Official statement
Other statements from this video 8 ▾
- □ Pourquoi Google refuse-t-il de viser 100% de fiabilité pour son moteur de recherche ?
- □ Google vérifie-t-il réellement l'expérience utilisateur au-delà des codes HTTP ?
- □ Pourquoi Google veut-il détecter les incidents avant que vous ne les signaliez ?
- □ Comment Google gère-t-il les pics de trafic sans pénaliser le référencement ?
- □ Pourquoi Google traite-t-il certaines requêtes à moindre coût que d'autres ?
- □ Comment Google provisionne-t-il ses ressources serveur pour les pics de trafic prévisibles ?
- □ Google peut-il réellement voler des ressources à l'indexation pour stabiliser son moteur de recherche ?
- □ Comment Google gère-t-il les incidents de ranking avec des mitigations rapides ?
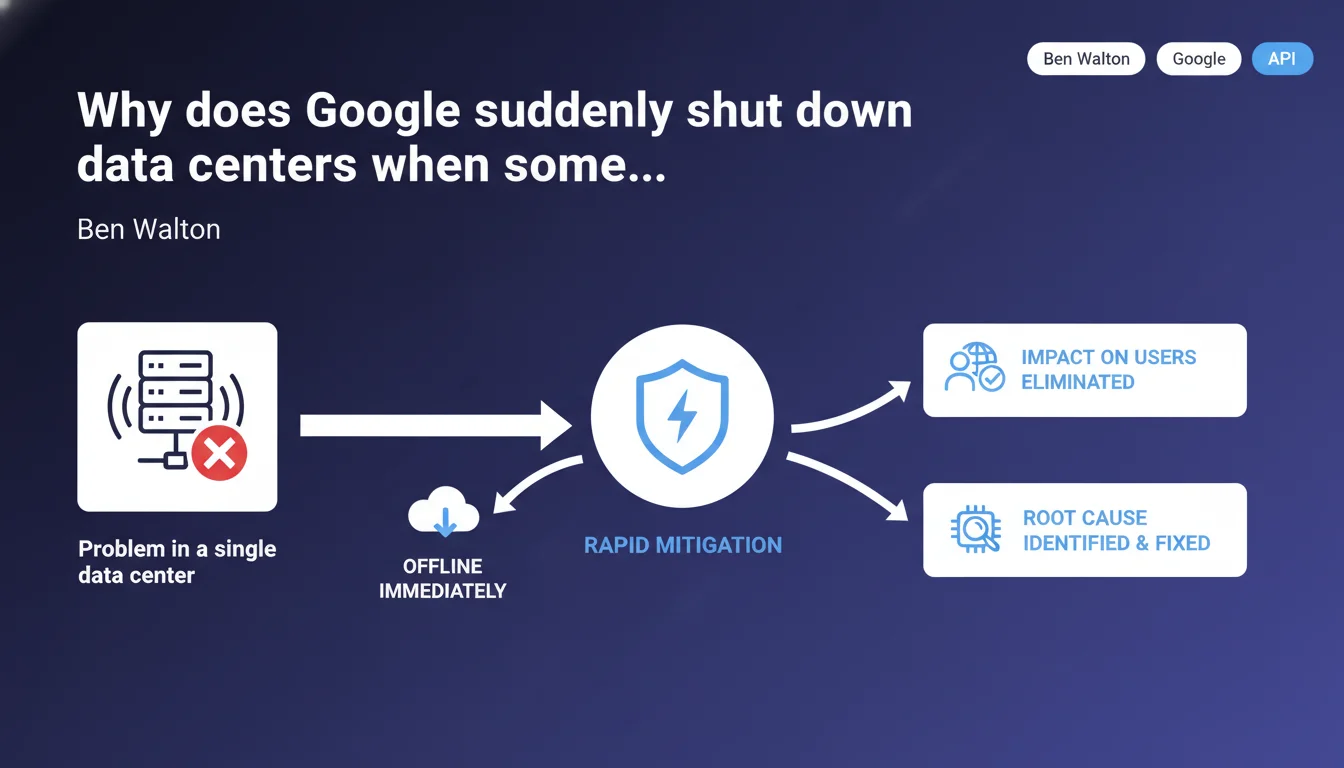
Google prioritizes the immediate shutdown of a failing data center rather than risking a degradation of user experience. This rapid mitigation strategy prevents unstable servers from continuing to serve search results or index content. For SEO practitioners, this means that a technical incident can lead to temporary fluctuations in crawl, indexation, or ranking—without necessarily reflecting a problem on your site.
What you need to understand
What's the logic behind this radical decision?
Google manages a distributed infrastructure across several dozen data centers spread globally. When a single center experiences an anomaly—abnormal latency, data corruption, network issues—the standard response is to isolate it instantly from production traffic.
This "fail-fast" approach is based on a simple principle: it's better to temporarily lose a fraction of capacity than to let a failing component pollute search results or slow down the entire system. Other data centers automatically absorb the missing load through load balancing and replication mechanisms.
Concretely, what happens to indexing during this period?
During the offline period, the affected data center stops crawling, indexing, and serving search results. Googlebots attached to this center no longer visit sites. User queries are redirected to other infrastructure.
The incident duration varies: a few minutes for an isolated network problem, several hours if an in-depth investigation is needed. Once the cause is identified and fixed, the data center is gradually reintegrated into the global cluster.
What are the observable consequences for webmasters?
- Temporary crawl drop: some sites may see their crawled page count drop sharply if the isolated data center was their primary bot source.
- Ranking fluctuations: during the switchover, minor variations can appear while other centers recalculate indexes and scores.
- Latencies or timeouts: if your origin server is geographically close to the offline data center, you might observe lengthened response times while traffic is rerouted.
- No lasting impact: once the incident is resolved, activity resumes normally without penalty or technical debt for crawled sites.
SEO Expert opinion
Is this statement consistent with observed practices?
Yes, completely. In the field, we regularly observe unexplained micro-fluctuations in logs: sudden crawl drops for 2-3 hours, then return to normal without any site-side changes. These anomalies often coincide with infrastructure incidents that Google doesn't communicate publicly.
The "immediate shutdown" strategy is actually a standard SRE best practice (Site Reliability Engineering): isolate the weak link to protect the overall system. Nothing surprising here—it's Chaos Engineering applied at Google scale.
What nuances should be added?
Google doesn't specify how many data centers simultaneously crawl the same site. A niche site might depend on a single center for its daily crawl, while a large international site will be crawled from multiple geographic zones in parallel.
Result: the impact of an offline event varies enormously depending on your site profile and geographic distribution. [To verify]: Google has never communicated precise metrics on crawl distribution by data center or on average incident duration. We're therefore partly flying blind.
Another point—this statement concerns "users," but it also applies to crawling and indexing. An offline data center serves neither human queries nor bot operations. It's consistent, but it deserves to be made explicit: an infrastructure incident can slow down the detection of new pages or delay the adoption of recent modifications.
In what cases doesn't this rule apply?
If the incident affects multiple data centers simultaneously, Google can't take them all offline—otherwise the entire service collapses. In that case, mitigation becomes more complex: emergency patches, partial rerouting, controlled degradation.
Let's be honest: these large-scale incidents are rare, but they happen. Generally, Google communicates then via its Search Status Dashboard or via @searchliaison on X. If you observe prolonged abnormal behavior (> 24h) without official announcement, it's probably a site-side issue, not a Google-side issue.
Practical impact and recommendations
What should you do concretely when facing this type of incident?
First, don't panic. A sudden drop in crawl or impressions for a few hours isn't necessarily a problem on your end. Before changing everything and redoing your sitemaps, check official sources: Search Status Dashboard, @searchliaison, community forums.
Next, document the incident in your logs: note the date, time, duration, and impacted pages. If the pattern repeats regularly at the same times or days, it might be a clue that your site is crawled mainly from a specific data center—useful information to anticipate future incidents.
What mistakes should you absolutely avoid?
- Don't modify your robots.txt file or server configuration during a period of instability—you risk making the situation worse.
- Don't artificially increase your crawl budget (via massive sitemaps or repeated pings) to "compensate" for a temporary drop—it won't help and will unnecessarily overload your servers.
- Don't interpret a ranking fluctuation lasting a few hours as a penalty or algorithmic issue—wait at least 48 hours before drawing conclusions.
- Don't neglect proactive monitoring: if you don't have real-time monitoring of your crawl and SERP performance, you're flying blind.
How can you verify that your infrastructure is resilient?
Ensure that your hosting also has geographic redundancy. If Google switches crawl from a European data center to an American one, your server must be able to absorb this additional latency without timeouts.
Regularly test your response capacity under load: Google crawling can represent hundreds of simultaneous requests. If your server struggles with any traffic variation, an infrastructure rerouting on Google's side could trigger 5xx errors—and Google penalizes that.
In summary: monitor your metrics in real time, stay informed of official incidents, and don't over-react to temporary anomalies. These infrastructure and monitoring optimizations can quickly become complex to orchestrate alone, especially if you manage multiple sites or heterogeneous technical environments. Calling on a specialized SEO agency for a thorough technical audit and tailored support can save you precious time—and prevent costly mistakes during critical periods.
❓ Frequently Asked Questions
Combien de temps dure en moyenne une mise hors ligne de data center Google ?
Est-ce que Google prévient les webmasters avant de couper un data center ?
Mon site peut-il être pénalisé si un data center Google tombe pendant que je pousse une mise à jour importante ?
Comment savoir quel data center Google crawle principalement mon site ?
Dois-je configurer mon CDN ou mon firewall différemment pour anticiper ces bascules ?
🎥 From the same video 8
Other SEO insights extracted from this same Google Search Central video · published on 03/10/2024
🎥 Watch the full video on YouTube →
💬 Comments (0)
Be the first to comment.