Official statement
Other statements from this video 6 ▾
- □ Le sitemap ne sert-il vraiment qu'à la découverte de vos URLs ?
- □ Peut-on vraiment indexer une page sans la crawler ?
- □ Pourquoi une page indexée n'apparaît-elle pas forcément dans les résultats Google ?
- □ Pourquoi une page indexée peut-elle rester invisible dans les résultats de recherche ?
- □ Pourquoi votre contenu indexé ne se classe-t-il toujours pas ?
- □ Google retire-t-il vraiment vos pages de l'index si personne ne clique dessus ?
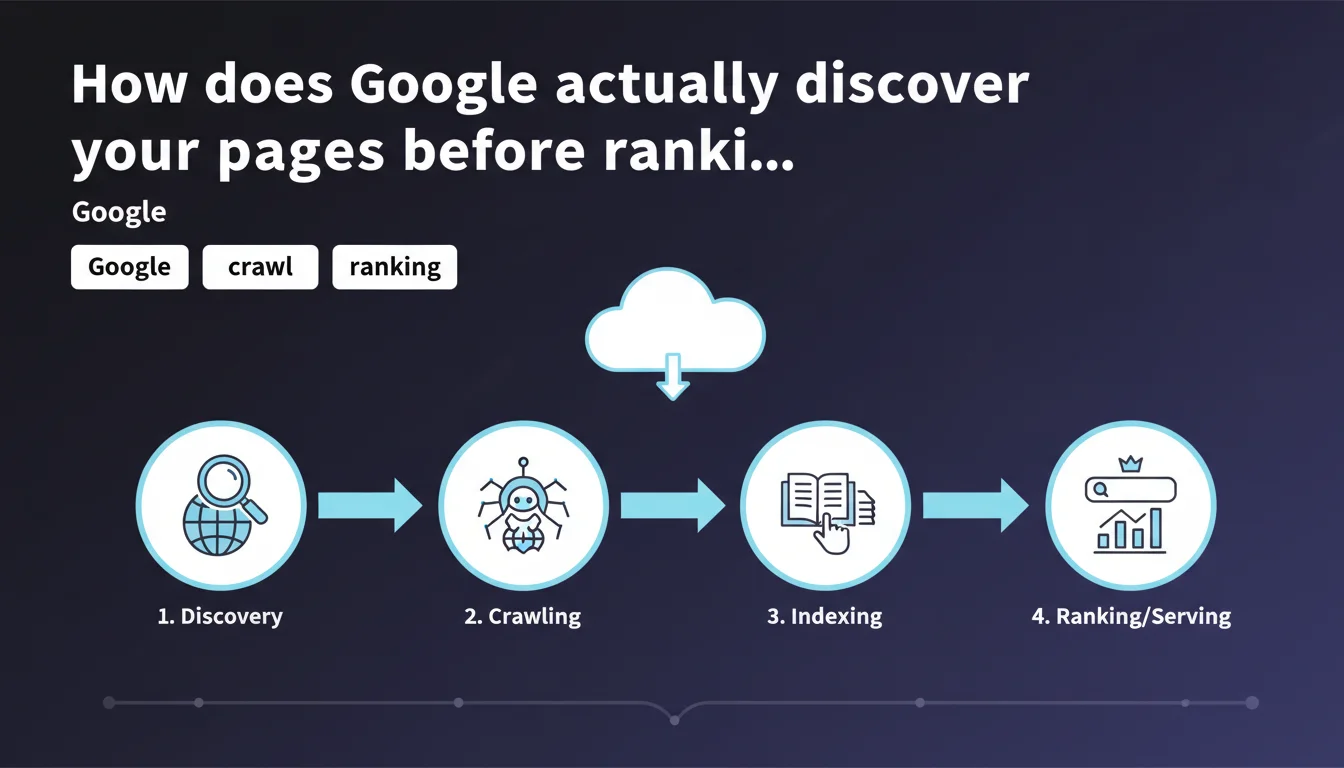
Google breaks down its process into 4 sequential steps: URL discovery, crawling by bots, indexing in the database, then ranking and display in search results. Each step determines the next — a page that isn't discovered will never be crawled, a page that isn't crawled will never be indexed. This sequence imposes a logic of progressive optimization that many sites still neglect.
What you need to understand
Why does Google insist on this 4-step sequence?
Google wants to clarify a fundamental point: not all pages follow the same path. A URL can be discovered without ever being crawled if the crawl budget is saturated. It can be crawled without being indexed if the content is deemed insufficient or duplicate.
This distinction is not merely cosmetic. It allows you to precisely diagnose where the blockage occurs when a page doesn't appear in search results. The problem isn't always content or backlinks — sometimes it's simply that Googlebot never found the URL.
What's the difference between discovery and crawling?
Discovery means Google knows the URL exists, through an internal link, XML sitemap, or external link. The URL enters a queue, with no guarantee of being visited quickly.
Crawling happens when Googlebot actually accesses the page to retrieve its content. This is where technical factors come into play: server availability, response time, robots.txt instructions, noindex tags.
Does indexing guarantee ranking?
No. A page can be indexed without ever appearing in search results for relevant queries. Indexing simply means Google has stored the page in its database and can theoretically return it.
Ranking then depends on hundreds of factors: content relevance, domain authority, user experience signals, freshness, search context. An indexed but poorly optimized page will remain invisible in practice.
- The 4 steps are sequential and conditional: each step depends on the success of the previous one
- Discovery doesn't guarantee crawling, especially on sites with limited crawl budget
- Crawling doesn't guarantee indexing if content is deemed insufficient or blocked by directives
- Indexing doesn't guarantee ranking — it's content quality and authority that determine real visibility
- Effective SEO diagnostics must identify at which step the process breaks down for each page
SEO Expert opinion
Does this linear vision truly reflect the complexity of the system?
Google presents a simplified model that works for most cases. But real-world experience shows exceptions — some pages are crawled and indexed within minutes, others wait weeks despite a clean sitemap and coherent internal linking.
What Google doesn't detail: crawl priorities vary enormously based on domain authority. A recent site with few backlinks may see new pages discovered but not crawled for days, while a major news outlet sees its content indexed almost instantly. [To verify]: Google remains vague about the precise criteria that determine how quickly pages move between each step.
Are XML sitemaps really essential for discovery?
In theory, no. Google claims internal links are sufficient. In practice? Sitemaps dramatically accelerate discovery, especially on sites with thousands of pages or deep information architecture.
I've observed cases where pages 5 clicks deep from the homepage remained undiscovered for months, while simple inclusion in the sitemap triggered crawling within 48 hours. The sitemap doesn't bypass crawl budget limits, but it explicitly signals priority URLs to Google. Ignoring this tool is amateurish.
Should you block certain steps intentionally?
Yes, and it's even recommended in certain contexts. Blocking crawling via robots.txt conserves crawl budget for strategic pages — useful on large e-commerce sites with thousands of unnecessary product variants.
Blocking indexing via noindex keeps pages accessible to users while avoiding index pollution (thank you pages, low-value content, obsolete archives). But be careful: a noindexed page doesn't pass PageRank. This nuance still escapes many practitioners who mistakenly noindex strategic pages for internal linking.
Practical impact and recommendations
What specifically should you check for each step?
For discovery: analyze your XML sitemaps and internal linking. Every strategic page should be reachable in maximum 3 clicks from the homepage. Use Search Console to identify URLs discovered but not crawled — this often signals a crawl budget issue or priority problem.
For crawling: monitor server response times, 5xx errors, and robots.txt directives. A slow or unstable server drastically slows crawling. Also check server logs to identify Googlebot crawl patterns and detect ignored sections of your site.
For indexation: track crawled but not indexed pages in Search Console. Common causes: duplicate content, thin content, incorrect canonicalization, accidental noindex tags. Never assume a crawled page will be automatically indexed.
How do you prioritize action based on identified blockages?
If your pages aren't being discovered: improve internal linking and submit a clean XML sitemap. Add links from your strategic pages to orphaned content.
If they're discovered but not crawled: the problem is probably crawl budget related. Reduce the number of unnecessary crawled pages (filters, URL parameters, duplicates), improve server speed, and consolidate domain authority through quality backlinks.
If they're crawled but not indexed: focus on content quality. Eliminate duplications, enrich thin pages, fix incorrect canonicals. A 150-word page with no added value will never be indexed, regardless of your technical efforts.
What mistakes should you absolutely avoid?
- Don't block both crawling AND indexing simultaneously via robots.txt + noindex — Google will never see the noindex directive
- Don't noindex strategic pages for internal linking just because they don't generate direct traffic
- Don't assume all sitemap pages will be crawled quickly — monitor Search Console stats
- Don't ignore server logs that reveal Googlebot's true crawl priorities
- Don't multiply unnecessary URL variants that saturate crawl budget without added value
❓ Frequently Asked Questions
Combien de temps faut-il entre la découverte et l'indexation d'une nouvelle page ?
Une page peut-elle être indexée sans apparaître dans les résultats de recherche ?
Le sitemap XML accélère-t-il vraiment la découverte des pages ?
Peut-on forcer Google à explorer une page plus rapidement ?
Pourquoi certaines pages sont explorées mais jamais indexées ?
🎥 From the same video 6
Other SEO insights extracted from this same Google Search Central video · published on 19/03/2025
🎥 Watch the full video on YouTube →
💬 Comments (0)
Be the first to comment.