Declaration officielle
Autres déclarations de cette vidéo 7 ▾
- □ Pourquoi votre site peut-il être invisible pour Googlebot alors qu'il s'affiche parfaitement dans votre navigateur ?
- □ Comment vérifier si Googlebot crawle vraiment votre contenu JavaScript ?
- □ Pourquoi Google insiste-t-il sur la surveillance des erreurs serveur dans le rapport Statistiques d'exploration ?
- □ Faut-il vraiment s'inquiéter de chaque erreur de crawl remontée dans la Search Console ?
- □ Faut-il vraiment agir sur chaque erreur 500 détectée par Google dans le rapport de crawl ?
- □ Comment analyser vos logs serveur pour optimiser le crawl de Google ?
- □ Comment distinguer le vrai Googlebot des imposteurs dans vos logs serveur ?
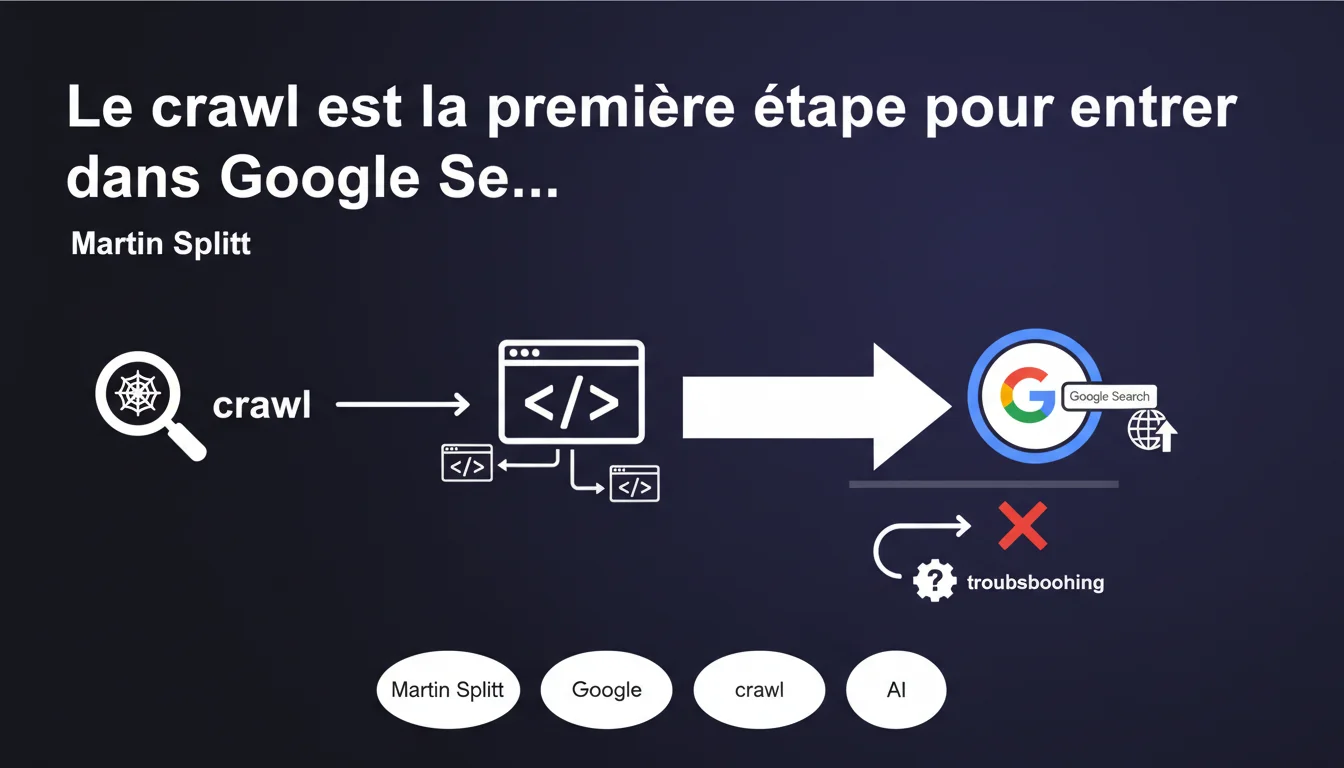
Google recentre le débat : si vos pages n'apparaissent pas dans les résultats de recherche, inutile de chercher midi à quatorze heures — le problème se situe au niveau du crawl. Martin Splitt rappelle que le crawling est la porte d'entrée obligatoire dans l'index, et que tout troubleshooting doit commencer par cette étape souvent négligée.
Ce qu'il faut comprendre
Le crawl est-il vraiment le seul point de départ pour diagnostiquer un problème d'indexation ?
Google ne laisse aucune ambiguïté : si une page n'apparaît pas dans Search, c'est d'abord un problème de crawl. Pas d'indexation, pas de ranking, pas de snippet enrichi — rien de tout cela n'a d'importance si Googlebot n'a pas accédé à votre contenu.
Ce rappel de Martin Splitt s'adresse autant aux débutants qu'aux praticiens expérimentés qui ont parfois tendance à sauter des étapes. On se précipite sur les balises canonical, les sitemaps XML ou les directives noindex, alors que le blocage se situe en amont.
Quels sont les signaux d'un problème de crawl plutôt que d'indexation ?
La distinction est cruciale. Un problème de crawl signifie que Googlebot n'a pas pu atteindre votre page — ou l'a atteinte partiellement. Un problème d'indexation, lui, survient après le crawl : la page a été explorée, mais Google a décidé de ne pas l'inclure dans son index.
Les symptômes typiques d'un souci de crawl incluent : pages bloquées par robots.txt, erreurs serveur 5xx récurrentes, timeouts, redirections en chaîne, ou encore ressources critiques (CSS, JS) inaccessibles. Search Console vous donnera des indices précis via les rapports de couverture et les logs de crawl.
Google propose-t-il une méthodologie claire pour investiguer ?
La documentation officielle insiste sur une approche séquentielle : crawl → indexation → ranking → affichage. Si l'étape 1 échoue, les suivantes deviennent caduques. Martin Splitt ne développe pas ici la méthodologie complète — il se contente de rappeler l'ordre des priorités.
Concrètement, cela signifie que vos efforts sur le contenu, les backlinks ou les Core Web Vitals sont stériles tant que le crawl n'est pas opérationnel. C'est un rappel à l'ordre pour ceux qui optimisent à l'envers.
- Le crawl est la condition sine qua non pour entrer dans Google Search — aucune autre optimisation ne peut contourner cette étape.
- Un diagnostic efficace commence par vérifier l'accessibilité des pages via Search Console et les logs serveur.
- Google privilégie une approche séquentielle : résoudre les blocages de crawl avant de s'attaquer aux problèmes d'indexation ou de ranking.
- Les ressources externes (CSS, JS, images) doivent également être crawlables pour que Google comprenne correctement le contenu.
Avis d'un expert SEO
Cette déclaration est-elle cohérente avec les observations terrain ?
Oui, et c'est même un constat quotidien. Les audits SEO révèlent régulièrement des sites où des centaines de pages stratégiques sont bloquées par des règles robots.txt mal configurées ou des erreurs serveur non détectées. Les équipes techniques modifient des infrastructures sans mesurer l'impact sur le crawl.
Mais — et c'est là que ça coince — Google ne dit rien sur les situations où le crawl est techniquement possible mais n'a tout simplement pas lieu. Crawl budget limité, pages orphelines, absence de maillage interne : autant de cas où Googlebot pourrait crawler mais ne le fait pas. [A vérifier] si Google considère ces situations comme des "problèmes de crawl" au sens strict.
Quelles nuances faut-il apporter à ce message ?
Martin Splitt simplifie — volontairement. Le crawl n'est pas un processus binaire (ça marche / ça marche pas). Il existe des situations grises : crawl partiel d'une page JavaScript, crawl de ressources critiques en échec, crawl différé de plusieurs semaines pour des sections peu prioritaires.
Par ailleurs, certains problèmes d'indexation surviennent après un crawl réussi : contenu dupliqué détecté, qualité jugée insuffisante, canonicalisation automatique. Dans ces cas, le troubleshooting ne commence pas par le crawl — il commence par comprendre pourquoi Google a choisi de ne pas indexer malgré un crawl effectif.
Dans quels cas cette règle ne s'applique-t-elle pas ?
Soyons honnêtes : il existe des exceptions où le crawl n'est pas le premier point d'entrée à investiguer. Si votre site est déjà massivement indexé mais que certaines pages spécifiques n'apparaissent pas, le problème peut être ailleurs : cannibalisation interne, contenu perçu comme thin, pénalité manuelle ciblée.
De même, pour des sites à très fort volume (e-commerce, médias), le crawl budget devient un enjeu stratégique. Google crawle, certes, mais pas tout — et pas assez souvent. Dans ce contexte, optimiser le crawl ne suffit pas : il faut aussi prioriser ce qui doit être crawlé via le maillage interne, les sitemaps XML, et la gestion des redirections.
Impact pratique et recommandations
Que faut-il faire concrètement pour s'assurer que vos pages sont crawlables ?
Premier réflexe : auditez votre fichier robots.txt. Vérifiez qu'aucune directive Disallow ne bloque des sections critiques de votre site. Les erreurs les plus fréquentes concernent les répertoires /blog, /product, ou encore des ressources JS/CSS essentielles au rendu.
Ensuite, analysez vos logs serveur. Comparez les URLs crawlées par Googlebot avec celles que vous souhaitez voir indexées. Si des pages stratégiques n'apparaissent jamais dans les logs, c'est qu'elles sont orphelines ou mal maillées — Googlebot ne les trouve tout simplement pas.
Enfin, utilisez l'outil Test de l'URL en direct dans Search Console. Cet outil simule un crawl et vous indique immédiatement si Googlebot peut accéder à la page, charger les ressources, et interpréter le contenu rendu. C'est le moyen le plus rapide de lever le doute.
Quelles erreurs éviter absolument lors du troubleshooting ?
Ne pas confondre "crawlé" et "indexé". Une page peut être crawlée sans être indexée — et inversement (Google peut garder une page en index même après un recrawl négatif). Search Console affiche ces statuts distinctement : apprenez à les lire correctement.
Évitez aussi de multiplier les requêtes d'indexation manuelle via Search Console si le problème est structurel. Si Googlebot ne peut pas crawler votre page, forcer une indexation ne servira à rien — réglez d'abord le blocage technique.
Dernière erreur fréquente : négliger le maillage interne. Même si vos pages sont techniquement crawlables, Googlebot doit pouvoir les découvrir. Une page sans lien entrant depuis une autre page du site est invisible — peu importe sa qualité.
- Vérifier que robots.txt n'interdit pas le crawl des sections stratégiques
- Analyser les logs serveur pour identifier les pages non visitées par Googlebot
- Tester chaque URL critique avec l'outil "Inspection de l'URL" dans Search Console
- S'assurer que les ressources JS/CSS essentielles au rendu sont crawlables
- Contrôler le maillage interne : chaque page importante doit être liée depuis au moins une autre page
- Surveiller les erreurs serveur (5xx) et les timeouts dans les rapports Search Console
- Optimiser le temps de réponse serveur pour faciliter le crawl (objectif < 200 ms TTFB)
- Éviter les chaînes de redirections (3xx) qui ralentissent ou interrompent le crawl
Le message de Google est simple : pas de crawl, pas de Search. Avant de vous lancer dans des optimisations avancées, assurez-vous que Googlebot peut accéder à vos pages, charger les ressources critiques, et naviguer via votre maillage interne.
Ces vérifications peuvent sembler basiques, mais elles sont la fondation de toute stratégie SEO. Si votre infrastructure technique présente des blocages complexes ou si vous manquez de ressources pour analyser finement vos logs et vos rapports Search Console, l'accompagnement d'une agence SEO spécialisée peut s'avérer déterminant pour identifier rapidement les points de friction et mettre en place des correctifs pérennes.
❓ Questions frequentes
Quelle est la différence entre un problème de crawl et un problème d'indexation ?
Comment vérifier si mes pages sont crawlées par Google ?
Le crawl budget est-il un problème pour tous les sites ?
Peut-on forcer Google à crawler une page plus rapidement ?
Les ressources externes (CSS, JS) doivent-elles être crawlables ?
🎥 De la même vidéo 7
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 13/12/2024
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.