Official statement
Other statements from this video 8 ▾
- □ Pourquoi Google refuse-t-il de viser 100% de fiabilité pour son moteur de recherche ?
- □ Google vérifie-t-il réellement l'expérience utilisateur au-delà des codes HTTP ?
- □ Pourquoi Google veut-il détecter les incidents avant que vous ne les signaliez ?
- □ Comment Google gère-t-il les pics de trafic sans pénaliser le référencement ?
- □ Comment Google provisionne-t-il ses ressources serveur pour les pics de trafic prévisibles ?
- □ Google peut-il réellement voler des ressources à l'indexation pour stabiliser son moteur de recherche ?
- □ Comment Google gère-t-il les incidents de ranking avec des mitigations rapides ?
- □ Pourquoi Google coupe-t-il brutalement certains data centers en cas d'incident ?
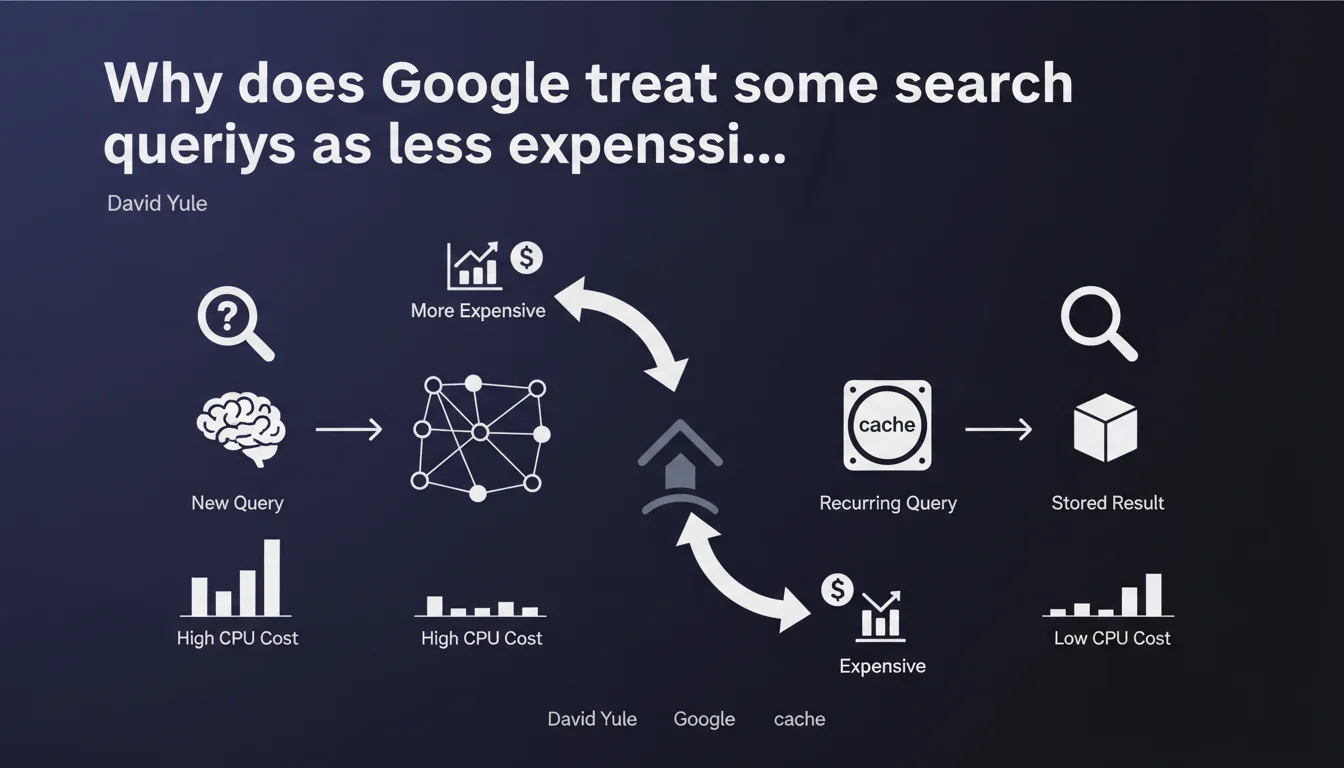
Google confirms that all Search queries do not consume the same amount of CPU resources. Simple queries that have already been processed are served from cache at marginal cost, while others heavily strain the infrastructure. This cost difference directly influences capacity planning during major events — and likely affects crawl budget allocation mechanisms.
What you need to understand
What determines the cost of a Search query?
Not all queries submitted to Google mobilize the same resources. A query that has already been processed recently — for example "Paris weather" typed thousands of times per hour — can be served directly from cache servers with virtually no CPU cost.
Conversely, a rare, highly specific, or first-time query requires full processing: semantic analysis, index calls, document scoring, personalization. The cost can be several orders of magnitude higher.
How does Google manage this resource asymmetry?
Google sizes its infrastructure based on predictable peaks — elections, major sporting events, natural disasters. During these peaks, the volume of queries explodes, but more importantly their diversity increases drastically.
Users ask unprecedented questions, search for fresh information not yet indexed massively. The cache becomes less effective, CPU load spikes. This explains why Google discusses specific capacity planning for these events.
What's the connection to SEO and crawl budget?
This statement indirectly sheds light on crawl budget logic. If Google optimizes its resources on the query side, it likely applies similar logic to crawling: prioritizing pages with high potential to answer frequent queries.
Pages that answer popular queries already in cache are mechanically more profitable for Google. Conversely, ultra-niche content without associated search volume is expensive to crawl, index, and serve — for marginal user benefit.
- Simple, frequent queries are served from cache with minimal CPU cost
- Complex or rare queries consume far more computing resources
- Google plans its capacity based on major event spikes
- This cost asymmetry likely influences crawl budget allocation
- Pages answering popular queries are mechanically more "profitable" for Google
SEO Expert opinion
Does this statement challenge the long-tail approach?
Not directly, but it seriously nuances the ambient discourse. We've been told for years that Google "understands everything," that the long tail is a goldmine. Let's be honest: if one query costs 100 times more to process than another, Google has economic incentive to favor content answering frequent queries.
This doesn't mean niche content is ignored — but it enters competition on terrain where the cost/benefit ratio works against it. If your site targets exclusively ultra-specific queries without volume, you're betting on a strategy Google has less incentive to support.
Can we concretely measure this impact on our sites?
[To verify] — Google provides no metric allowing us to distinguish which pages answer "expensive" vs "inexpensive" queries. We can deduce that pages generating traffic from high-volume queries are probably served from cache, thus less costly.
But beyond this obvious point, it's difficult to draw precise operational conclusions. Search Console doesn't segment impressions by "query CPU cost." We're flying blind.
Does this logic explain positioning variations during events?
Probably, yes. During a major event, Google must arbitrate between maintaining overall result quality and managing explosive CPU load. It's plausible that certain ranking mechanisms are temporarily simplified to handle the spike.
We regularly observe position fluctuations during events — not necessarily because the algorithm changes, but because Google activates degraded modes to absorb the peak. Sites most "expensive" to score may be temporarily disadvantaged. [To verify] — no official confirmation here, but it's consistent with this statement.
Practical impact and recommendations
Should we prioritize content answering high-volume queries?
Yes, but without abandoning the long tail entirely. The idea is to build a funnel architecture: pillar pages targeting popular queries (thus "profitable" for Google), then more niche satellite content that orbits around them.
Pillar pages benefit from caching, prioritized crawl, better SERP stability. They serve as entry points and then distribute juice to more specific content. Don't bet everything on queries with 10 searches per month.
How do we optimize our site to reduce "cost" on Google's side?
Concretely, favor signals indicating to Google that your pages answer recurring queries. Work on content freshness for popular topics — a regularly updated page has better chances of staying cached.
Avoid convoluted architectures with thousands of ultra-specific orphaned pages. Google might judge them too expensive to index and serve. Prioritize semantic density: fewer pages, better structured, covering clusters of related queries.
What mistakes should we avoid?
Don't fall into the "assembly-line content" trap on queries without real volume. You produce pages Google judges expensive without user benefit. Result: sporadic crawling, partial indexation, unstable rankings.
Another mistake: neglecting Core Web Vitals. If Google optimizes its resources server-side, it probably expects you to do the same client-side. A heavy page that tanks rendering on the user side amplifies the overall transaction cost.
- Build a funnel architecture with pillar pages on high-volume topics
- Maintain freshness of popular content to encourage caching
- Avoid proliferation of ultra-niche orphaned pages
- Work on semantic density: cover clusters of related queries
- Optimize Core Web Vitals to reduce client-side cost
- Monitor position variations during major events
- Prioritize crawl budget on pages answering frequent queries
❓ Frequently Asked Questions
Google favorise-t-il les pages répondant à des requêtes populaires ?
Les requêtes long tail sont-elles pénalisées par cette logique ?
Comment savoir si mes pages répondent à des requêtes coûteuses ?
Cette logique s'applique-t-elle aussi au crawl budget ?
Les fluctuations lors d'événements majeurs sont-elles liées à cette gestion des ressources ?
🎥 From the same video 8
Other SEO insights extracted from this same Google Search Central video · published on 03/10/2024
🎥 Watch the full video on YouTube →
💬 Comments (0)
Be the first to comment.