Official statement
Other statements from this video 10 ▾
- □ Comment Google analyse-t-il vraiment votre contenu lors de l'indexation ?
- □ Google corrige-t-il vraiment vos erreurs HTML pour l'indexation ?
- □ Une balise non supportée dans <head> peut-elle vraiment casser toutes vos métadonnées SEO ?
- □ Comment Google choisit-il quelle version d'une page en double indexer ?
- □ Comment Google choisit-il quelle page indexer parmi vos contenus dupliqués ?
- □ Pourquoi Google accorde-t-il plus de poids à certains signaux SEO qu'à d'autres ?
- □ Comment Google choisit-il LA page canonique dans un cluster de doublons ?
- □ Google sert-il vraiment des versions alternatives de vos pages selon le contexte de recherche ?
- □ Comment Google décide-t-il vraiment si votre page mérite l'index ?
- □ Qu'est-ce que Google stocke vraiment dans son index pour une page canonique ?
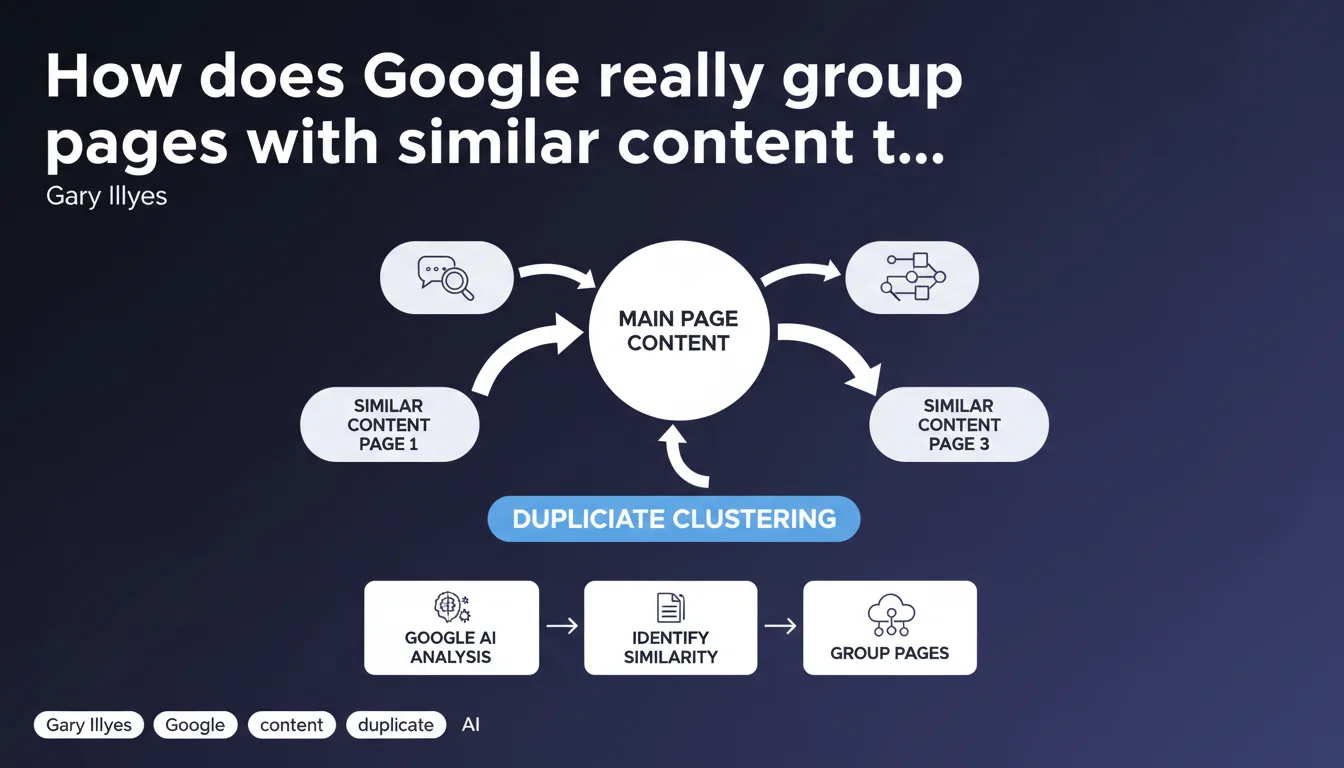
Google uses a process called duplicate clustering to group pages whose main content is similar. In practice, a page can be merged with others if their content is deemed nearly identical, which directly impacts indexation and visibility in search results. The engine only retains one canonical version among these detected duplicates.
What you need to understand
What exactly is duplicate clustering?
Duplicate clustering is the mechanism by which Google identifies and groups pages whose main content is similar. Pay attention: we're talking about main content here, not the entire page. Minor variations in sidebars, footers, or headers generally aren't enough to differentiate two pages in Google's eyes.
Once grouped, these pages are treated as variants of the same entity. Google then selects a canonical version that it will prioritize in the index, even if technically all URLs in the cluster are known to the engine.
Why does Google do this?
The answer comes down to two words: algorithmic efficiency. Indexing and ranking multiple nearly-identical versions of the same content would be a waste of computational resources. By clustering duplicates, Google optimizes its crawl budget and avoids polluting its indexes with redundant content.
For the end user, this also prevents displaying 10 nearly identical results on the same SERP. Clustering theoretically improves the diversity of results offered.
What's the difference from the canonical tag?
The canonical tag is a hint you give to Google about your preferred version of content. Duplicate clustering, on the other hand, is an automatic process that happens on Google's side, with or without your input.
Google can easily ignore your canonicals and apply its own clustering based on its perception of the content. In other words: you suggest, Google decides. And it doesn't always notify you of its choices.
- Duplicate clustering analyzes the main content of pages, not their overall structure
- Google automatically groups similar pages and chooses a canonical version for indexation
- This process is distinct from the canonical tag that you implement manually
- Clustering aims to optimize index efficiency and SERP quality
- Grouped pages remain technically known to Google but only the canonical version is prioritized
SEO Expert opinion
Is this statement consistent with real-world observations?
Broadly yes, but with substantial gray areas. We do observe that Google can ignore our canonical directives and choose alternative versions. The problem: Gary Illyes doesn't specify the similarity thresholds that trigger this clustering. [To verify]: from what percentage of identical content are two pages considered duplicates?
Tests show that two pages with 70-80% shared content can be clustered, but this isn't systematic. Content freshness, page authority, user signals — all of this seems to influence the final decision. Google provides no precise formula, which complicates auditing.
What are the blind spots in this statement?
Gary Illyes remains silent on several critical points. First, how does Google determine which page becomes the canonical version of the cluster? Is it the first crawled, the one with the most authority, the one that performs best? Radio silence.
Next, no mention of differentiated treatment based on site types. Will an e-commerce site with nearly-identical product sheets (only the color changes) be treated the same as a blog republishing the same article? Probably not, but Google doesn't say so explicitly.
In what cases does this mechanism really cause problems?
Sites with legitimate content variants are the first affected. Think of multilingual sites with approximate auto-translation, e-commerce platforms with product variations, or offer aggregators that republish syndicated content.
If Google clusters your pages and systematically chooses a sub-optimal version (parametric URL, poorly-structured mobile version, page with fewer backlinks), you lose visibility without having made a technical error. And you'll receive no notification in Search Console to warn you.
Practical impact and recommendations
How do you verify if your pages are affected by clustering?
First method: the site: search operator. Search "site:yourdomain.com + exact page title" and compare the returned URLs. If Google displays a different version from the one you want indexed, it's probably clustering in action.
Second approach: analyze your server logs. If Google crawls certain URLs but they never appear in the index (verifiable via Search Console), they might be clustered with other pages. Caution: this could also indicate a crawl budget or quality issue.
What concrete actions can you take to control clustering?
Start by genuinely differentiating content that should be different. If you have 50 product pages where only the color changes, add unique descriptions, customer-specific reviews, differentiated usage guides. The more main content diverges, the less likely Google will cluster them.
Next, use canonical tags consistently. Even if Google can ignore them, they remain a strong signal. Make sure they point to the version you actually want indexed — not a parameterized URL or an alternative mobile version.
Finally, leverage strategic internal linking. The version you want to see canonicalized should receive more internal links with relevant anchor text. Google uses these signals to determine which page has the most weight within a potential cluster.
- Audit your similar content with the site: operator and compare indexed URLs versus desired ones
- Analyze your logs to identify pages crawled but absent from the index (possible clustering victims)
- Differentiate main content of legitimately distinct pages with unique and enriched descriptions
- Implement consistent canonicals pointing to your priority versions
- Strengthen internal linking to the pages you want prioritized in the index
- Regularly check in Search Console which URLs are actually indexed
- Remove or consolidate pages with truly duplicated content offering no added value
❓ Frequently Asked Questions
Le duplicate clustering est-il une pénalité Google ?
Google respecte-t-il toujours les balises canonical que j'implémente ?
Comment savoir quelle page Google a choisi comme canonique dans un cluster ?
Deux pages avec 50% de contenu identique seront-elles clustérisées ?
Le clustering affecte-t-il différemment les sites e-commerce et les blogs ?
🎥 From the same video 10
Other SEO insights extracted from this same Google Search Central video · published on 04/04/2024
🎥 Watch the full video on YouTube →
💬 Comments (0)
Be the first to comment.