Declaration officielle
Autres déclarations de cette vidéo 7 ▾
- □ Pourquoi votre site peut-il être invisible pour Googlebot alors qu'il s'affiche parfaitement dans votre navigateur ?
- □ Comment vérifier si Googlebot crawle vraiment votre contenu JavaScript ?
- □ Pourquoi Google insiste-t-il sur la surveillance des erreurs serveur dans le rapport Statistiques d'exploration ?
- □ Faut-il vraiment s'inquiéter de chaque erreur de crawl remontée dans la Search Console ?
- □ Faut-il vraiment agir sur chaque erreur 500 détectée par Google dans le rapport de crawl ?
- □ Comment distinguer le vrai Googlebot des imposteurs dans vos logs serveur ?
- □ Pourquoi vos pages n'entrent-elles pas dans Google Search malgré tous vos efforts SEO ?
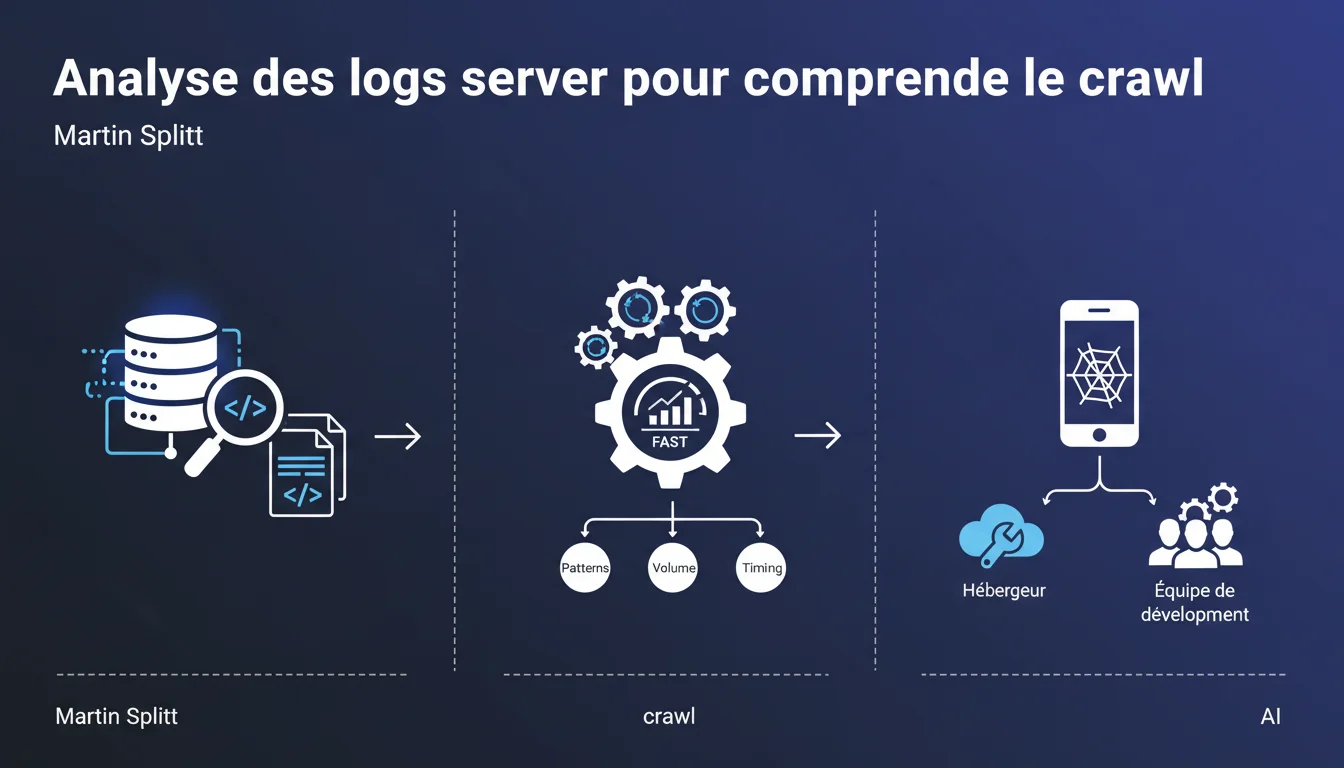
L'analyse des logs serveur permet de comprendre précisément comment Googlebot explore votre site : fréquence, volume, patterns et réponses serveur. C'est une technique avancée qui nécessite souvent l'appui de votre hébergeur ou équipe technique, mais elle offre un niveau de granularité impossible à obtenir via la Search Console seule.
Ce qu'il faut comprendre
Pourquoi les logs serveur sont-ils plus précis que la Search Console ?
Les logs serveur enregistrent chaque requête HTTP reçue par votre serveur, y compris celles de Googlebot. Contrairement à la Search Console qui agrège et échantillonne les données, les logs bruts donnent accès à 100% des interactions réelles.
Cette granularité permet d'identifier des patterns de crawl invisibles ailleurs : pages orphelines crawlées via des backlinks, redirections en chaîne, comportement du bot face aux erreurs 5xx, timing précis entre deux passages.
Quelles informations concrètes peut-on extraire des logs ?
Vous pouvez mesurer le budget crawl réellement consommé par section du site, identifier les URLs crawlées mais non indexées, détecter les boucles de redirection que Googlebot subit, repérer les pics de crawl corrélés à vos actions (publication, refonte).
Les logs révèlent aussi la réactivité de votre serveur : temps de réponse par type de page, codes HTTP réels envoyés, charge serveur générée par les bots. Autant de données exploitables pour optimiser l'infrastructure technique.
Faut-il vraiment impliquer l'équipe technique ?
Dans la majorité des cas, oui. Les fichiers de logs sont rarement accessibles directement via l'interface d'hébergement standard. Selon votre stack technique, ils peuvent être stockés différemment, fragmentés, ou nécessiter des droits d'accès spécifiques.
Certains hébergeurs limitent la durée de rétention des logs ou leur volume. L'équipe dev peut aussi mettre en place une collecte automatisée vers un outil d'analyse plutôt que de manipuler des fichiers manuellement chaque mois.
- Les logs donnent un accès 100% complet aux interactions Googlebot/serveur
- Ils permettent d'analyser le budget crawl réel par section du site
- L'exploitation nécessite souvent un accès technique non disponible en interface standard
- Cette approche complète la Search Console, elle ne la remplace pas
Avis d'un expert SEO
Cette technique est-elle vraiment accessible à tous les SEO ?
Soyons honnêtes : l'analyse de logs reste une compétence de niche. Beaucoup de SEO en parlent, peu la pratiquent régulièrement avec rigueur. Le principal frein n'est pas conceptuel mais opérationnel — obtenir les logs, les parser correctement, les croiser avec d'autres données.
Sur des sites de taille moyenne (moins de 10K pages), l'investissement temps/bénéfice peut être discutable. En revanche, sur des plateformes avec pagination infinie, facettes multiples, ou sites générant massivement des URLs paramétrées, les logs deviennent indispensables pour comprendre où part le budget crawl.
Quelles sont les limites pratiques de cette approche ?
Les logs montrent ce que Googlebot demande, pas ce qu'il indexe. Une URL crawlée 50 fois par mois peut rester non-indexée pour des raisons qualitatives que les logs n'expliquent pas. Il faut donc systématiquement croiser avec la Search Console et des audits de contenu.
Autre point : les logs ne capturent que le crawl HTTP classique. Le rendu JavaScript et la phase d'indexation différée restent opaques. Si votre site repose massivement sur du JS client-side, les logs ne vous diront pas si Googlebot a réussi à extraire le contenu après exécution.
Google survend-il l'utilité de cette technique ?
Martin Splitt qualifie ça de "puissant" — c'est vrai, mais avec une courbe d'apprentissage raide. Google pousse cette approche notamment parce qu'elle responsabilise les SEO sur l'infrastructure technique plutôt que sur des signaux on-page faciles à manipuler.
En pratique, 80% des diagnostics crawl peuvent être faits via Search Console + un crawler comme Screaming Frog. Les logs deviennent critiques dans des cas précis : refonte avec changement d'arborescence, explosion inexpliquée du crawl, debug de comportements Googlebot erratiques. [À vérifier] : l'impact réel d'optimisations basées uniquement sur l'analyse de logs reste difficile à isoler, car les gains sont souvent confondus avec d'autres optimisations techniques simultanées.
Impact pratique et recommandations
Par où commencer pour accéder aux logs serveur ?
Identifiez d'abord votre type d'hébergement. Sur un mutualisé classique, les logs sont parfois disponibles via cPanel ou Plesk, mais souvent incomplets. Sur un VPS/dédié, vous aurez un accès direct aux fichiers Apache/Nginx, généralement dans /var/log/.
Si vous êtes sur un cloud managé (AWS, GCP), les logs peuvent être streamés vers CloudWatch, BigQuery ou équivalent. C'est plus puissant mais nécessite de configurer la collecte. Dans tous les cas, documentez qui dans l'équipe a les accès et comment récupérer les fichiers de manière récurrente.
Quels outils utiliser pour analyser les logs efficacement ?
Pour débuter : OnCrawl, Botify, ou Screaming Frog Log Analyzer. Ces outils parsent les logs et génèrent des dashboards visuels (crawl par section, fréquence, codes HTTP, user-agents). Ils croisent aussi les données avec un crawl du site pour identifier les pages crawlées mais non découvertes.
Pour des analyses custom ou des gros volumes, envisagez des stacks type ELK (Elasticsearch, Logstash, Kibana) ou BigQuery + Data Studio. Ça demande des compétences data mais offre une flexibilité totale sur les métriques et corrélations.
Comment interpréter les données pour prendre des décisions ?
Concentrez-vous sur les anomalies et les tendances. Un pic de crawl soudain sur une section peu stratégique peut signaler un problème de maillage interne ou une boucle de pagination. À l'inverse, une chute brutale du crawl après une mise à jour serveur peut indiquer des erreurs 5xx temporaires non loguées dans la Search Console.
Identifiez les URLs crawlées fréquemment mais générant peu de trafic organique — ce sont des candidats à la désindexation ou au noindex pour libérer du budget crawl. Croisez ces insights avec les données business pour éviter de bloquer des pages qui convertissent malgré un faible SEO.
- Vérifier l'accès aux logs avec l'équipe technique ou l'hébergeur
- Choisir un outil d'analyse adapté au volume et à la complexité du site
- Configurer une collecte automatisée pour suivre l'évolution dans le temps
- Croiser systématiquement logs, Search Console et crawls pour une vue complète
- Documenter les patterns observés et les corréler avec les actions SEO menées
❓ Questions frequentes
Les logs serveur remplacent-ils la Search Console pour le suivi du crawl ?
Quelle est la durée de rétention minimale recommandée pour les logs ?
Peut-on identifier tous les crawlers de Google dans les logs ?
Faut-il analyser les logs en continu ou ponctuellement ?
Les logs permettent-ils de mesurer l'impact d'une amélioration du temps de réponse serveur ?
🎥 De la même vidéo 7
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 13/12/2024
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.