Official statement
Other statements from this video 11 ▾
- □ Can you really rely on service workers for SEO success?
- □ Can Googlebot actually index a website that relies on service workers to display its content?
- □ Does Googlebot really ignore the service workers on your site?
- □ How can you use Search Console to uncover hidden indexation problems caused by service workers?
- □ What are Google's live testing tools really showing you about your site's rendering issues?
- □ Can the JavaScript console really uncover critical rendering issues that hurt your SEO?
- □ Should you really inject console.log statements to diagnose Googlebot rendering failures?
- □ How can service workers accidentally hide your entire content from Googlebot?
- □ Should you really verify rendered HTML in Search Console to diagnose your indexation issues?
- □ Your page is indexed but invisible: is it a technical issue or simply outranked by competitors?
- □ Is your service worker secretly sabotaging your Google rankings?
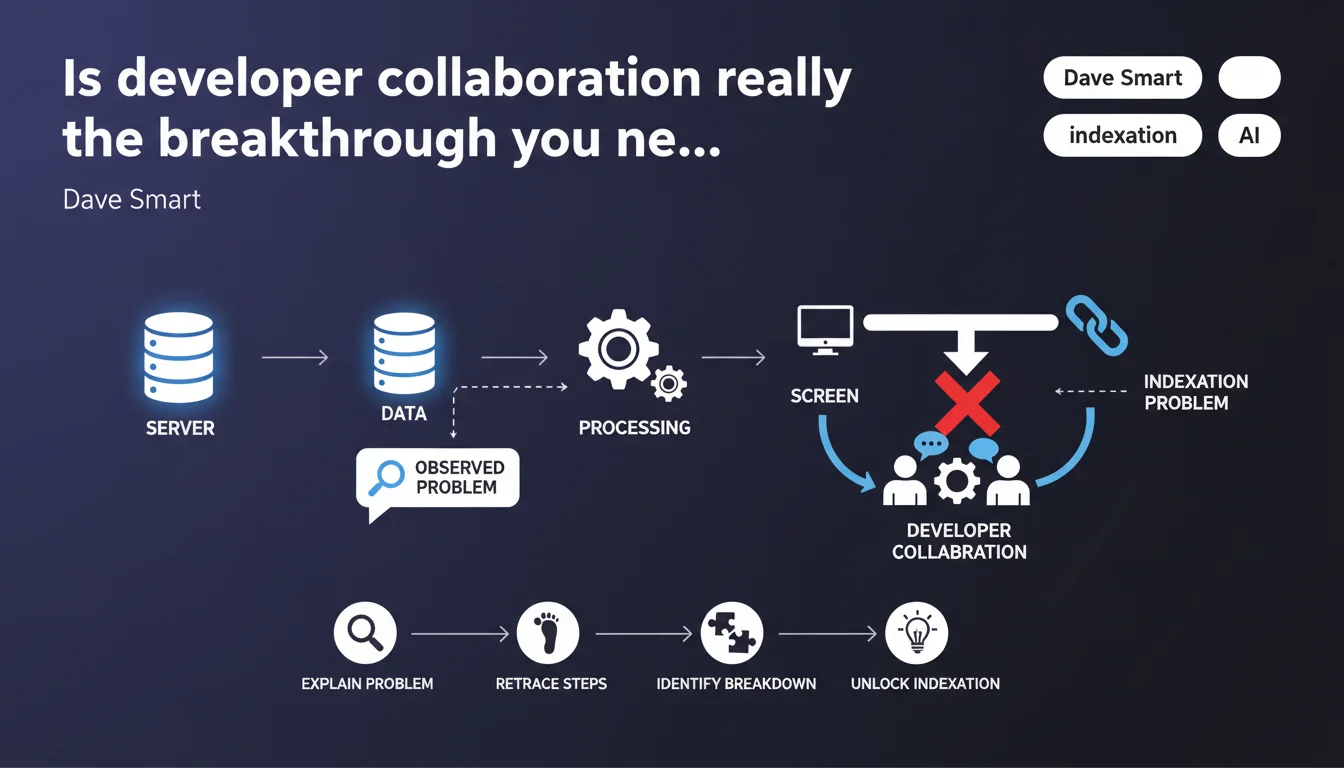
When facing an indexation issue, Google recommends quickly collaborating with developers by tracing the complete data journey from server to screen display. This methodical approach enables precise identification of where the process fails. The statement emphasizes that effective resolution relies on clear communication between SEO and technical teams.
What you need to understand
Why does Google insist on this collaborative approach?
Indexation problems cannot be resolved from Search Console or an SEO tool alone. They often require diving deep into the technical configuration of your site: server configuration files, middlewares, JavaScript frameworks, HTTP header management.
An SEO alone cannot diagnose a faulty pre-rendering issue, a misconfigured .htaccess rule, or a CDN blocking Googlebot. This is why close collaboration with those who understand the infrastructure is essential.
What does "retracing step-by-step" actually mean in practice?
Google is talking about an audit of the complete data journey. From the initial HTTP request all the way to the final DOM analyzed by the search engine. This involves checking: raw server response, any redirects, initial HTML rendering, JavaScript execution, and ultimately indexable content.
This systematic methodology allows you to identify whether the bottleneck occurs server-side (robots.txt, X-Robots-Tag header), rendering-side (JavaScript failing for Googlebot), or content-side (noindex tag injected dynamically).
What are the essential takeaways from this recommendation?
- Speed of action: indexation problems immediately impact visibility, so responsiveness is crucial
- Structured communication: explain the observed problem with tangible evidence (Search Console screenshots, live URL tests)
- Debugging methodology: tracing the data flow allows you to isolate the problem source rather than multiplying hypotheses
- Complementary skills: the SEO brings indexation/crawl vision, the developer brings infrastructure knowledge
SEO Expert opinion
Is this statement really applicable in the real world?
In theory, absolutely. In practice? That's another story. How many SEOs struggle to secure even a single slot with developers for a problem deemed "non-priority" by the product owner? Google describes an ideal collaboration scenario that assumes available development resources and a mature technical culture.
Many organizations still operate in hermetically sealed silos. The SEO escalates the problem, the ticket lands in an overloaded backlog, and three sprints later nothing has changed. The reality on the ground is that this fluid collaboration depends as much on organizational structure as it does on good intentions.
What nuances should we add to this approach?
Google presents debugging as a linear process "from server to screen." Except modern architectures aren't linear: CDNs, edge computing, hybrid SSR/CSR rendering, microservices... The journey can be labyrinthine.
Another point: the statement implies the problem necessarily stems from technical implementation. But sometimes, it's Google that fails. A transient crawl bug, a datacenter glitching, an algorithm hallucinating. [To verify]: how many "indexation problem" tickets resolve themselves after a few days without intervention?
In what cases does this method reach its limits?
When the problem comes from external factors: undocumented algorithmic penalty, change in Google's indexation policy, crawler-side bug. Tracing the data flow will be useless if Googlebot arbitrarily decides to stop indexing certain content categories.
Practical impact and recommendations
What should you concretely do to apply this method?
First step: document the problem factually. Not "the site isn't indexing well," but "347 URLs with unintentional noindex since the March 12th deployment, here's the list." Search Console screenshots, URL inspection tests, before/after comparison.
Second step: prepare the technical groundwork. Install the necessary tools to trace the journey: access to server logs (Cloudflare, nginx, Apache), rendering tool like Screaming Frog or Sitebulb, network analysis via Chrome DevTools, ideally a staging environment to reproduce.
What mistakes should you avoid in this collaboration?
Don't show up empty-handed with vague talk about "it's not indexing." Developers need reproducibility: which exact URLs, what observed behavior, what difference between what should happen and what actually happens.
Another trap: assuming it's necessarily a dev bug. Sometimes the problem stems from a misunderstood SEO directive that was implemented exactly as requested. "Block filter pages" might translate to an overpowered robots.txt that also blocks categories.
How can you structure this collaboration effectively?
- Create a shared document with problem timeline, affected URLs, estimated business impact
- Organize a joint debugging session (30-60 min) rather than endless email exchanges
- Use shared tracing tools: Loggly, Datadog, or simply a raw logs export
- Define a testing protocol: which URL to test, expected behavior, how to validate the fix
- Document the resolution to prevent recreating the same issue at the next deployment
❓ Frequently Asked Questions
Que faire si les développeurs n'ont pas le temps de traiter les problèmes d'indexation ?
Comment convaincre un développeur que le problème vient du code et pas de Google ?
Quels outils utiliser pour tracer le parcours serveur-écran ?
Est-ce que cette méthode fonctionne pour les problèmes de désindexation massive ?
Combien de temps faut-il généralement pour résoudre un problème d'indexation complexe ?
🎥 From the same video 11
Other SEO insights extracted from this same Google Search Central video · published on 01/11/2022
🎥 Watch the full video on YouTube →
💬 Comments (0)
Be the first to comment.