Declaration officielle
Autres déclarations de cette vidéo 6 ▾
- □ Le sitemap ne sert-il vraiment qu'à la découverte de vos URLs ?
- □ Peut-on vraiment indexer une page sans la crawler ?
- □ Pourquoi une page indexée n'apparaît-elle pas forcément dans les résultats Google ?
- □ Pourquoi une page indexée peut-elle rester invisible dans les résultats de recherche ?
- □ Pourquoi votre contenu indexé ne se classe-t-il toujours pas ?
- □ Google retire-t-il vraiment vos pages de l'index si personne ne clique dessus ?
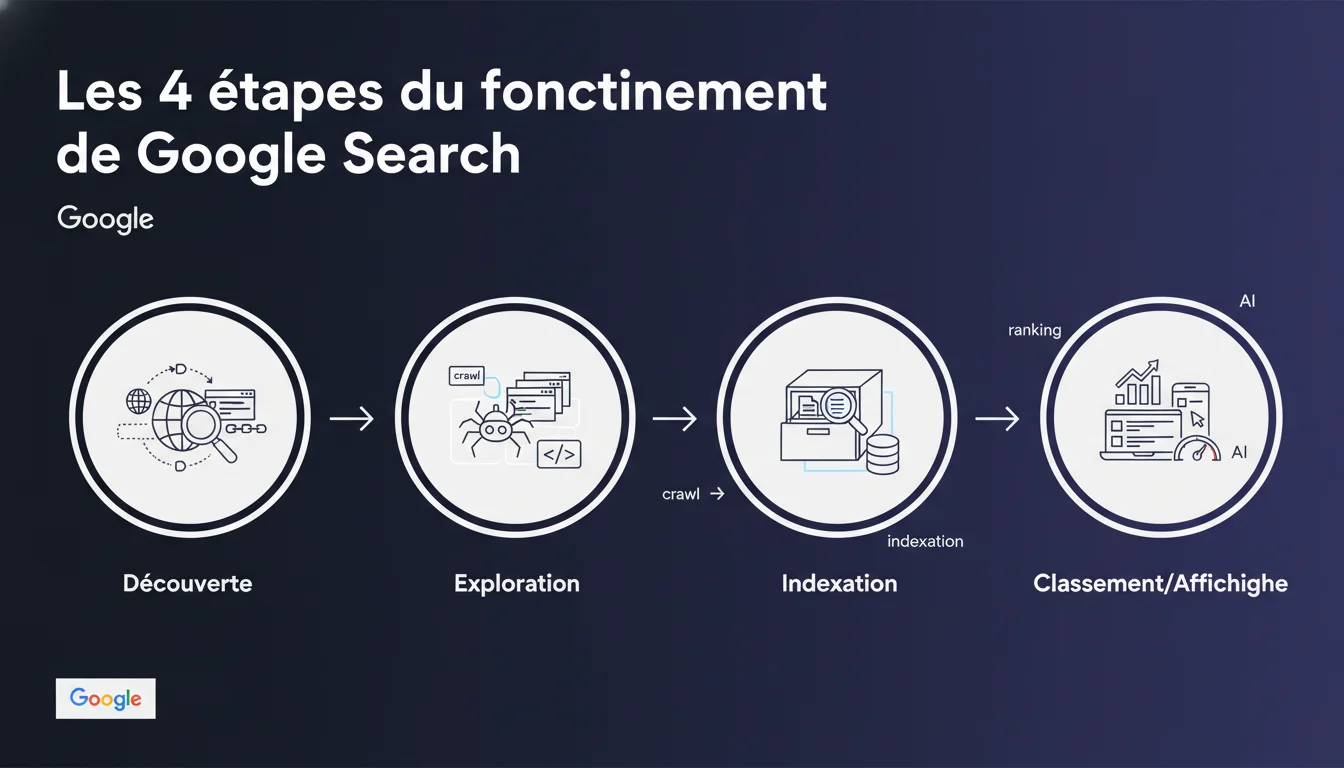
Google décompose son processus en 4 étapes séquentielles : découverte des URL, exploration par les bots, indexation dans la base de données, puis classement et affichage dans les résultats. Chaque étape conditionne la suivante — une page non découverte ne sera jamais explorée, une page non explorée ne sera jamais indexée. Cette séquence impose une logique d'optimisation progressive que beaucoup de sites négligent encore.
Ce qu'il faut comprendre
Pourquoi Google insiste-t-il sur cette séquence en 4 étapes ?
Google veut clarifier un point fondamental : toutes les pages ne suivent pas le même parcours. Une URL peut être découverte sans jamais être explorée si le crawl budget est saturé. Elle peut être explorée sans être indexée si le contenu est jugé insuffisant ou dupliqué.
Cette distinction n'est pas cosmétique. Elle permet de diagnostiquer précisément où se situe le blocage quand une page n'apparaît pas dans les résultats. Le problème n'est pas toujours le contenu ou les backlinks — parfois, c'est simplement que Googlebot n'a jamais trouvé l'URL.
Quelle différence entre découverte et exploration ?
La découverte (Discovery) signifie que Google connaît l'existence d'une URL, via un lien interne, un sitemap XML, ou un lien externe. L'URL entre dans une file d'attente, sans garantie d'être visitée rapidement.
L'exploration (Crawling) intervient quand Googlebot accède effectivement à la page pour en récupérer le contenu. C'est là qu'interviennent les facteurs techniques : disponibilité du serveur, temps de réponse, instructions robots.txt, balises noindex.
L'indexation garantit-elle le classement ?
Non. Une page peut être indexée sans jamais apparaître dans les résultats pour des requêtes pertinentes. L'indexation signifie simplement que Google a stocké la page dans sa base de données et peut théoriquement la restituer.
Le classement (Ranking) dépend ensuite de centaines de facteurs : pertinence du contenu, autorité du domaine, signaux d'expérience utilisateur, fraîcheur, contexte de recherche. Une page indexée mais mal optimisée restera invisible en pratique.
- Les 4 étapes sont séquentielles et conditionnelles : chaque étape dépend du succès de la précédente
- La découverte ne garantit pas l'exploration, surtout sur les sites à crawl budget limité
- L'exploration ne garantit pas l'indexation si le contenu est jugé insuffisant ou bloqué par des directives
- L'indexation ne garantit pas le classement — c'est la qualité du contenu et l'autorité qui déterminent la visibilité réelle
- Un diagnostic SEO efficace doit identifier à quelle étape le processus se bloque pour chaque page
Avis d'un expert SEO
Cette vision linéaire reflète-t-elle vraiment la complexité du système ?
Google présente un modèle simplifié qui fonctionne pour la majorité des cas. Mais la réalité terrain montre des exceptions — certaines pages sont explorées et indexées en quelques minutes, d'autres attendent des semaines malgré un sitemap propre et des liens internes cohérents.
Ce que Google ne détaille pas : les priorités d'exploration varient énormément selon l'autorité du domaine. Un site récent avec peu de backlinks peut voir ses nouvelles pages découvertes mais non explorées pendant des jours, tandis qu'un média d'actualité majeur voit ses contenus indexés quasi instantanément. [A vérifier] : Google reste évasif sur les critères précis qui déterminent la vitesse de passage entre chaque étape.
Les sitemaps XML sont-ils vraiment indispensables pour la découverte ?
Sur le papier, non. Google affirme que les liens internes suffisent. En pratique ? Les sitemaps accélèrent drastiquement la découverte, surtout sur les sites avec des milliers de pages ou une arborescence profonde.
J'ai observé des cas où des pages à 5 clics de la home restaient non découvertes pendant des mois, alors qu'une simple inclusion dans le sitemap déclenchait l'exploration sous 48h. Le sitemap ne contourne pas les limites de crawl budget, mais il signale explicitement les URL prioritaires à Google. Ignorer cet outil relève de l'amateurisme.
Faut-il bloquer certaines étapes volontairement ?
Oui, et c'est même recommandé dans certains contextes. Bloquer l'exploration via robots.txt économise du crawl budget pour les pages stratégiques — utile sur les gros sites e-commerce avec des milliers de variantes produit inutiles.
Bloquer l'indexation via noindex permet de garder des pages accessibles aux utilisateurs tout en évitant la pollution de l'index (pages de remerciement, contenus à faible valeur ajoutée, archives obsolètes). Mais attention : une page noindexée ne transmet pas de PageRank. Cette nuance échappe encore à beaucoup de praticiens qui noindexent à tort des pages stratégiques pour le maillage interne.
Impact pratique et recommandations
Que faut-il vérifier concrètement pour chaque étape ?
Pour la découverte : analysez vos sitemaps XML et votre maillage interne. Toute page stratégique doit être accessible en maximum 3 clics depuis la home. Utilisez la Search Console pour identifier les URL découvertes mais non explorées — c'est souvent le signe d'un problème de crawl budget ou de priorité.
Pour l'exploration : surveillez les temps de réponse serveur, les erreurs 5xx, et les directives robots.txt. Un serveur lent ou instable ralentit drastiquement l'exploration. Vérifiez aussi les logs serveur pour identifier les patterns d'exploration de Googlebot et détecter les sections de site ignorées.
Pour l'indexation : traquez les pages explorées mais non indexées dans la Search Console. Les causes fréquentes : contenu dupliqué, thin content, canonicalisation incorrecte, balises noindex accidentelles. Ne présumez jamais qu'une page explorée sera automatiquement indexée.
Comment prioriser l'action selon les blocages identifiés ?
Si vos pages ne sont pas découvertes : améliorez le maillage interne et soumettez un sitemap XML propre. Ajoutez des liens depuis vos pages stratégiques vers les contenus orphelins.
Si elles sont découvertes mais non explorées : le problème est probablement lié au crawl budget. Réduisez le nombre de pages inutiles explorées (filtres, paramètres URL, doublons), améliorez la vitesse serveur, et consolidez l'autorité du domaine via des backlinks de qualité.
Si elles sont explorées mais non indexées : concentrez-vous sur la qualité du contenu. Éliminez les duplications, enrichissez les pages thin, corrigez les canonicales erronées. Une page de 150 mots sans valeur ajoutée ne sera jamais indexée, quels que soient vos efforts techniques.
Quelles erreurs éviter absolument ?
- Ne pas bloquer l'exploration ET l'indexation simultanément via robots.txt + noindex — Google ne verra jamais la directive noindex
- Ne pas noindexer des pages stratégiques pour le maillage interne sous prétexte qu'elles ne génèrent pas de trafic direct
- Ne pas présumer que toutes les pages du sitemap seront explorées rapidement — surveiller les stats de la Search Console
- Ne pas ignorer les logs serveur qui révèlent les vraies priorités d'exploration de Googlebot
- Ne pas multiplier les variantes d'URL inutiles qui saturent le crawl budget sans valeur ajoutée
❓ Questions frequentes
Combien de temps faut-il entre la découverte et l'indexation d'une nouvelle page ?
Une page peut-elle être indexée sans apparaître dans les résultats de recherche ?
Le sitemap XML accélère-t-il vraiment la découverte des pages ?
Peut-on forcer Google à explorer une page plus rapidement ?
Pourquoi certaines pages sont explorées mais jamais indexées ?
🎥 De la même vidéo 6
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 19/03/2025
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.