Declaration officielle
Autres déclarations de cette vidéo 7 ▾
- □ Pourquoi votre site peut-il être invisible pour Googlebot alors qu'il s'affiche parfaitement dans votre navigateur ?
- □ Pourquoi Google insiste-t-il sur la surveillance des erreurs serveur dans le rapport Statistiques d'exploration ?
- □ Faut-il vraiment s'inquiéter de chaque erreur de crawl remontée dans la Search Console ?
- □ Faut-il vraiment agir sur chaque erreur 500 détectée par Google dans le rapport de crawl ?
- □ Comment analyser vos logs serveur pour optimiser le crawl de Google ?
- □ Comment distinguer le vrai Googlebot des imposteurs dans vos logs serveur ?
- □ Pourquoi vos pages n'entrent-elles pas dans Google Search malgré tous vos efforts SEO ?
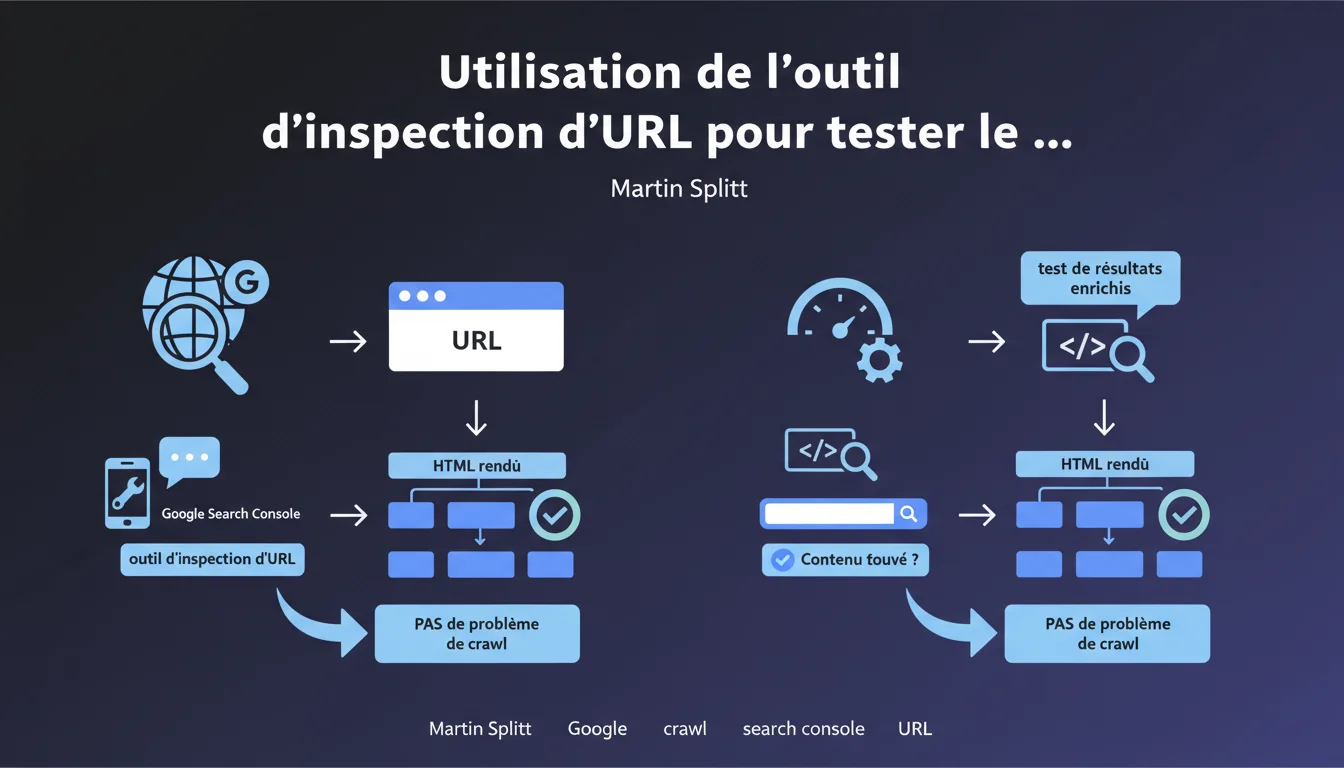
Martin Splitt rappelle que l'outil d'inspection d'URL dans Search Console et le test de résultats enrichis affichent le HTML rendu par Googlebot. Si votre contenu apparaît dans ce HTML rendu, le problème n'est pas lié au crawl — il faut chercher ailleurs.
Ce qu'il faut comprendre
Pourquoi cette distinction entre HTML brut et HTML rendu est-elle déterminante ?
Google ne se contente pas de lire le code source HTML statique de vos pages. Googlebot exécute le JavaScript pour générer un rendu final — c'est ce qu'on appelle le HTML rendu. Si votre contenu critique dépend de scripts côté client, il n'apparaîtra que dans cette version rendue.
L'outil d'inspection d'URL dans Search Console et le test de résultats enrichis vous montrent exactement ce que Googlebot voit après exécution du JavaScript. C'est votre source de vérité pour diagnostiquer les problèmes d'indexation liés au rendu.
Que faire si le contenu apparaît bien dans le HTML rendu ?
Si vous trouvez votre texte, vos balises meta ou vos données structurées dans l'HTML rendu affiché par l'outil, alors Googlebot a bien accès à ce contenu. Le crawl fonctionne correctement de ce point de vue.
Le problème se situe probablement ailleurs : qualité du contenu, cannibalisation, budget de crawl insuffisant, directives robots.txt ou meta qui bloquent l'indexation, ou encore absence de liens internes vers la page.
Quels sont les pièges à éviter lors de cette vérification ?
Première erreur classique : se fier uniquement au code source affiché dans le navigateur via "Afficher la source de la page". Ce n'est pas ce que Googlebot rend — il faut passer par les outils officiels.
Deuxième piège : confondre "crawlabilité" et "indexabilité". Ce n'est pas parce que Googlebot accède au contenu qu'il choisira de l'indexer. L'outil d'inspection d'URL ne règle qu'une partie du diagnostic.
- L'outil d'inspection d'URL montre le HTML final après exécution JavaScript — c'est votre référence pour valider le crawl
- Si le contenu est présent dans le rendu, le crawl n'est pas en cause : cherchez du côté de l'indexation ou de la qualité
- Ne vous fiez jamais au code source brut pour diagnostiquer un problème de rendu JavaScript
- Utilisez la fonction de recherche (Ctrl+F) dans l'outil pour vérifier rapidement la présence d'un élément critique
Avis d'un expert SEO
Cette déclaration est-elle cohérente avec les observations terrain ?
Oui, et c'est même un rappel salutaire. Trop de SEO continuent de paniquer quand ils ne voient pas leur contenu dans le code source HTML, alors qu'il apparaît bien après rendu. L'outil d'inspection est fiable — si le contenu y figure, il est accessible à Google.
Par contre — et Martin Splitt le sait parfaitement — ce n'est qu'une première étape. J'ai vu des dizaines de cas où le contenu était bien rendu mais pas indexé pour autant. Le crawl n'est pas synonyme d'indexation, et encore moins de ranking.
Quelles nuances faut-il apporter à cette consigne ?
Splitt simplifie volontairement. Il dit "si vous trouvez le contenu, ce n'est pas un problème de crawl". D'accord. Mais il reste silencieux sur les délais de rendu, qui peuvent poser problème pour des sites à fort volume.
Si votre JavaScript met 8 secondes à charger du contenu critique, Googlebot peut théoriquement attendre — mais en pratique, sur un site de 50 000 pages, ça bouffe du budget de crawl. Le rendu fonctionne, certes, mais de manière sous-optimale. [À vérifier] : Google n'a jamais publié de seuil officiel de timeout pour le rendu JS.
Dans quels cas cette règle ne suffit-elle pas ?
Imaginons que votre contenu apparaisse bien dans l'outil d'inspection, mais qu'il soit généré côté client à partir d'une API externe qui rate 20% de ses appels. L'outil teste un crawl ponctuel — il ne reflète pas la fiabilité sur la durée.
Autre scénario : votre site utilise du lazy-loading agressif ou des événements d'interaction (clic, scroll) pour charger du contenu. Googlebot peut ne pas déclencher ces événements, et l'outil d'inspection ne simulera pas toujours ces comportements complexes.
Impact pratique et recommandations
Que faut-il faire concrètement pour valider le crawl de vos pages ?
Première étape : ouvrez Search Console, sélectionnez l'outil d'inspection d'URL, collez l'URL de votre page stratégique. Cliquez sur "Tester l'URL en direct" pour obtenir un rendu à jour. Attendez le résultat — ça peut prendre 30 secondes à 2 minutes.
Une fois le rendu affiché, utilisez Ctrl+F (ou Cmd+F sur Mac) pour chercher un fragment de texte unique présent dans votre contenu critique : un titre H1, une phrase clé, une balise meta description. Si vous le trouvez, Googlebot y a accès. Si ce n'est pas le cas, vous avez un problème de rendu JavaScript ou de blocage de ressources.
Quelles erreurs éviter lors de cette vérification ?
Ne vous arrêtez pas à la version en cache affichée par défaut dans l'outil — elle peut être obsolète. Utilisez toujours le bouton "Tester l'URL en direct" pour un diagnostic fiable.
Évitez aussi de conclure trop vite. Si le contenu est absent du rendu, vérifiez d'abord que les ressources JavaScript ne sont pas bloquées par le robots.txt (allez dans l'onglet "Couverture" puis "Plus d'infos" pour voir les ressources chargées). Un script bloqué = pas de rendu.
Comment automatiser cette vérification sur un gros site ?
Pour un site de 500+ pages, tester manuellement chaque URL via l'outil d'inspection est impraticable. Deux solutions : utiliser l'API Indexing de Google (limitée aux types de contenu éligibles comme JobPosting) ou un crawler JavaScript comme Screaming Frog en mode rendu ou OnCrawl.
Configurez votre crawler pour comparer le HTML brut et le HTML rendu. Exportez ensuite la liste des URLs où un élément critique (balise title, H1, contenu principal) est absent du rendu. Priorisez ces pages pour investigation manuelle.
- Tester systématiquement les pages stratégiques via l'outil d'inspection d'URL en mode "Tester l'URL en direct"
- Utiliser Ctrl+F pour chercher un fragment de texte unique dans le HTML rendu
- Vérifier que les ressources JavaScript ne sont pas bloquées par robots.txt
- Ne jamais se fier uniquement au code source HTML brut affiché par le navigateur
- Automatiser la vérification rendu vs. brut sur gros sites avec un crawler JavaScript configuré
- Comparer régulièrement les données de l'outil d'inspection avec les logs serveur pour détecter les écarts
❓ Questions frequentes
L'outil d'inspection d'URL remplace-t-il un crawl complet du site ?
Si mon contenu apparaît dans le HTML rendu mais que la page n'est pas indexée, où est le problème ?
Le test de résultats enrichis affiche-t-il exactement le même rendu que l'outil d'inspection d'URL ?
Peut-on faire confiance aux crawlers tiers pour simuler le rendu JavaScript de Googlebot ?
Combien de temps Googlebot attend-il avant de considérer qu'une page JavaScript a fini de charger ?
🎥 De la même vidéo 7
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 13/12/2024
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.