Official statement
Other statements from this video 10 ▾
- □ Comment Google analyse-t-il vraiment votre contenu lors de l'indexation ?
- □ Google corrige-t-il vraiment vos erreurs HTML pour l'indexation ?
- □ Une balise non supportée dans <head> peut-elle vraiment casser toutes vos métadonnées SEO ?
- □ Comment Google choisit-il quelle version d'une page en double indexer ?
- □ Comment Google choisit-il quelle page indexer parmi vos contenus dupliqués ?
- □ Comment Google regroupe-t-il vraiment les pages au contenu similaire ?
- □ Pourquoi Google accorde-t-il plus de poids à certains signaux SEO qu'à d'autres ?
- □ Google sert-il vraiment des versions alternatives de vos pages selon le contexte de recherche ?
- □ Comment Google décide-t-il vraiment si votre page mérite l'index ?
- □ Qu'est-ce que Google stocke vraiment dans son index pour une page canonique ?
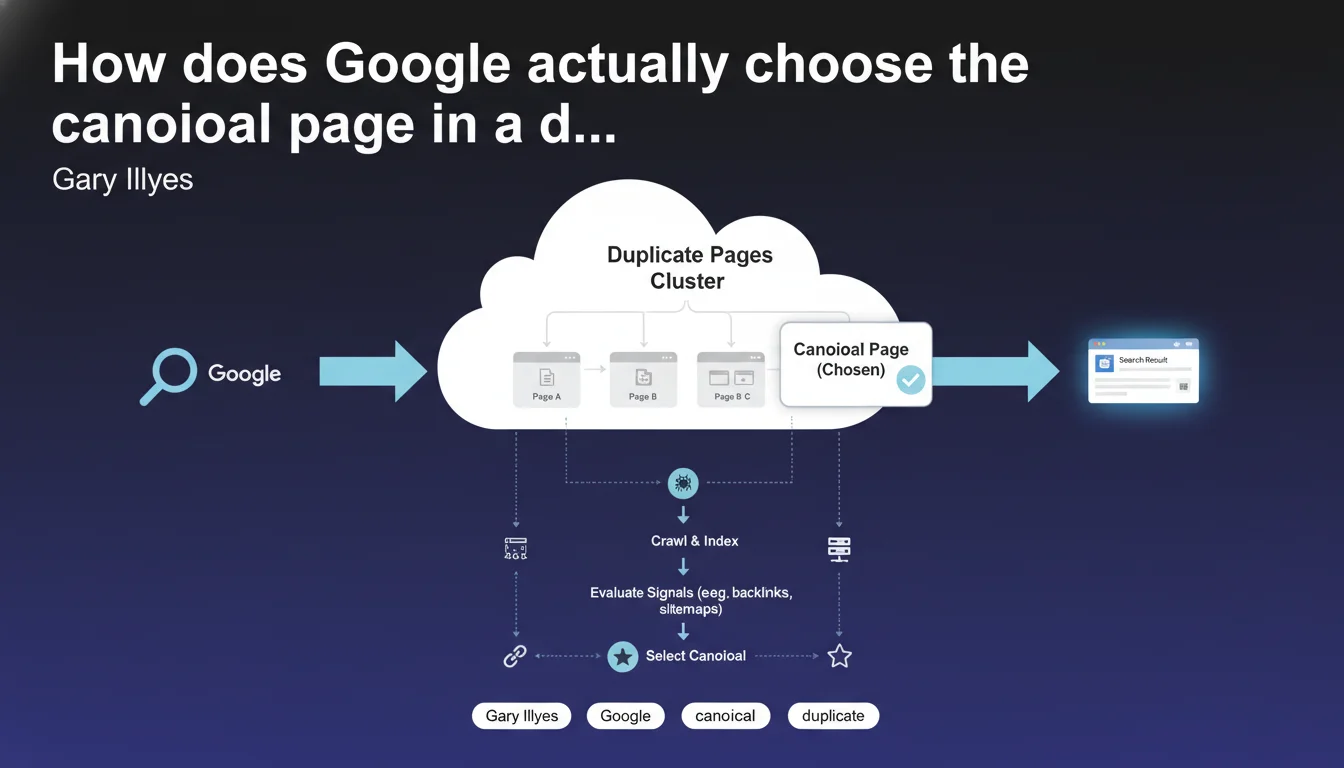
Google keeps only one canonical version per cluster of duplicate pages. This single page will represent all cluster content in the SERPs. Other versions in the cluster are excluded from primary indexing — which means choosing the right canonical isn't optional, it's a strategic necessity.
What you need to understand
What is a duplicate cluster according to Google?
A duplicate cluster groups all URLs that Google considers similar enough to be treated as variations of the same content. This includes exact duplications (same words, same structure) but also near-duplicates — pages with minor title variations, a few reworded sentences, or reorganized content blocks.
Google doesn't publish a precise similarity threshold. We know the algorithm tolerates slight differences (URL parameters, separate mobile/desktop versions, approximate machine translations). However, once the engine detects substantial redundancy, it merges these URLs into the same cluster and forces canonicalization.
Why does Google impose a single canonical version?
Historically, indexing multiple versions of the same content dilutes relevance and wastes crawl budget. Google prefers to concentrate its energy on unique content rather than crawling 15 variations of the same product page.
The other reason — often underestimated — is user experience. If Google displayed three nearly identical URLs from the same site in the SERPs, users would waste time comparing redundant pages. Canonicalization forces a consolidation of signals (backlinks, CTR, anchor text) on a single URL, which theoretically strengthens its authority.
How does Google select this canonical version?
Google crosses several signals: the rel=canonical tag declared in the HTML, 301 redirects, XML sitemaps, internal link consistency, and even external backlinks pointing to a specific URL.
But — and this is where it gets tricky — Google doesn't always follow your instructions. If your canonical tag points to URL A, but 80% of your backlinks point to URL B, Google may decide to canonicalize B. It's probabilistic logic, not binary.
- The canonical tag is a strong signal, but not an absolute instruction
- External backlinks carry significant weight in Google's final choice
- Internal linking should predominantly point to the version you want canonicalized
- XML sitemaps should list only canonical URLs
- Google can ignore your signals if another URL in the cluster seems more relevant or better optimized
SEO Expert opinion
Is this statement consistent with real-world practices?
Yes and no. The theory is clear: one cluster = one canonical. In practice, I've seen sites with unstable canonicalizations — Google switches the canonical version month after month, sometimes for no apparent reason. This phenomenon is frequent on e-commerce sites with poorly managed facet filters.
You must also distinguish between voluntary canonicalizations (you explicitly declare a canonical) and imposed canonicalizations (Google decides alone, often because your signals are contradictory). In the latter case, you lose control — and it's rarely in your favor.
What nuances should be added to this rule?
Google talks about "each cluster," but doesn't specify how it defines cluster boundaries. Are two pages with 70% common content in the same cluster? And if they target different search intentions? [To be verified] on edge cases — third-party tools (Screaming Frog, Oncrawl) detect duplicates using arbitrary thresholds, but Google has its own internal criteria.
Another point: Gary talks about "search results," but what about featured snippets, carousels, People Also Ask? Can a non-canonical URL appear in these enriched blocks? The wording remains vague. In practice, I've observed cases where a URL declared non-canonical still appeared in a PAA — probably because Google found it more relevant for that specific question.
In what cases does this rule not apply strictly?
Multilingual and multi-regional sites represent a partial exception. If you use hreflang correctly, Google can index multiple versions of the same page (FR, EN, ES) without treating them as duplicates — each will be canonical for its language/region. But be careful: if hreflang is poorly implemented, Google reverts to cluster logic and imposes an arbitrary canonical.
Practical impact and recommendations
What concrete steps should you take to master canonicalization?
First step: audit your existing duplicate clusters. Use Google Search Console (Coverage tab > "Excluded") to identify URLs marked as "Duplicate, page not selected as canonical." Compare with your intentions: did Google choose the right version?
Next, harmonize your signals. If you want page A to be canonical, ensure that: (1) the canonical tag points to A on all cluster variants, (2) your internal linking predominantly points to A, (3) A is listed in your XML sitemap and the others aren't, (4) you 301 redirect obsolete URLs to A if they no longer have a reason to exist.
For sites with dynamic URL parameters (tracking, filters), configure the parameter handling tool in Search Console — this helps Google avoid creating parasitic clusters.
What mistakes should you absolutely avoid?
Never declare a looping canonical (page A points to B, B points to C, C points to A). Google ignores this type of configuration and chooses itself, usually poorly.
Avoid reckless cross-domain canonicals. If you syndicate content on another site, the canonical should point to the source URL — but Google can still index the syndicated version if it receives more backlinks. This isn't an absolute guarantee.
Watch out for automatically generated URL facets (filters, sorting, pagination). If each combination creates a unique URL without a canonical tag, you generate hundreds of clusters — and Google will canonicalize unpredictably, often penalizing your strategic pages.
How can you verify that your site is compliant?
- Crawl the site with Screaming Frog or Oncrawl — identify all URLs declaring a canonical different from their own URL
- Check Google Search Console for "Excluded" URLs due to duplicates — compare with your SEO intentions
- Verify that each strategic page receives at least 70% of internal links within the cluster (if multiple variants exist)
- Test canonical tags by inspecting source code (not just via tools) — some JavaScript implementations cause issues
- Monitor canonicalization fluctuations using a tool like OnCrawl or Botify — detect monthly switches
- Clean up XML sitemaps: list only canonical URLs, remove all variants
- If you use hreflang, audit the consistency of declarations (each version should have reciprocal hreflang)
❓ Frequently Asked Questions
Google peut-il indexer deux URLs d'un même cluster de doublons ?
Que se passe-t-il si je déclare une canonical vers une URL inexistante ou en erreur 404 ?
Est-ce que supprimer une balise canonical empêche Google de créer un cluster ?
Les backlinks vers une URL non-canonique sont-ils perdus ?
Peut-on forcer Google à changer de version canonique après coup ?
🎥 From the same video 10
Other SEO insights extracted from this same Google Search Central video · published on 04/04/2024
🎥 Watch the full video on YouTube →
💬 Comments (0)
Be the first to comment.