Declaration officielle
Autres déclarations de cette vidéo 6 ▾
- □ Comment Google découvre-t-il réellement vos pages avant de les classer ?
- □ Le sitemap ne sert-il vraiment qu'à la découverte de vos URLs ?
- □ Pourquoi une page indexée n'apparaît-elle pas forcément dans les résultats Google ?
- □ Pourquoi une page indexée peut-elle rester invisible dans les résultats de recherche ?
- □ Pourquoi votre contenu indexé ne se classe-t-il toujours pas ?
- □ Google retire-t-il vraiment vos pages de l'index si personne ne clique dessus ?
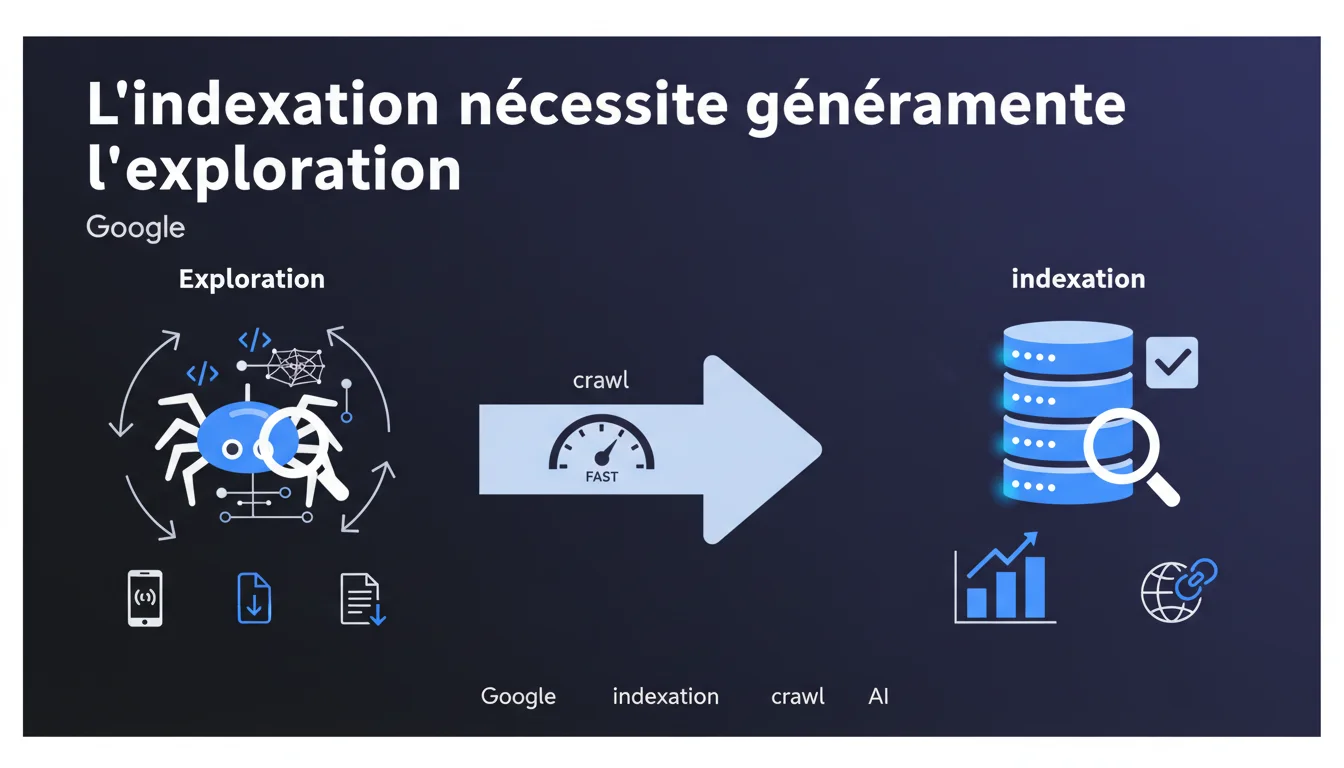
Google affirme qu'il doit généralement crawler une page avant de l'indexer, mais reconnaît l'existence d'exceptions. Dans la majorité des cas, l'exploration précède l'indexation — ce qui signifie que si Googlebot ne peut pas accéder à vos contenus, ils ne seront pas indexés. Les exceptions restent floues et Google ne détaille pas les contextes où elles s'appliquent.
Ce qu'il faut comprendre
Quelle est la relation exacte entre crawl et indexation ?
Google établit ici une hiérarchie claire : le crawl précède l'indexation dans la majorité des cas. Concrètement, Googlebot doit accéder au contenu de la page, analyser son HTML, interpréter les ressources (CSS, JS, images) pour comprendre ce qu'elle contient.
Sans cette phase d'exploration, le moteur ne dispose d'aucune donnée à indexer. C'est la base du fonctionnement de Google : pas de crawl, pas de visibilité dans les résultats de recherche.
Quelles sont ces fameuses exceptions dont parle Google ?
Google reste délibérément vague sur ce point. On sait qu'il peut indexer des URLs découvertes via des backlinks externes sans avoir visité la page — l'URL apparaît alors dans l'index avec un snippet générique.
Autre cas : les pages citées dans des sitemaps XML peuvent être temporairement indexées avant crawl complet. Mais ces situations restent marginales et souvent temporaires — Google finit généralement par crawler pour obtenir des données complètes.
Pourquoi cette déclaration maintenant ?
Cette affirmation rappelle un principe fondamental que beaucoup de sites négligent : optimiser le crawl budget et l'accessibilité technique. Trop de projets se concentrent sur le contenu en oubliant que si Googlebot ne peut pas y accéder efficacement, tout le reste est inutile.
Google réaffirme que le crawl reste le goulot d'étranglement principal de l'indexation. Si vos pages importantes ne sont pas crawlées régulièrement, elles ne peuvent pas être correctement indexées ni mises à jour dans les résultats.
- L'exploration précède l'indexation dans la majorité absolue des cas
- Des exceptions existent mais restent marginales et mal documentées
- Sans accès au contenu, Google ne peut pas indexer correctement
- Le crawl budget devient critique sur les sites de grande taille
- Les problèmes techniques bloquant le crawl impactent directement la visibilité
Avis d'un expert SEO
Cette déclaration apporte-t-elle vraiment du nouveau ?
Soyons honnêtes : non. Tout professionnel SEO sait depuis des années que le crawl précède l'indexation. Ce que Google fait ici, c'est réaffirmer un principe de base, probablement en réaction à des confusions observées chez des webmasters.
Le seul point intéressant reste cette mention d'exceptions — mais là encore, rien de concret. Google ne donne aucun critère précis pour identifier ces cas particuliers ni leur fréquence réelle. [À vérifier] : dans quelles proportions ces exceptions se produisent-elles réellement ? Google ne partage aucune donnée.
Les exceptions sont-elles exploitables en SEO ?
Dans la pratique terrain, compter sur ces exceptions relève du pari hasardeux. J'ai observé des cas où Google indexe temporairement une URL découverte via des liens externes, mais sans crawl complet, le snippet reste générique et le positionnement médiocre.
Ces indexations partielles disparaissent souvent lors des mises à jour d'index. Autrement dit : même si l'exception se produit, elle ne garantit ni qualité ni pérennité. Aucun professionnel sérieux ne devrait construire une stratégie SEO en comptant sur ces cas marginaux.
Quelle est la vraie priorité tactique ici ?
Ce que Google ne dit pas explicitement mais sous-entend : facilitez le crawl. Les sites qui négligent leur architecture technique, leur vitesse de réponse serveur, leur budget crawl sur les grosses arborescences — ceux-là perdent mécaniquement en visibilité.
Le vrai message derrière cette déclaration : arrêtez de vous concentrer uniquement sur le contenu et les backlinks. Si votre infrastructure technique freine Googlebot, tout le reste devient secondaire. Et c'est là que ça coince pour beaucoup de sites.
Impact pratique et recommandations
Que faut-il vérifier en priorité sur son site ?
Première étape : auditer l'accessibilité au crawl. Vérifiez que Googlebot peut atteindre vos pages stratégiques sans obstacle (robots.txt, redirections en chaîne, erreurs serveur 5xx, timeouts). Utilisez les logs serveur pour identifier les pages que Google crawle réellement vs celles qu'il ignore.
Deuxième point : optimisez votre maillage interne. Les pages orphelines ou situées à plus de 4 clics de la homepage sont rarement crawlées. Une architecture plate et logique facilite le travail de Googlebot et accélère l'indexation de vos contenus importants.
Quelles erreurs bloquent systématiquement le crawl ?
Les temps de réponse serveur trop longs (>500ms) ralentissent drastiquement le crawl. Google alloue un budget temps par site — si votre serveur est lent, moins de pages seront explorées par session.
Autre erreur classique : les paramètres d'URL mal gérés qui créent du contenu dupliqué infini. Googlebot gaspille son budget sur des variations inutiles au lieu de crawler vos pages stratégiques. Utilisez la Search Console pour identifier ces pièges.
Comment prioriser les pages à crawler ?
Le sitemap XML reste votre meilleur outil de priorisation. Incluez uniquement vos pages stratégiques (celles qui génèrent du business), excluez les contenus annexes. Mettez à jour la balise <lastmod> uniquement lors de modifications substantielles — pas à chaque session utilisateur.
Utilisez les données structurées et le maillage interne pour signaler l'importance relative de vos pages. Google crawle plus fréquemment les URLs vers lesquelles pointent de nombreux liens internes de qualité.
- Vérifier les logs serveur pour identifier les problèmes de crawl réels
- Corriger les erreurs 4xx/5xx qui bloquent l'accès aux contenus stratégiques
- Optimiser les temps de réponse serveur (cible :
❓ Questions frequentes
Google peut-il indexer une page sans jamais la crawler ?
Combien de temps faut-il à Google pour crawler une nouvelle page ?
Le sitemap XML force-t-il Google à crawler mes pages ?
Pourquoi certaines pages indexées n'apparaissent pas dans mes logs serveur ?
Faut-il bloquer les pages peu importantes pour économiser le crawl budget ?
🎥 De la même vidéo 6
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 19/03/2025
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.