you can now refuse to have your content used to train Google's generative models while remaining indexable.
What you need to understand
What exactly is Google-Extended?
Google-Extended is a new user agent distinct from Googlebot. While Googlebot crawls to feed the search index, Google-Extended collects data to improve generative AI models like Bard and Vertex AI APIs.
The separation is clear — and strategic. Google allows publishers to draw a distinct line between what feeds traditional search and what powers generative systems. A welcome control lever in a context where exploiting web content for AI raises legitimate questions.
Why is Google creating this separate agent?
Because blocking Googlebot amounts to shooting yourself in the foot — goodbye indexation, goodbye traffic. But authorizing Googlebot doesn't necessarily mean consenting to your content being used to train models that could compete with your own business.
By isolating Google-Extended, Google responds to growing publisher criticism over using their content for AI without compensation or explicit opt-in. It's as much a defensive maneuver as a practical one: give the illusion of control to avoid more stringent regulations.
What happens if you block Google-Extended?
Technically, nothing on the traditional SEO side. Your site continues to be crawled by Googlebot, indexed, ranked normally. You simply forgo "contributing" to the improvement of Bard and Google's generative services.
On the other hand, it's hard to know whether this will influence — now or later — visibility in Search Generative Experience (SGE) or other AI-enriched formats. Google remains vague on this point, as usual.
- Google-Extended: distinct user agent for generative AI (Bard, Vertex AI)
- Googlebot: remains the agent for traditional search engine indexation
- Blocking Google-Extended doesn't affect standard crawling or traditional SEO
- Potential impact on SGE and AI-enriched formats: total gray area
- Granular control via robots.txt:
User-agent: Google-Extended / Disallow: /
SEO Expert opinion
Is this separation really an altruistic gesture from Google?
Let's be honest: Google doesn't do anything out of philanthropy. This distinction between Googlebot and Google-Extended primarily responds to growing pressure from regulators and publishers. In Europe especially, where GDPR and copyright directives make non-consensual content exploitation legally risky.
Offering an opt-out via robots.txt is anticipating legal constraints by creating a precedent of "implicit consent." If you don't block Google-Extended, Google can argue you've tacitly authorized using your content for AI. [To verify]: no clear jurisprudence exists on the validity of this implicit consent via robots.txt in an AI context.
Should you systematically block Google-Extended?
It depends — and that's where it gets tricky. If your business model relies on premium content that LLMs could regurgitate for free, blocking makes sense. Media sites, specialized knowledge bases, technical documentation: protecting your IP can justify blocking.
But if you're seeking to maximize visibility across all channels, including in AI-enriched experiences Google is progressively rolling out, blocking Google-Extended could marginalize you. The problem? Google says nothing about the actual impact of this block on SGE, AI Overviews, or future generative formats integrated into the SERP.
What are the gray areas in this announcement?
First gray area: retroactivity. Has Google already crawled and ingested your content before Google-Extended was introduced? Likely. Blocking now may close the door after the furniture has been taken out.
Second murky point: lack of transparency on actual data use. Google says Google-Extended serves to improve Bard and Vertex AI, but no audit mechanism exists to verify what is actually crawled, stored, reused. You block on Google's word, without control or recourse.
Finally, Google doesn't specify whether other services or third-party partners access data collected by Google-Extended. [To verify]: what about Google's deals with OpenAI, Anthropic, or other AI players? The exact scope remains opaque.
Practical impact and recommendations
What specifically needs to be configured in robots.txt?
If you decide to block Google-Extended, add these lines to your robots.txt file:
User-agent: Google-Extended
Disallow: /
This block applies to your entire site. For selective blocking (certain sections only), replace / with the specific path: Disallow: /resources/ for example. Test via Google Search Console to verify syntax, even though Google-Extended doesn't yet appear in robots.txt testing tools — who knows why.
What errors should you avoid when implementing?
First common mistake: blocking Googlebot thinking you're blocking Google-Extended. These are two distinct agents. If you write User-agent: Googlebot / Disallow: /, you kill your SEO without touching generative AI.
Second pitfall: believing that partial robots.txt blocking is enough to legally protect your content. Robots.txt is a technical indication, not an enforceable contract. For legal protection, use explicit Terms of Service mentions and, if relevant, paywall or authentication mechanisms.
Third error: failing to monitor the evolution of Google agents. Google could very well introduce other AI user-agents in coming months. A static robots.txt file quickly becomes obsolete.
- Audit your current robots.txt file to identify existing directives
- Decide on a clear strategy: total block, selective block, or allow Google-Extended
- Add
User-agent: Google-Extendedwith appropriate Disallow rules - Test robots.txt syntax even if Google-Extended doesn't appear in validation tools
- Document your decision in internal processes to avoid accidental changes
- Monitor Google announcements for potential new AI agents coming
- Complement with explicit legal Terms of Service mentions if content protection is critical to your business model
❓ Frequently Asked Questions
Bloquer Google-Extended impacte-t-il mon référencement Google classique ?
Google-Extended crawle-t-il les sites qui ne l'ont pas explicitement bloqué ?
Peut-on autoriser Google-Extended sur certaines sections seulement ?
Bloquer Google-Extended empêche-t-il mon contenu d'apparaître dans SGE ou AI Overviews ?
Les contenus déjà crawlés avant l'introduction de Google-Extended sont-ils concernés ?
🎥 From the same video 9
Other SEO insights extracted from this same Google Search Central video · published on 19/12/2023
🎥 Watch the full video on YouTube →
💬 Comments (0)
Be the first to comment.