Declaration officielle
Autres déclarations de cette vidéo 7 ▾
- □ Pourquoi votre site peut-il être invisible pour Googlebot alors qu'il s'affiche parfaitement dans votre navigateur ?
- □ Comment vérifier si Googlebot crawle vraiment votre contenu JavaScript ?
- □ Pourquoi Google insiste-t-il sur la surveillance des erreurs serveur dans le rapport Statistiques d'exploration ?
- □ Faut-il vraiment agir sur chaque erreur 500 détectée par Google dans le rapport de crawl ?
- □ Comment analyser vos logs serveur pour optimiser le crawl de Google ?
- □ Comment distinguer le vrai Googlebot des imposteurs dans vos logs serveur ?
- □ Pourquoi vos pages n'entrent-elles pas dans Google Search malgré tous vos efforts SEO ?
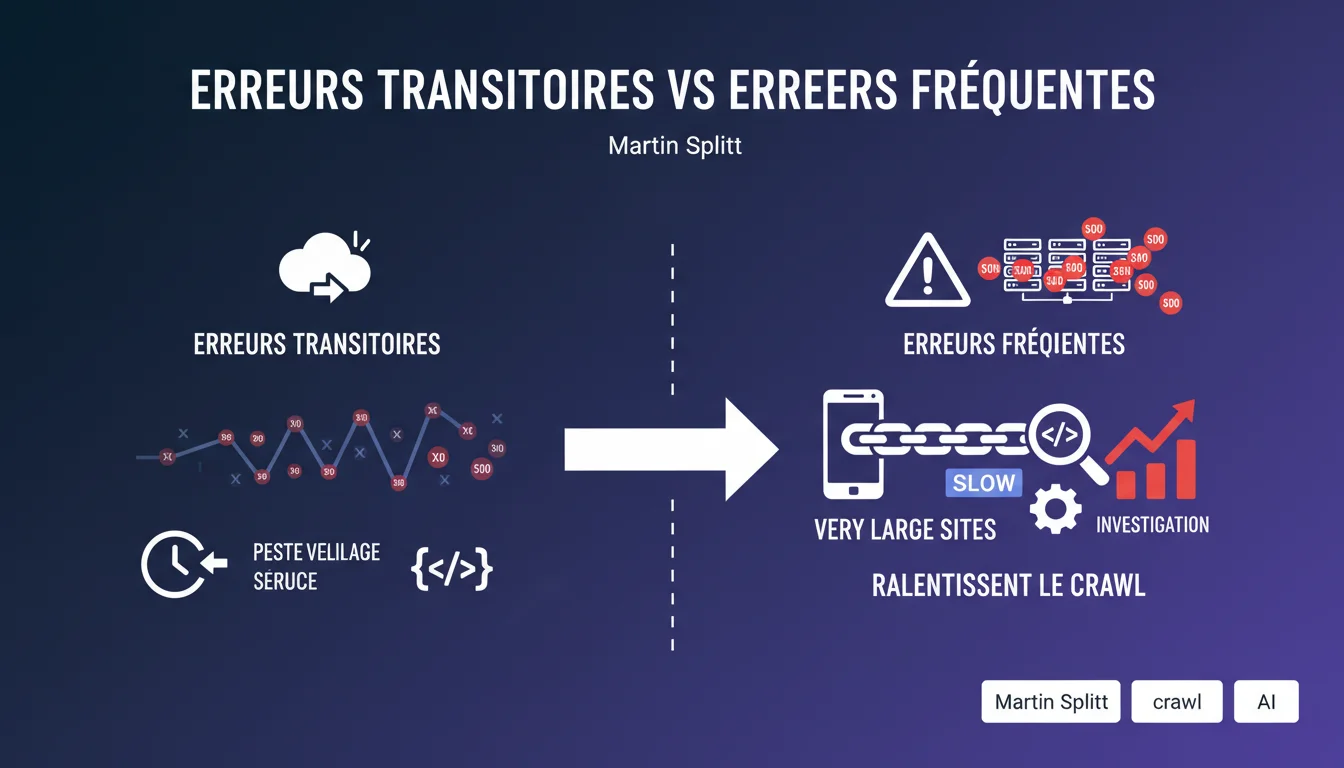
Google distingue les erreurs de crawl transitoires (qui se corrigent seules) des erreurs fréquentes ou en augmentation subite (qui nécessitent une investigation). Sur les très gros sites, les erreurs 500 récurrentes ralentissent le crawl et méritent une attention particulière.
Ce qu'il faut comprendre
Pourquoi Google fait-il cette distinction entre erreurs transitoires et erreurs fréquentes ?
Le crawl d'un site n'est jamais un processus parfait. Des erreurs ponctuelles peuvent survenir pour des raisons techniques variées : redémarrage de serveur, pic de charge momentané, timeout réseau. Ces erreurs transitoires disparaissent d'elles-mêmes sans intervention humaine.
Google sait que ces aléas existent et ne pénalise pas un site pour quelques erreurs isolées. Le bot réessaiera plus tard et récupérera le contenu. C'est la fréquence et la persistance des erreurs qui signalent un vrai problème structurel.
Qu'est-ce qui déclenche l'alerte selon Google ?
Deux signaux doivent attirer l'attention : une fréquence élevée d'erreurs (plusieurs occurrences sur les mêmes URLs ou segments du site) et une augmentation soudaine du taux d'erreurs (spike visible dans la Search Console).
Dans ces cas, il ne s'agit plus d'un incident technique ponctuel mais potentiellement d'un problème de configuration, d'infrastructure ou de code qui empêche Googlebot d'accéder au contenu de manière fiable.
Pourquoi les erreurs 500 sont-elles particulièrement problématiques sur les gros sites ?
Sur un site de plusieurs millions de pages, Google alloue un budget de crawl limité. Chaque erreur 500 consomme du budget sans récupérer de contenu exploitable.
Si Googlebot rencontre fréquemment des erreurs serveur, il réduit la cadence de crawl pour ne pas surcharger davantage une infrastructure visiblement fragile. Résultat : les nouvelles pages sont découvertes plus lentement, les mises à jour de contenu prennent du retard, et les sections du site peu crawlées le deviennent encore moins.
- Erreurs transitoires : ponctuelles, se corrigent seules, n'impactent pas le crawl global
- Erreurs fréquentes ou en hausse : signalent un problème structurel à investiguer
- Erreurs 500 sur gros sites : ralentissent le crawl et retardent l'indexation
- Budget de crawl : ressource limitée que les erreurs serveur gaspillent
Avis d'un expert SEO
Cette déclaration est-elle cohérente avec ce qu'on observe terrain ?
Oui, complètement. On constate régulièrement dans la Search Console des erreurs 404 ou 503 isolées qui disparaissent au crawl suivant. Googlebot ne sanctionne pas ces incidents ponctuels.
En revanche, dès qu'un pattern d'erreurs se dessine — même catégorie d'URLs, même type d'erreur, même plage horaire — c'est le signe d'un problème à traiter. Les sites e-commerce avec génération dynamique de pages produits ou les médias avec beaucoup de contenus temporaires sont particulièrement exposés.
Quelle nuance faut-il apporter sur le seuil de fréquence ?
Google ne donne aucun chiffre précis. [À vérifier] Combien d'erreurs 500 par jour déclenchent un ralentissement du crawl sur un site d'1 million de pages ? 10 ? 100 ? 1000 ?
Cette imprécision oblige à une surveillance manuelle. La Search Console signale des anomalies, mais elle ne fournit pas de seuil d'alerte ni de recommandation automatisée. C'est au SEO d'interpréter les courbes et de décider quand investiguer.
Dans quels cas cette règle ne s'applique-t-elle pas ?
Sur les petits sites (moins de 10 000 pages), le budget de crawl n'est pas un facteur limitant. Quelques erreurs 500 par semaine ne ralentiront pas significativement l'indexation.
Là où ça coince, c'est sur les plateformes massives : marketplaces, agrégateurs, portails d'annonces. Une erreur serveur sur 0,1 % des pages représente plusieurs milliers d'URLs inaccessibles — et ça, Googlebot le remarque.
Impact pratique et recommandations
Que faut-il surveiller concrètement dans la Search Console ?
Le rapport Couverture (ou Indexation selon la version de la GSC) affiche les erreurs de crawl par type et par URL. Concentre-toi sur deux métriques : la fréquence d'apparition d'une même erreur et l'évolution du volume d'erreurs dans le temps.
Un pic soudain d'erreurs 500 un jour donné peut indiquer un incident infrastructure (maintenance, déploiement raté, surcharge serveur). Si ce pic se répète ou persiste, c'est un signal d'alarme.
Comment réagir face à une hausse d'erreurs de crawl ?
Identifie d'abord le pattern : les URLs concernées appartiennent-elles à une même section du site ? Même template ? Même typologie de contenu ? Cela oriente le diagnostic.
Ensuite, croise avec les logs serveur. Les erreurs remontées dans la GSC correspondent-elles à des erreurs réelles serveur ? Parfois, un problème de configuration de robots.txt ou de redirection masque le vrai souci.
Quelles actions correctrices mettre en place ?
Pour les erreurs serveur récurrentes, l'optimisation de l'infrastructure est prioritaire : augmenter la capacité serveur, optimiser les requêtes base de données, mettre en place un système de cache performant.
Sur les gros sites, une politique de crawl sélectif peut aider : bloquer le crawl des sections peu stratégiques (filtres produits, URL de pagination profonde) pour concentrer le budget sur le contenu à forte valeur.
- Surveiller hebdomadairement le rapport Couverture/Indexation dans la Search Console
- Configurer des alertes automatiques sur les pics d'erreurs (via API GSC ou outils tiers)
- Analyser les logs serveur pour identifier les URLs problématiques avant que Google ne les détecte
- Auditer l'infrastructure serveur si les erreurs 500 dépassent 0,5 % du crawl quotidien
- Prioriser la correction des erreurs sur les URLs stratégiques (conversions, trafic élevé)
- Documenter les incidents pour détecter les récurrences (jour de la semaine, heure, déploiements)
❓ Questions frequentes
À partir de quel seuil d'erreurs 500 faut-il s'inquiéter ?
Les erreurs 404 ralentissent-elles aussi le crawl ?
Comment distinguer une erreur transitoire d'un problème structurel ?
Faut-il réduire le crawl de Googlebot si mon serveur est instable ?
Les erreurs 503 sont-elles traitées comme les 500 ?
🎥 De la même vidéo 7
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 13/12/2024
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.