Official statement
Other statements from this video 8 ▾
- □ Faut-il optimiser son site différemment pour AI Overviews et AI Mode ?
- □ Faut-il adapter sa stratégie SEO pour les fonctionnalités IA de Google ?
- □ Les clics depuis AI Overviews convertissent-ils vraiment mieux ?
- □ Les AI Overviews favorisent-elles vraiment une plus grande diversité de sites ?
- □ Pourquoi Google insiste-t-il autant sur la « valeur unique » du contenu ?
- □ Les recommandations Search Console sur Core Web Vitals vont-elles enfin servir à quelque chose ?
- □ L'analyse des logs est-elle vraiment la compétence SEO qui survivra à tout ?
- □ Faut-il arrêter de parler de SEO et adopter les nouveaux termes AIO, GEO ou optimisation pour LLM ?
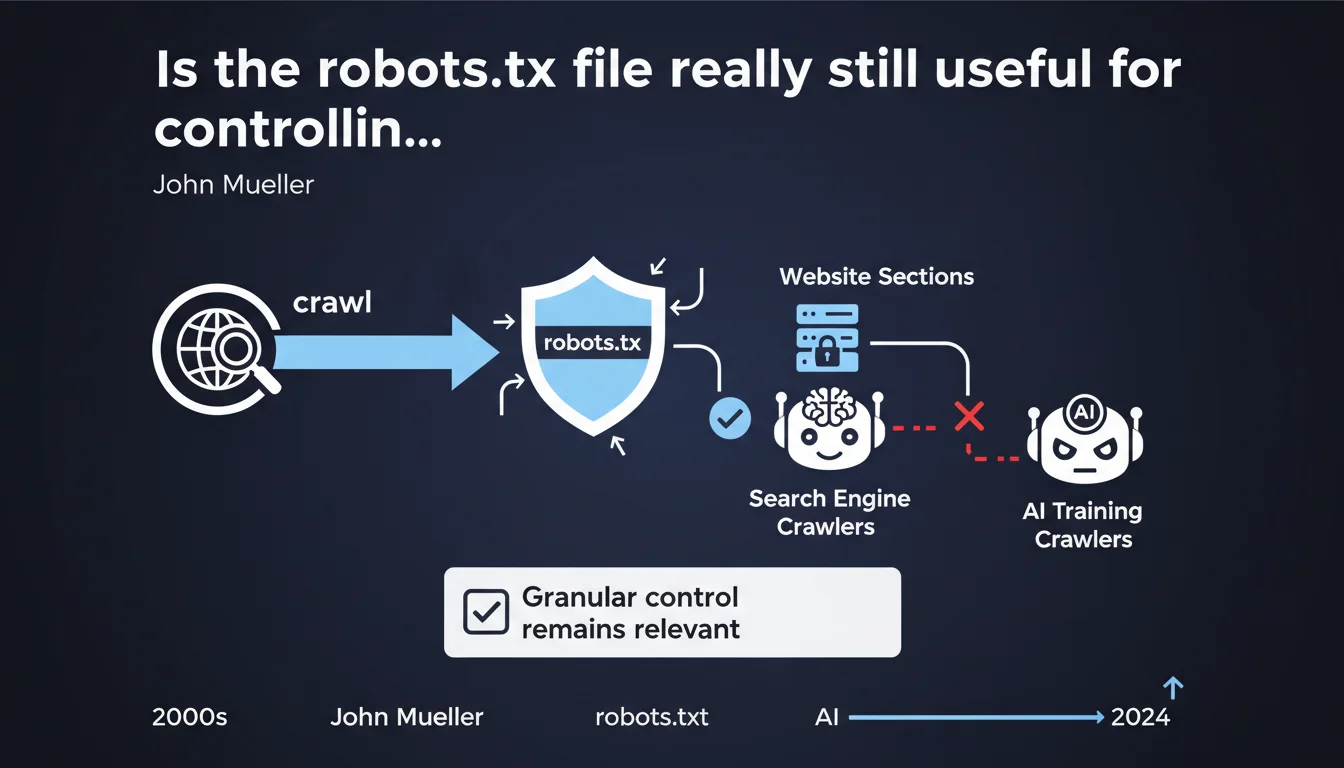
Google confirms that the robots.txt file remains a relevant tool for controlling access to crawlers, including those dedicated to training AI models. Web masters therefore retain a granular lever to manage what is accessible or not, beyond simple traditional search engine optimization.
What you need to understand
Why is Google still insisting on robots.txt?
The robots exclusion protocol has existed for over 30 years, and one might have thought that with the evolution of technologies and APIs, this archaic text file would have lost its appeal. Yet John Mueller reaffirms its importance.
The reason? The explosion of non-SEO crawlers, particularly those dedicated to scraping content to train generative AI models. The robots.txt becomes a bulwark — albeit imperfect — against these new forms of data harvesting.
What concretely changes with AI?
Until recently, robots.txt primarily served to manage crawl budget and avoid indexing unnecessary pages. Now it also serves to block bots from OpenAI, Anthropic, Google Bard, and other players scraping the web to feed their LLMs.
The problem is that not all crawlers respect this file. Some deliberately ignore the directives, others change their user-agent to bypass the blocks. So we're looking at theoretical control rather than real control.
What are the limits of this granular control?
Google speaks of "granular" control, but let's be honest: robots.txt only allows you to block or allow directories or files. No nuance, no conditions.
Moreover, blocking an AI crawler does not protect content already scraped. If your site was crawled before you added a directive, it's too late. The robots.txt file is not retroactive.
- The robots.txt remains a recognized standard by the majority of legitimate crawlers
- It allows you to specifically block AI crawler user-agents (ex: GPTBot, Google-Extended, CCBot)
- Its respect depends entirely on the goodwill of the crawler — no technical guarantee
- It does not protect against crawlers that spoof their user-agent
- Directives only apply to future visits, not to data already collected
SEO Expert opinion
Is this statement consistent with field observations?
Yes and no. In the classic SEO ecosystem, robots.txt works well: Googlebot, Bingbot and their peers meticulously respect directives. No issues there.
Where it breaks down is with less scrupulous third-party crawlers. Log analysis shows that some bots continue crawling blocked sections by changing their user-agent or using proxies. The "granular control" touted by Google is therefore only real for players who play by the rules.
What nuances must be added to this discourse?
Google positions robots.txt as a universal solution, but omits to mention its weaknesses. A poorly configured robots.txt file can block critical resources (CSS, JS) and harm page rendering on Googlebot's side.
Another point: blocking AI crawlers via robots.txt means giving up any visibility in summaries generated by AI. If tomorrow Google Search Generative Experience or ChatGPT become major acquisition channels, having blocked these bots could prove counterproductive. [To verify] in the long term.
In what cases does this rule not apply?
If your goal is to legally protect your content against AI scraping, robots.txt is not enough. It has no binding contractual value — it's just a "gentleman's agreement".
For real protection, you must combine multiple levers: explicit terms of use, content watermarking, server-side rate limiting, and potentially legal action. robots.txt alone protects nothing legally.
Practical impact and recommendations
What should you do concretely right now?
First step: audit your current robots.txt file. Verify that it doesn't accidentally block resources necessary for rendering (JS, CSS, critical images). Google Search Console will alert you if that's the case.
Next, decide whether you want to block AI crawlers. If yes, add specific directives for each user-agent of concern (GPTBot, Google-Extended, CCBot, anthropic-ai, etc.). If not, let them crawl — you could benefit from citations in generated responses.
What critical mistakes should you absolutely avoid?
Mistake #1: blocking Googlebot on pages you want indexed. This happens more often than you'd think, especially after redesigns where you forget to clean up old directives.
Mistake #2: believing that "Disallow: /" in robots.txt removes pages from the index. No. It prevents crawling, but Google can still index URLs via external backlinks. To truly de-index, you need a noindex tag.
Mistake #3: not monitoring server logs after making changes. Some crawlers ignore robots.txt and continue hogging your resources. Without log analysis, you'll never notice.
How do you verify that everything is properly configured?
Use the robots.txt test tool in Google Search Console. It shows you in real time which URLs are blocked for Googlebot. Also test with different user-agents to see behavior.
For AI crawlers, the only reliable verification comes through server log analysis. Look for suspicious user-agents and verify if they respect your directives. If not, consider blocking at the firewall IP level.
- Audit existing robots.txt via Google Search Console
- Verify that no critical resources (CSS, JS) are blocked
- Add specific directives for AI crawlers if desired
- Test the file with multiple user-agents
- Monitor server logs to detect non-compliant crawlers
- Document each robots.txt modification (date, reason, impact)
- Set up alerts if crawl rate spikes
❓ Frequently Asked Questions
Bloquer les crawlers IA via robots.txt empêche-t-il mon contenu d'être utilisé pour l'entraînement ?
Peut-on bloquer Googlebot pour l'IA tout en restant crawlé pour le SEO classique ?
Un robots.txt mal configuré peut-il faire chuter mon trafic SEO ?
Le robots.txt protège-t-il juridiquement contre le scraping non autorisé ?
Faut-il bloquer tous les crawlers IA ou laisser faire ?
🎥 From the same video 8
Other SEO insights extracted from this same Google Search Central video · published on 01/07/2025
🎥 Watch the full video on YouTube →
💬 Comments (0)
Be the first to comment.