Official statement
Other statements from this video 7 ▾
- □ Quels encodages HTTP Googlebot accepte-t-il réellement pour crawler vos pages ?
- □ Pourquoi Google convertit-il enfin ses vieux articles de blog en documentation officielle ?
- □ JavaScript convient-il vraiment aux sites hybrides selon Google ?
- □ Comment les white papers de Google sur l'IA peuvent-ils améliorer votre stratégie SEO ?
- □ Le contenu dupliqué est-il vraiment un problème SEO ou un problème juridique ?
- □ Pourquoi Google organise-t-il des événements SEO dans des régions « sous-desservies » ?
- □ Pourquoi Google pointe-t-il des problèmes massifs de création de contenu sur les sites turcs ?
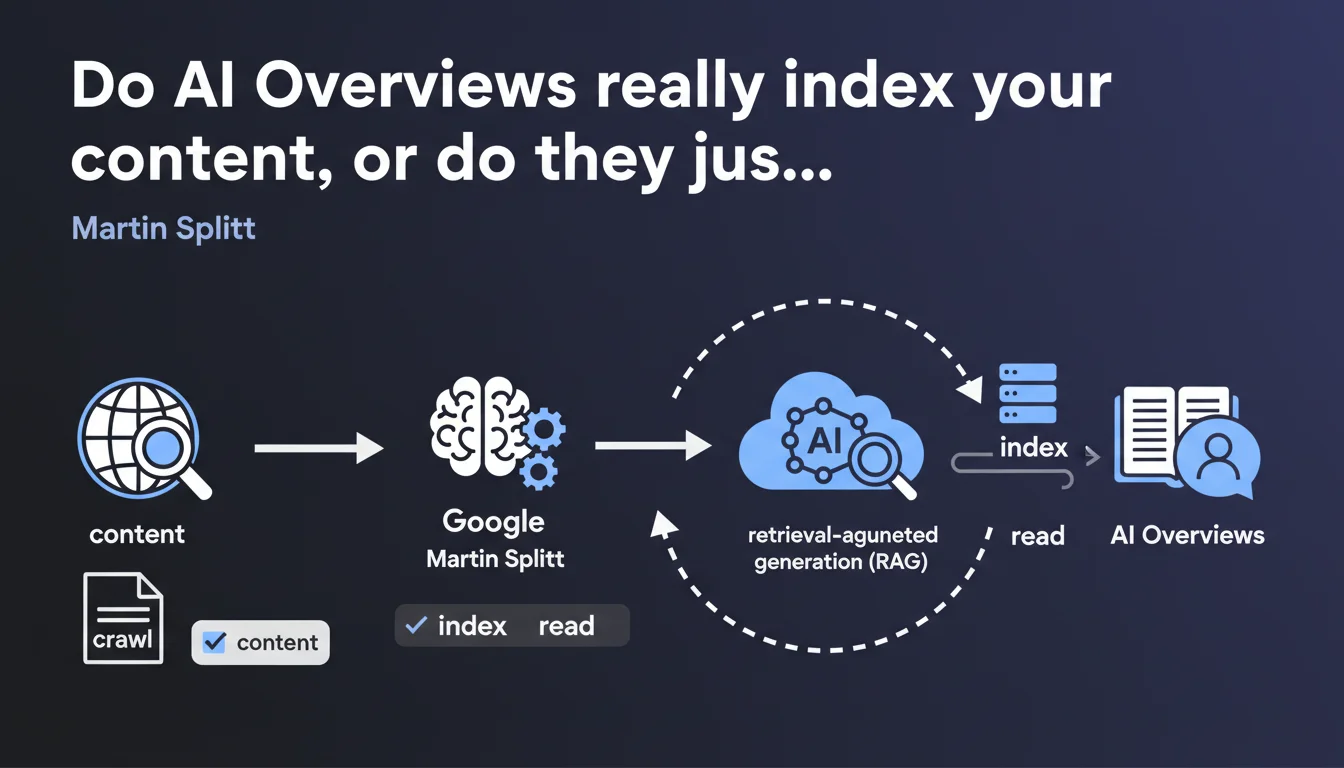
Google confirms that AI Overviews rely on crawlable and indexable content via RAG (Retrieval-Augmented Generation) technology, not on an isolated language model. Your content must be technically accessible to search engine crawlers to have any chance of appearing in these AI summaries. No indexation = no visibility in AI Overviews.
What you need to understand
What exactly is retrieval-augmented generation (RAG)?
RAG combines a language model with an external database. Instead of generating answers purely from its internal memory, the system first queries an index of crawled content to retrieve relevant information.
This information then serves as raw material for the generative model. That's the difference between a chatbot that makes up answers and a system that relies on documented sources.
Why is Google clarifying this now?
Many people imagined that AI Overviews worked like ChatGPT — a trained model that generates without verification. This statement sets the record straight: Google remains a search engine, even when producing AI summaries.
The goal? Reassure publishers. If your content is indexable, it can feed into AI Overviews. No indexation = no opportunity.
What does "crawlable and indexable" mean in this context?
Your content must be technically accessible to Google's crawlers: no robots.txt blocking, no noindex tags, pages served with 200 status codes, JavaScript rendered correctly if needed.
But crawlable isn't enough. Google also needs to decide to index the page — which depends on its perceived quality, relevance, and structure. A crawled page isn't necessarily indexed.
- RAG retrieves data from Google's index, not directly from your servers
- Your content must go through all the classic steps: crawl, rendering, indexation
- The same SEO rules apply — there's no miracle shortcut
- If a page is noindex, it can't feed into AI Overviews
SEO Expert opinion
Is this statement consistent with what we observe in the field?
Yes and no. Tests show that AI Overviews overwhelmingly favor large, authoritative sites that are already well-indexed. Nothing new under the sun. But Martin Splitt doesn't tell the whole story: RAG doesn't randomly pick from the index.
There's definitely a filtering and scoring layer that prioritizes certain content over others. Google doesn't specify these criteria — and that's where it gets murky. [To verify]: do freshness, E-E-A-T, or link volume play a decisive role in RAG selection?
What nuances should we add to this statement?
"Crawlable and indexable" guarantees nothing. Your content can very well be indexed and never appear in an AI Overview. The statement is reassuring on the surface, but it sidesteps the essential question: what are the post-indexation selection criteria?
Another point: RAG can very well paraphrase your content without explicitly citing you. You feed the system, but you don't necessarily get traffic back. That's the great unspoken truth of this announcement.
In what cases doesn't this rule fully apply?
If Google crawled and indexed your content months ago, but you updated it recently, RAG might still use the old version until the page gets recrawled. Index freshness matters.
Another limitation: very long or poorly structured content. Even if indexed, it can be partially ignored if the system can't extract clear blocks from it. RAG isn't magic — it needs clear signals.
Practical impact and recommendations
What should you do concretely to optimize your content?
Start by making sure your strategic pages are actually indexed. Use Search Console, check for accidental noindex tags, verify 200 status codes. If a page isn't in the index, it doesn't exist for AI Overviews.
Next, structure your content to facilitate extraction. Use semantic tags: <h2>, <h3>, lists, tables. RAG needs to quickly identify relevant blocks of information. A large block of unstructured text = a handicap.
What mistakes should you avoid at all costs?
Don't bank everything on mass indexation. Better to have 10 ultra-high-quality pages than a hundred average ones. RAG favors information density and clarity — not raw volume.
Another trap: thinking that AI will "understand" your content even if it's poorly structured. No. If your headings are vague, your paragraphs confusing, your data scattered, the system will look elsewhere. Machine readability remains a prerequisite.
How can you verify that your site is well-positioned for AI Overviews?
- Verify the indexation of your priority pages in Search Console
- Check loading times and JavaScript rendering if applicable
- Structure your content with hierarchical headings and clear lists
- Add structured data (FAQ, HowTo, Article) to facilitate extraction
- Test the readability of your content: a human should be able to scan it quickly
- Monitor the queries that trigger AI Overviews in your industry
❓ Frequently Asked Questions
Est-ce que tous les contenus indexés peuvent apparaître dans les AI Overviews ?
Les AI Overviews citent-elles toujours leurs sources ?
Un contenu en JavaScript est-il éligible pour les AI Overviews ?
Faut-il optimiser différemment pour les AI Overviews que pour les résultats classiques ?
Les contenus longs ont-ils un avantage dans les AI Overviews ?
🎥 From the same video 7
Other SEO insights extracted from this same Google Search Central video · published on 30/12/2024
🎥 Watch the full video on YouTube →
💬 Comments (0)
Be the first to comment.