Official statement
Other statements from this video 12 ▾
- □ Faut-il vraiment doubler les données produits entre le site et Merchant Center ?
- □ Pourquoi Google préfère-t-il les flux Merchant Center au crawl classique pour vos données produits ?
- □ Merchant Center peut-il vraiment booster le crawl de vos fiches produits ?
- □ Comment vérifier l'indexation d'une page : l'outil d'inspection ou l'opérateur site: ?
- □ Pourquoi Google exige-t-il à la fois des données structurées ET Merchant Center pour afficher les prix correctement ?
- □ Les incohérences de prix entre votre site et Merchant Center peuvent-elles vraiment plomber votre visibilité produit ?
- □ Faut-il augmenter la fréquence de traitement des flux Google Merchant Center pour améliorer son référencement ?
- □ Les mises à jour automatiques dans Merchant Center peuvent-elles corriger vos données produits sans intervention manuelle ?
- □ Faut-il vraiment cumuler données structurées ET flux Merchant Center pour les résultats enrichis produits ?
- □ Les résultats enrichis sont-ils vraiment à la discrétion totale de Google ?
- □ Pourquoi les erreurs Search Console et Merchant Center sabotent-elles vos résultats shopping ?
- □ Pourquoi les données structurées produit ne suffisent-elles pas pour apparaître dans l'onglet Shopping ?
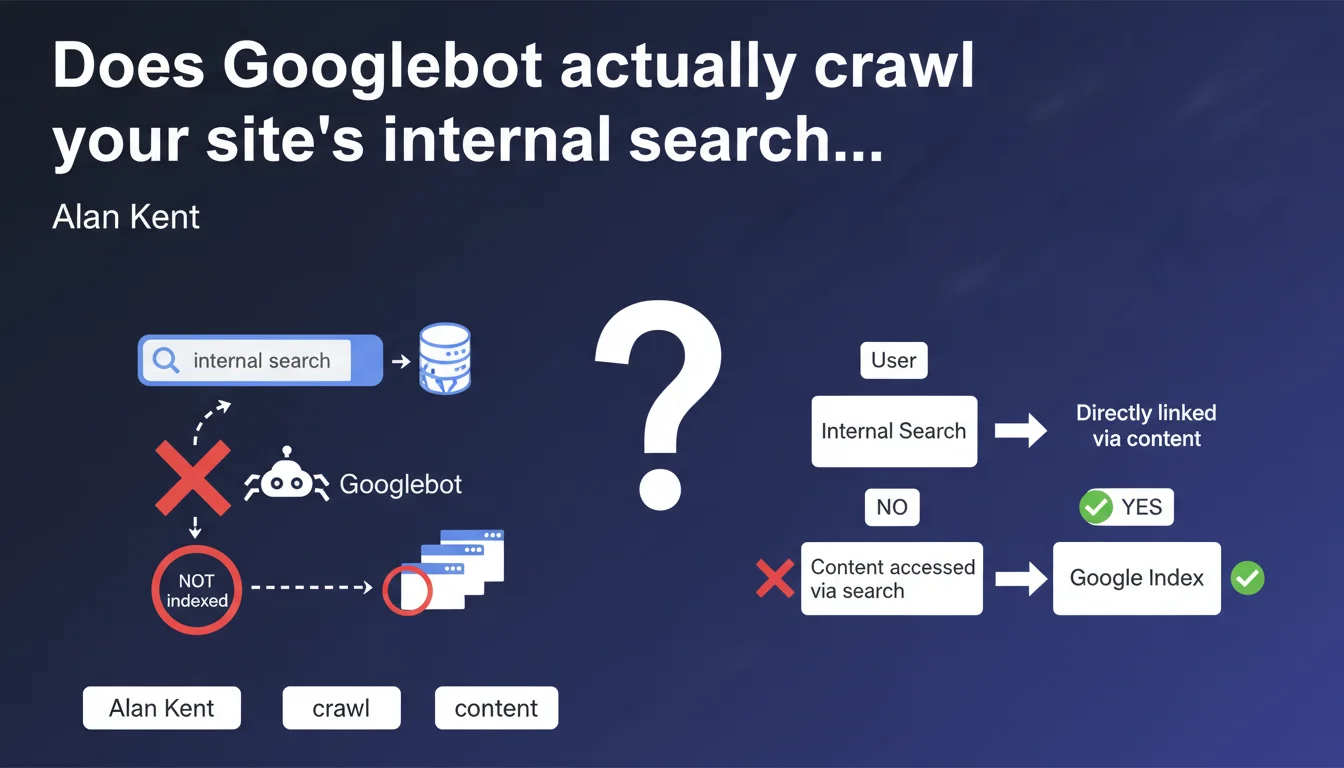
Google does not enter search terms in internal search bars to discover content. If products or pages are only accessible through your internal search engine, they risk never being indexed. This means fundamentally rethinking your navigation architecture for sites that rely on internal search as the primary means of accessing content.
What you need to understand
Why is this statement critical for your site architecture?
Alan Kent clarifies a point that many developers and e-commerce managers underestimate: Googlebot does not fill out search forms. Concretely, if you have a catalog of 50,000 items and 10,000 of them are only accessible through internal search — because they don't appear in any category, menu, or navigable filter — those pages simply don't exist for Google.
This is particularly critical for sites that have developed sophisticated internal search engines but neglected traditional navigation paths. A niche product, an old blog post, a landing page created for a specific campaign: if they're only accessible through internal search, they disappear from Google's radar.
How does Googlebot actually discover pages?
Google relies on standard HTML links: main navigation, category menus, faceted filters, internal linking, XML sitemaps, external links. Anything requiring complex JavaScript interaction or user input is ignored.
This means your crawlability strategy must ensure every important URL is reachable through at least one path of static links. Sitemaps help, but they don't compensate for fundamentally flawed architecture.
- Search forms are not crawled — Googlebot does not enter search queries, activate autocomplete, or submit forms.
- Orphaned pages are invisible — If a page has no incoming links (internal or external) and isn't in a sitemap, it doesn't exist for Google.
- Complex JavaScript filters cause problems — Facets that generate URLs only through JS risk not being discovered, even if they're technically crawlable afterward.
- XML sitemaps remain a safety net — But they don't guarantee indexation, only potential discovery.
What are the concrete consequences of this limitation?
E-commerce sites with deep catalogs are hit first. Imagine a site organizing 100,000 SKUs across 50 main categories, but 30% of items don't appear in any category because they're "too specific." If these products are only accessible through internal search, they'll never generate organic traffic.
Content sites are also affected. A blog with 5,000 articles where 2,000 aren't linked anywhere except through internal search loses a massive portion of its SEO potential. Even with an exhaustive sitemap, the lack of internal linking significantly weakens their ranking ability.
SEO Expert opinion
Is this statement consistent with real-world observations?
Absolutely. It's even an official confirmation of what SEO practitioners have observed for years. Sites that rely on internal search to "compensate" for failed navigation systematically encounter massive indexation problems.
I've seen audits where 40% of a site's URLs were discovered by no external crawler, simply because they were orphaned and only accessible through search. The sitemap listed them, but Google ignored them or indexed them with a delay of several months — and with no internal authority to support them.
What nuances should be added to this statement?
Alan Kent's statement speaks to "discovery," not indexation. Technically, if an orphaned page is listed in an XML sitemap, Google can discover and index it — but it starts with a massive handicap in terms of crawl budget and internal PageRank.
Additionally, some internal search engines generate static result URLs that are then crawlable. For example, a results page like /search?q=running-shoes could theoretically be discovered if it's linked from another page. But Google will never submit that query itself — you need a user or internal system to have created that link.
[To verify]: The wording "generally" leaves a gray area. In rare cases — particularly with sites using well-configured URL parameters in Search Console — Google might explore certain combinations. But in practice, betting on this is risky.
What is the most common architectural mistake related to this issue?
The classic mistake? Creating product pages or content without any navigable entry points, thinking that "people will find them through internal search." Except Google isn't "people." It has no intention of actively searching for your content — you must serve it to it on a platter.
Second mistake: neglecting contextual internal linking. Even if a page is technically accessible through a menu buried 5 clicks deep, without contextual links from high-traffic pages, its SEO potential remains limited. Discoverability isn't enough — you also need internal authority.
Practical impact and recommendations
What should you do concretely to ensure all your pages are discoverable?
First step: audit your orphaned pages. Cross-reference your XML sitemap with URLs actually discovered by Googlebot (via Search Console or a crawler like Screaming Frog in "follow links only" mode). Any discrepancy reveals a structural problem.
Next, rethink your navigation architecture. Every strategic page must be accessible in a maximum of 3-4 clicks from the homepage, via standard HTML links. Faceted filters must generate crawlable URLs and be logically linked together.
How do you manage overly deep catalogs or niche content?
For e-commerce sites with tens of thousands of SKUs, the solution involves segmented listing pages and automated internal linking. Create pages like "All products from brand X," "New arrivals," "Best sellers," that serve as discovery hubs.
For blogs or content sites, implement automated contextual links based on semantics or tags. A page published 3 years ago can become visible again if it receives links from new high-performing articles.
Dynamic sitemaps remain useful, but only as a safety net. Never rely exclusively on them for indexation — they should complement solid architecture, not replace it.
What mistakes should you absolutely avoid?
Never create content accessible only through internal search. If a page deserves to exist, it deserves to be linked from at least one other thematically coherent page.
Avoid filters or facets generated only in JavaScript without associated crawlable URLs. Google has made progress on JS rendering, but why take the risk when static URLs work perfectly?
- Audit orphaned pages via cross-referencing your XML sitemap with actual crawl data
- Ensure every strategic page is accessible in 3-4 clicks maximum from the homepage
- Implement automated contextual internal linking for deep content
- Generate crawlable URLs for all important filters and facets
- Create thematic listing pages (brands, new arrivals, bestsellers) to serve as discovery hubs
- Regularly check Search Console to confirm priority URLs are being discovered and indexed
- Never rely solely on XML sitemaps for indexation — they complement rather than replace solid navigation
❓ Frequently Asked Questions
Si une page est dans mon sitemap XML mais n'a aucun lien interne, sera-t-elle indexée ?
Les URLs de résultats de recherche interne (type /search?q=terme) peuvent-elles être indexées ?
Comment identifier les pages orphelines sur mon site ?
Les filtres à facettes JavaScript posent-ils problème même si Google peut les rendre ?
Faut-il absolument lier toutes les pages d'un gros catalogue e-commerce ?
🎥 From the same video 12
Other SEO insights extracted from this same Google Search Central video · published on 29/08/2022
🎥 Watch the full video on YouTube →
💬 Comments (0)
Be the first to comment.