Official statement
Other statements from this video 10 ▾
- □ Google corrige-t-il vraiment vos erreurs HTML pour l'indexation ?
- □ Une balise non supportée dans <head> peut-elle vraiment casser toutes vos métadonnées SEO ?
- □ Comment Google choisit-il quelle version d'une page en double indexer ?
- □ Comment Google choisit-il quelle page indexer parmi vos contenus dupliqués ?
- □ Comment Google regroupe-t-il vraiment les pages au contenu similaire ?
- □ Pourquoi Google accorde-t-il plus de poids à certains signaux SEO qu'à d'autres ?
- □ Comment Google choisit-il LA page canonique dans un cluster de doublons ?
- □ Google sert-il vraiment des versions alternatives de vos pages selon le contexte de recherche ?
- □ Comment Google décide-t-il vraiment si votre page mérite l'index ?
- □ Qu'est-ce que Google stocke vraiment dans son index pour une page canonique ?
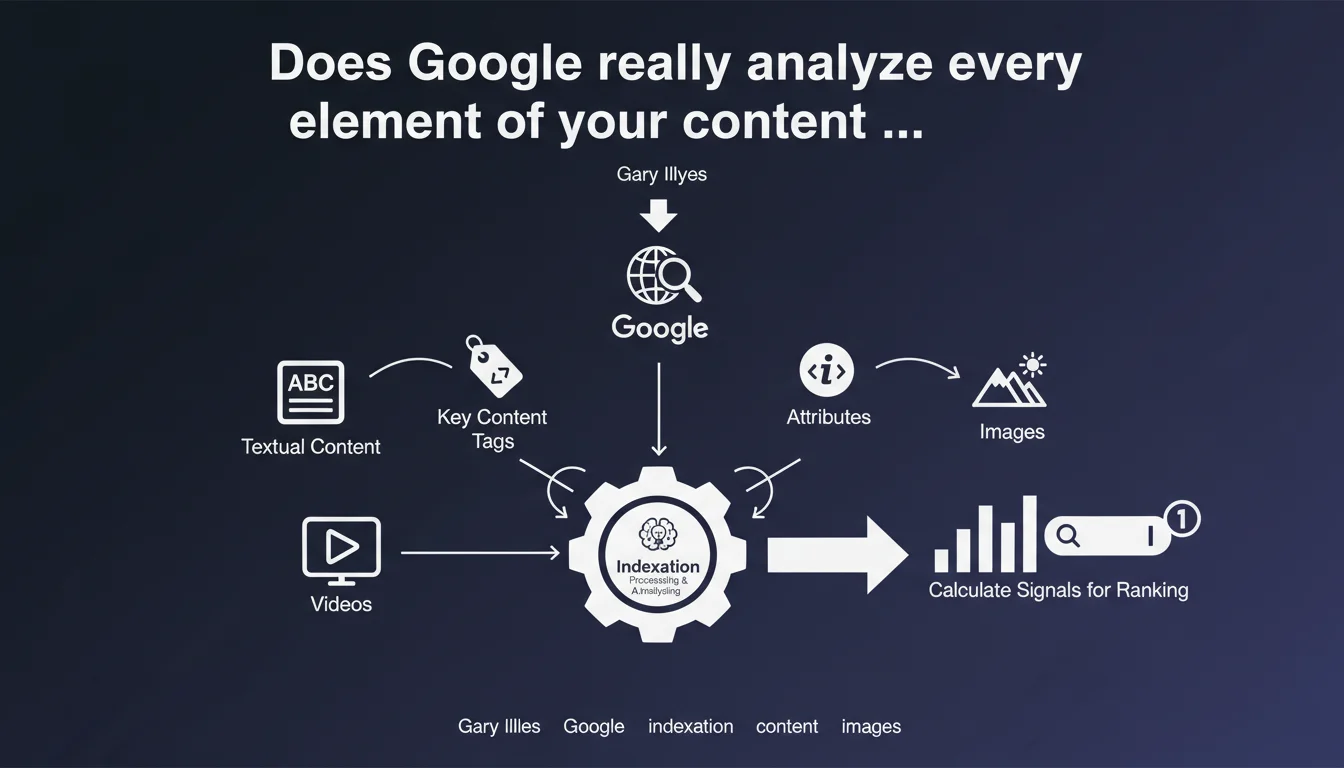
Google analyzes far more than text during indexation: key content tags, attributes, images, and videos are all processed to calculate ranking signals. This statement confirms that indexation is a multi-dimensional analysis process, not just simple text reading. SEO practitioners must optimize all these elements simultaneously.
What you need to understand
What exactly happens during indexation?
Indexation is not simply storing content. Google processes and analyzes every element of your pages to extract signals usable for ranking. Text, HTML tags, attributes, media — all go through this process.
Gary Illyes clarifies that this analysis goes beyond visible textual content. Key content tags (title, h1-h6, meta description, alt text) and attributes (schema markup, image attributes, data attributes) are scrutinized. Images and videos are not ignored: they contribute to the overall understanding of the page.
What signals are calculated from this analysis?
Google doesn't detail the exhaustive list, but we know that indexation generates thematic relevance signals, content quality, and semantic structure. These signals then feed ranking algorithms.
Concretely? The engine identifies entities, main topics, information hierarchy, and multimedia richness. Each analyzed element contributes to a composite score that determines whether your page deserves to appear for a given query.
Why is this statement important for practitioners?
It confirms that SEO optimization cannot be limited to textual content. An article perfectly written but with poorly structured tags or unoptimized images loses points during indexation.
Let's be honest: many sites still neglect alt attributes, schema tags, or semantic HTML structure. This statement reminds us that these elements are not optional — they are actively processed and taken into account.
- Indexation analyzes text, key HTML tags, attributes, and media
- Each element generates signals used for ranking in results
- Optimizing text alone is insufficient: structure and media matter just as much
- Schema tags, alt text, and heading hierarchy are not cosmetic — they influence indexation
SEO Expert opinion
Is this statement consistent with what we observe in practice?
Yes, absolutely. A/B tests clearly show that pages identical in textual content but different in HTML structure or media optimization do not rank the same way. The impact of schema tags on the appearance of rich snippets is visible proof of this.
What's interesting is that Gary Illyes doesn't prioritize these elements. He doesn't say "text first, then tags." All are processed in the same analysis process. This suggests a holistic approach — not a points system where text would be worth 80% and the rest 20%.
What areas of uncertainty remain in this statement?
Google remains vague about the relative weighting of these signals. Does excellent markup compensate for mediocre text? Probably not. But to what extent does each element weigh in? [To verify] — no official data on this point.
Another gray area: when Illyes talks about "key content tags," which tags exactly? Are meta keywords included (spoiler: no, but it's not said here)? Are custom data attributes taken into account? The statement remains superficial.
In what cases does this logic not fully apply?
For very specific content — for example automatically generated legal pages or ultra-standardized product listings — differentiation through tags and attributes can have limited impact. If 10,000 competing pages have exactly the same structure and tags, Google will have to decide based on other criteria (backlinks, domain authority, user signals).
Similarly, in ultra-competitive markets where all players already master these fundamentals, the marginal advantage of perfect tag optimization is reduced. The differentiator then becomes unique informational quality or external signals.
Practical impact and recommendations
What exactly needs to be optimized following this statement?
Start with an audit of your key content tags: title, h1-h6, meta description, alt text on all images. Make sure they are present, unique per page, and clearly reflect the main topic.
Next, verify your attributes and structured markup. Is Schema.org implemented correctly? Are structured data validated without errors in Search Console? Are ARIA attributes for accessibility in place?
For media, each image must have a descriptive alt attribute, an optimized filename, and ideally be served in modern format (WebP, AVIF). Videos should be accompanied by transcripts or subtitles — Google can analyze them.
What common mistakes should you avoid?
Don't duplicate title tags or h1 across multiple pages. Google analyzes these signals to understand the uniqueness of each piece of content. Duplicates weaken this understanding and dilute perceived relevance.
Also avoid empty or generic tags. An alt="image" or h2="Section" provides no useful signal. It's noise that pollutes the analysis. Be descriptive and specific.
And that's where it often goes wrong: over-optimization. Stuffing attributes with keywords or creating unnecessary schema tags to "inflate signals" is counterproductive. Google detects abnormal patterns. Stay natural.
How do you verify that your site meets these requirements?
Use Google Search Console to detect structured data errors. The "Enhancements" tab alerts you to schema markup problems.
Crawl your site technically with Screaming Frog or Oncrawl to identify pages without title, without h1, or with images lacking alt text. Export a report and address critical anomalies page by page.
Also test the mobile version of your pages with Google's Mobile-Friendly Test tool. Are tags and attributes properly present and analyzable on mobile? Mobile-first indexation requires this consistency.
- Audit all title tags, h1-h6 headings, meta descriptions, and alt text
- Implement or correct Schema.org markup (Article, Product, FAQ, etc.)
- Optimize image filenames and alt attributes
- Add transcripts or subtitles to videos
- Check for absence of duplicate tags between pages
- Test structured data in Search Console
- Crawl the site to detect pages with missing tags
- Validate tag and attribute consistency between mobile and desktop
❓ Frequently Asked Questions
Google indexe-t-il le contenu des images sans attribut alt ?
Les balises meta keywords sont-elles encore analysées lors de l'indexation ?
Les attributs schema.org influencent-ils le classement organique ou seulement l'affichage des rich snippets ?
Faut-il optimiser les attributs de toutes les images ou seulement celles qui sont importantes ?
Les vidéos YouTube intégrées sur mon site sont-elles analysées lors de l'indexation de ma page ?
🎥 From the same video 10
Other SEO insights extracted from this same Google Search Central video · published on 04/04/2024
🎥 Watch the full video on YouTube →
💬 Comments (0)
Be the first to comment.