Declaration officielle
Autres déclarations de cette vidéo 7 ▾
- □ Comment vérifier si Googlebot crawle vraiment votre contenu JavaScript ?
- □ Pourquoi Google insiste-t-il sur la surveillance des erreurs serveur dans le rapport Statistiques d'exploration ?
- □ Faut-il vraiment s'inquiéter de chaque erreur de crawl remontée dans la Search Console ?
- □ Faut-il vraiment agir sur chaque erreur 500 détectée par Google dans le rapport de crawl ?
- □ Comment analyser vos logs serveur pour optimiser le crawl de Google ?
- □ Comment distinguer le vrai Googlebot des imposteurs dans vos logs serveur ?
- □ Pourquoi vos pages n'entrent-elles pas dans Google Search malgré tous vos efforts SEO ?
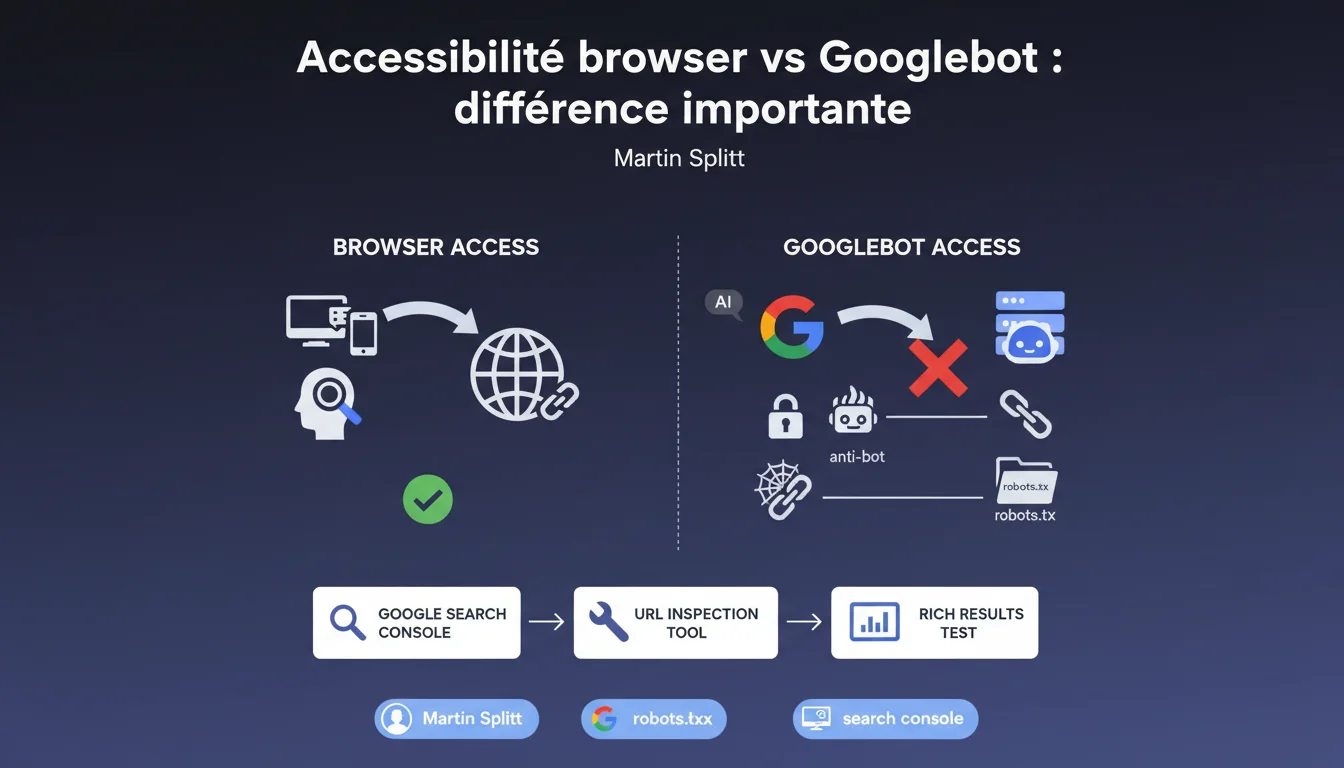
Ce qui fonctionne dans votre navigateur ne garantit pas que Googlebot puisse y accéder. Le robots.txt, les firewalls, les protections anti-bot ou des problèmes réseau bloquent fréquemment le crawler sans que vous le sachiez. L'outil d'inspection d'URL de Search Console reste votre seul moyen fiable de vérifier l'accès réel de Googlebot à vos pages.
Ce qu'il faut comprendre
Quel est le décalage entre l'expérience utilisateur et l'expérience Googlebot ?
Quand vous testez une page dans Chrome ou Firefox, vous passez par une connexion utilisateur classique. Votre navigateur envoie des en-têtes HTTP standards, accepte les cookies, exécute JavaScript sans restriction.
Googlebot, lui, arrive avec son propre user-agent, ses propres règles d'accès, et se confronte à des couches de sécurité qui le traitent différemment d'un visiteur humain. Résultat : une page parfaitement accessible pour vous peut renvoyer un 403, un 500, ou tout simplement ne jamais répondre pour le bot.
Quels sont les blocages les plus fréquents qui échappent aux tests manuels ?
Le robots.txt reste le piège classique — une directive Disallow oubliée, un wildcard mal placé, et des sections entières deviennent invisibles. Mais c'est loin d'être le seul coupable.
Les protections anti-bot type Cloudflare, Sucuri ou Imperva bloquent parfois Googlebot par excès de zèle. Les firewalls d'entreprise, les WAF mal configurés, les rate-limiters trop agressifs — tous peuvent rejeter le crawler sans déclencher la moindre alerte côté développement.
Et puis il y a les problèmes réseau : timeouts, DNS instables, certificats SSL mal configurés. Tout ce qui passe inaperçu lors d'un test manuel ponctuel mais qui plombe le crawl sur la durée.
Pourquoi Search Console est-il indispensable pour diagnostiquer ces blocages ?
Parce que l'outil d'inspection d'URL vous montre exactement ce que Googlebot a vu lors de sa dernière tentative de crawl. Pas une simulation, pas une approximation — le rendu réel, les en-têtes HTTP reçus, les ressources bloquées.
Le test de résultats enrichis fait pareil pour les structured data. Si Googlebot ne peut pas accéder à votre JSON-LD, vous le voyez immédiatement. C'est la seule façon de sortir des suppositions et de travailler sur des faits.
- Accessibilité navigateur ≠ accessibilité Googlebot : ce sont deux parcours techniques distincts
- Les blocages côté serveur (robots.txt, firewall, anti-bot) échappent aux tests manuels classiques
- L'outil d'inspection d'URL de Search Console est le seul diagnostic fiable de l'accès réel de Googlebot
- Les problèmes réseau (timeouts, DNS, SSL) peuvent bloquer le crawler sans symptôme visible côté utilisateur
Avis d'un expert SEO
Cette distinction est-elle vraiment si cruciale en pratique ?
Soyons honnêtes : oui, et c'est même l'une des sources d'erreurs les plus fréquentes en audit SEO. J'ai perdu le compte des sites où le client jure que « tout fonctionne » parce qu'il voit ses pages en ligne, alors que Googlebot se prend des 403 en pleine face depuis des semaines.
Le problème, c'est que les outils de monitoring classiques ne détectent pas ces blocages. Uptime Robot, Pingdom — ils testent avec des user-agents standards. Si votre WAF traite Googlebot différemment, vous ne le verrez jamais dans vos dashboards habituels.
Où sont les angles morts de cette recommandation ?
Martin Splitt a raison sur le fond, mais il simplifie un peu trop. L'outil d'inspection d'URL, c'est un snapshot à un instant T. Si Googlebot est bloqué de manière intermittente — parce que votre serveur sature à certaines heures, parce qu'un rate-limiter s'active sous charge — l'outil ne le capturera pas forcément.
Et puis il y a la question du rendu JavaScript différé. L'outil vous montre ce que Googlebot a rendu, mais pas toujours dans quelles conditions ni avec quel délai. Si votre contenu critique charge après 10 secondes parce qu'une dépendance externe est lente, l'outil peut vous dire « OK » alors que le crawl réel a timeout.
Quelles pratiques terrain complètent cette recommandation ?
Monitorer les logs serveur reste indispensable. Search Console vous dit si Googlebot a pu accéder, mais pas combien de fois il a essayé, ni quelles erreurs HTTP il a rencontrées avant de réussir (ou d'abandonner).
Et configurez des alertes sur les codes 5xx et 429 spécifiquement pour le user-agent Googlebot. Parce que ces erreurs passent sous le radar si vous ne les filtrez pas explicitement. Un 503 pour un bot, personne ne s'en aperçoit — jusqu'à ce que les pages disparaissent de l'index.
Impact pratique et recommandations
Que faut-il vérifier en priorité pour éviter ces blocages ?
Commencez par le robots.txt. Testez-le avec l'outil dédié dans Search Console, mais ne vous arrêtez pas là — vérifiez aussi que les règles ne se contredisent pas entre elles. Un Allow suivi d'un Disallow trop large, ça arrive plus souvent qu'on ne le pense.
Ensuite, inspectez vos configurations WAF et anti-bot. Si vous utilisez Cloudflare, vérifiez que Googlebot n'est pas soumis aux challenges JavaScript. Si vous avez Sucuri ou Wordfence, assurez-vous que les règles de rate-limiting exemptent explicitement les crawlers légitimes.
Testez vos pages critiques avec l'outil d'inspection d'URL après chaque mise à jour serveur. Un changement de config Apache, une modif nginx, une nouvelle règle firewall — tout ça peut casser l'accès de Googlebot sans prévenir.
Quelles erreurs techniques provoquent le plus de faux négatifs ?
Les timeouts serveur sont sournois. Votre page répond en 2 secondes pour un utilisateur, mais Googlebot attend 30 secondes une ressource bloquante et abandonne. Résultat : dans Search Console, vous voyez « Erreur de serveur » alors que techniquement, la page fonctionne.
Les certificats SSL mal configurés (chaîne de certification incomplète, cipher suites obsolètes) peuvent aussi bloquer Googlebot alors que les navigateurs modernes compensent. Et ne négligez pas les problèmes DNS — un resolver lent ou instable peut faire échouer le crawl de manière intermittente.
Comment automatiser la détection de ces problèmes ?
Mettez en place un monitoring actif des logs serveur avec un filtre sur le user-agent Googlebot. Configurez des alertes sur les codes 4xx/5xx, les timeouts, les connexions refusées. Ça demande un peu de config initiale, mais c'est le seul moyen de détecter les blocages en temps réel.
Programmez des inspections régulières via l'API Search Console pour vos pages stratégiques. Un script qui lance l'outil d'inspection toutes les semaines sur vos top landing pages et vous alerte en cas de changement de statut. C'est faisable, et ça évite les mauvaises surprises.
- Vérifier le robots.txt avec l'outil Search Console ET manuellement pour détecter les conflits de règles
- Auditer les configurations WAF, anti-bot et rate-limiting pour exempter Googlebot
- Tester l'inspection d'URL après chaque modification serveur ou déploiement
- Monitorer les logs serveur en filtrant sur le user-agent Googlebot, avec alertes sur 4xx/5xx
- Vérifier la chaîne SSL complète et les cipher suites pour éviter les rejets de connexion
- Automatiser des inspections régulières via l'API Search Console sur les pages critiques
❓ Questions frequentes
Est-ce que tous les outils anti-bot bloquent Googlebot par défaut ?
L'outil d'inspection d'URL suffit-il pour diagnostiquer tous les problèmes d'accès ?
Si mon site est accessible dans l'outil d'inspection, puis-je être sûr que Googlebot crawle correctement toutes mes pages ?
Comment savoir si mon robots.txt bloque réellement des pages importantes ?
Les problèmes d'accès de Googlebot impactent-ils immédiatement le classement ?
🎥 De la même vidéo 7
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 13/12/2024
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.