Official statement
Other statements from this video 17 ▾
- □ Faut-il éviter de modifier fréquemment les balises title pour préserver son référencement ?
- □ Peut-on vraiment effacer le passé SEO d'un domaine racheté ?
- □ Faut-il désavouer les liens qui ne correspondent plus à votre thématique ?
- □ Faut-il vraiment supprimer les backlinks pointant vers l'ancien contenu de votre domaine ?
- □ Les erreurs serveur tuent-elles vraiment votre classement Google ?
- □ Faut-il inclure le nom de marque dans les titres des sites d'actualités ?
- □ Pourquoi modifier uniquement le titre d'un contenu copié ne trompe-t-il personne ?
- □ Faut-il vraiment inclure la date dans les titres de vos articles ?
- □ Les catégories dans les URL influencent-elles vraiment le référencement ?
- □ Pourquoi Google crawle-t-il des pages sans jamais les indexer ?
- □ Comment faciliter l'indexation de vos contenus selon Google ?
- □ Les liens vers vos pages non indexées sont-ils vraiment perdus pour votre SEO ?
- □ Pourquoi Google réduit-il drastiquement son crawl après une migration CDN ?
- □ Le temps de réponse serveur influence-t-il vraiment le classement Google ?
- □ Faut-il vraiment mettre à jour les backlinks après une migration de domaine ?
- □ Le texte alternatif d'une image dans un lien a-t-il la même valeur SEO que le texte d'ancrage visible ?
- □ Les photos de produits retouchées nuisent-elles au classement des avis produits ?
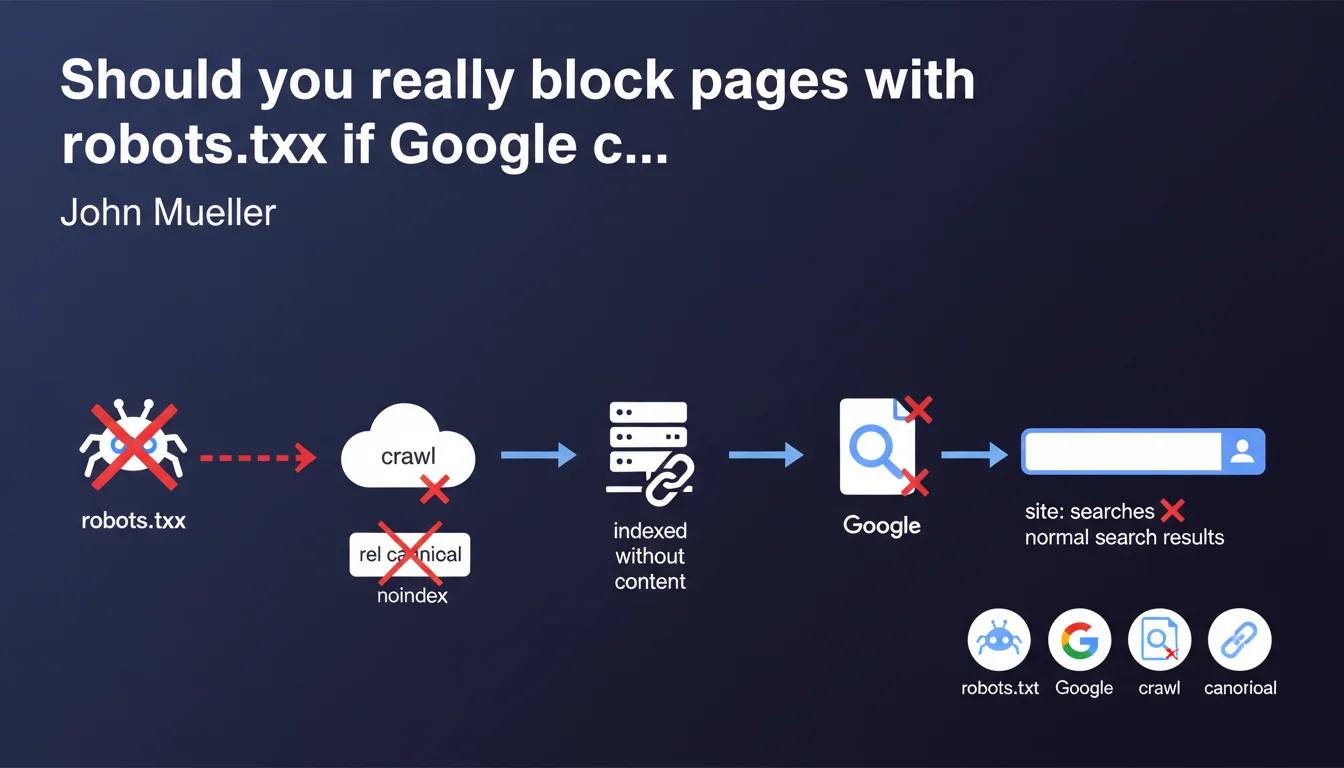
Pages blocked by robots.txt can be indexed by Google, but without exploitable content. The rel canonical and noindex directives don't work on these URLs since Google cannot crawl them. These ghost pages generally appear only in site: searches and rarely in normal organic search results.
What you need to understand
Why does Google index pages it cannot crawl?
Google can discover a URL in multiple ways: external links, backlinks, XML sitemap, or mentions on other sites. Even if robots.txt blocks access to the content, Google knows the page exists.
Indexation without crawling creates what is called a ghost page: Google records the URL in its index but without any data about its content, meta tags, or structure. It's an empty shell.
Why are noindex and rel canonical ignored on these pages?
Let's be honest: Google cannot read what it has no right to crawl. If your robots.txt blocks access, Googlebot never downloads the page's HTML.
Result? The noindex directives (in meta tags or HTTP headers) and rel canonical are never seen by the search engine. It's like sending a rejection letter in an envelope that nobody can open.
Do these pages really appear in normal search results?
Mueller states that they generally do not appear in classic organic results. The keyword here: generally. Not never.
Concretely, these content-free URLs have little value for Google. They can surface in specific site: searches, but their presence in normal SERPs remains marginal according to this statement.
- A page blocked by robots.txt can be indexed if Google discovers its URL through external links
- Indexation occurs without exploitable content — an empty URL in the index
- The noindex and rel canonical directives do not work since they are not crawlable
- These pages rarely appear in organic results, especially in site: searches
- robots.txt blocking is therefore not a reliable deindexation method
SEO Expert opinion
Is this statement consistent with field observations?
Yes and no. We do observe URLs blocked by robots.txt that appear in Google's index — it's a classic in SEO audits. However, the claim that they generally do not appear in organic results deserves nuance.
In practice, I've seen pages blocked by robots.txt rank for branded queries or exact URL matches. True, they display an empty or generic snippet, but they're there. Mueller's "generally" leaves comfortable room for interpretation by Google.
What risks does this approach pose for a site?
The problem is that blocking with robots.txt is not deindexing. If you have sensitive, duplicate, or low-quality pages that you absolutely want out of the index, robots.txt alone won't cut it.
Even worse: once blocked by robots.txt, you can no longer use noindex to clean up properly. You end up stuck with zombie URLs in the index that you no longer control directly.
In what cases does this rule create real problems?
E-commerce sites with multiple URL parameters (filters, sorts, sessions) often end up with hundreds of URLs blocked by robots.txt but indexed via backlinks or poorly controlled internal linking.
Same pattern for sites with member areas or downloadable PDFs blocked by robots.txt but linked from external forums. Google indexes the URL, you lose control over its presentation in the SERP. [To verify]: the actual impact of these ghost pages on crawl budget and perceived site quality remains a subject of debate among experts.
Practical impact and recommendations
What should you do concretely to avoid this pitfall?
First, audit your index. Run a site:yourdomain.com search and see if any URLs blocked by robots.txt appear. Google Search Console will also show you indexed but blocked pages — that's a red flag.
Then, decide on the appropriate strategy based on your situation. For pages to deindex: allow crawling temporarily, add noindex, then re-block once deindexation is confirmed. For pages that should never be indexed: avoid inbound links and use noindex + robots.txt in controlled combination.
What mistakes should you absolutely avoid in managing this?
Never block with robots.txt a page already indexed that you want to properly deindex. That's the recipe for creating uncontrollable zombie URLs.
Another common mistake: blocking critical resources (CSS, JS) with robots.txt thinking you're saving crawl budget. Google needs these resources for rendering — you're sabotaging your own indexation.
How can you verify your site is properly configured?
- Run a complete site: search and identify URLs that are blocked but indexed
- Check the Coverage report in Search Console, "Excluded" section to spot robots.txt/indexation conflicts
- Verify that your sensitive pages use noindex AND are crawlable (no robots.txt blocking)
- Review your external backlinks to pages you thought were protected by robots.txt
- Set up regular monitoring of your index to detect new ghost URLs
- Clearly document your robots.txt/noindex strategy to avoid contradictions
❓ Frequently Asked Questions
Peut-on utiliser robots.txt pour désindexer une page déjà présente dans Google ?
Si une page est bloquée par robots.txt et indexée, peut-elle recevoir du PageRank ?
Comment supprimer proprement des URLs bloquées par robots.txt de l'index Google ?
Les pages bloquées par robots.txt mais indexées nuisent-elles au SEO du site ?
Le rel canonical fonctionne-t-il sur une page accessible mais dont la canonique est bloquée par robots.txt ?
🎥 From the same video 17
Other SEO insights extracted from this same Google Search Central video · published on 04/02/2022
🎥 Watch the full video on YouTube →
💬 Comments (0)
Be the first to comment.