Declaration officielle
Autres déclarations de cette vidéo 16 ▾
- □ Faut-il vraiment prévenir Google lors d'une refonte de site ?
- □ Google détecte-t-il vraiment le format WEBP par l'en-tête HTTP plutôt que par l'extension du fichier ?
- □ Comment Google évalue-t-il vraiment la proéminence d'une vidéo sur une page ?
- □ Le contenu dupliqué multilingue pénalise-t-il vraiment votre référencement international ?
- □ Faut-il préférer un ccTLD au .com pour cibler un marché local ?
- □ Pourquoi Google insiste-t-il pour isoler les migrations de site de toute autre refonte ?
- □ Pourquoi AdsBot fausse-t-il vos statistiques de crawl dans Search Console ?
- □ Hreflang : faut-il regrouper toutes les annotations dans un seul sitemap ou les séparer par langue ?
- □ Google propose-t-il un bouton pour réindexer massivement un site après refonte ?
- □ Strong vs Bold : Google fait-il vraiment la différence entre ces deux balises ?
- □ Le LCP ne mesure-t-il vraiment que le viewport visible au chargement ?
- □ Le sitemap XML est-il vraiment indispensable pour être indexé par Google ?
- □ Faut-il utiliser hreflang 'de' ou 'de-de' pour cibler les germanophones ?
- □ Google réessaie-t-il vraiment d'indexer vos pages après une erreur 401 ou serveur down ?
- □ Faut-il vraiment imbriquer ses données structurées pour indiquer le focus principal d'une page ?
- □ Faut-il vraiment privilégier l'attribut alt plutôt que l'OCR pour le texte dans les images ?
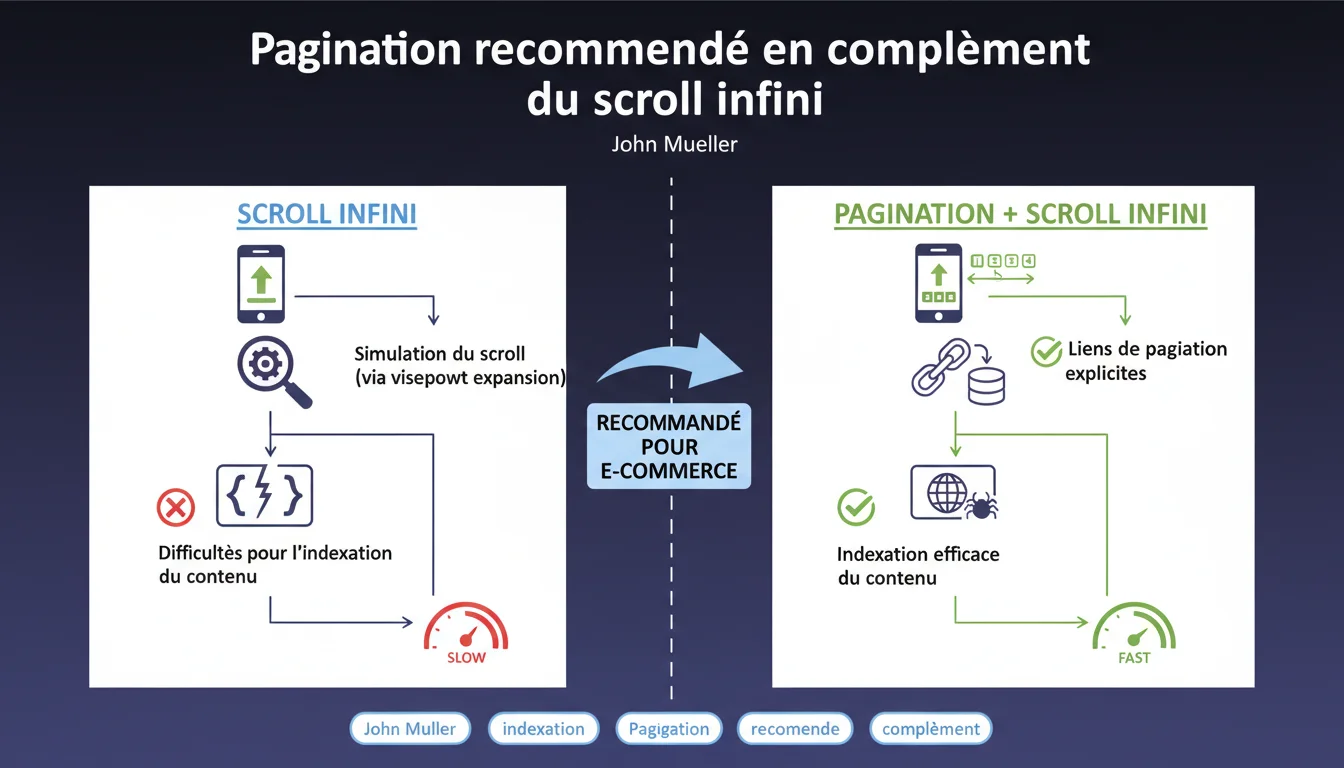
Google recommande d'ajouter des liens de pagination classiques en plus du scroll infini. Le défilement infini nécessite une simulation du scroll (viewport expansion) qui s'avère inefficace et peut bloquer l'indexation de contenus. Pour les sites e-commerce, la pagination reste la solution la plus fiable pour garantir l'exploration complète du catalogue.
Ce qu'il faut comprendre
Pourquoi le scroll infini pose-t-il problème aux moteurs de recherche ?
Les crawlers de Google ne naviguent pas comme un utilisateur lambda. Ils analysent le DOM initial d'une page, exécutent le JavaScript, puis doivent détecter si du contenu supplémentaire se charge au scroll.
Pour gérer le scroll infini, Google utilise une technique appelée viewport expansion : le bot simule un agrandissement progressif de la fenêtre pour déclencher le chargement de nouveaux éléments. Cette approche consomme énormément de ressources et ne garantit pas que tout le contenu sera découvert — surtout si l'implémentation JavaScript présente des latences ou des conditions de chargement complexes.
Qu'est-ce que la viewport expansion concrètement ?
Il s'agit d'une simulation technique où Googlebot étend artificiellement la zone d'affichage pour forcer le déclenchement des événements de scroll. Le problème ? Cette méthode n'est pas instantanée, dépend de la réactivité du serveur, et surtout, elle n'est pas prioritaire dans l'allocation du crawl budget.
Si votre site charge du contenu au scroll de manière asynchrone avec des délais ou des conditions (intersection observers complexes, throttling, lazy loading agressif), Googlebot peut tout simplement abandonner avant d'avoir tout découvert.
Quelles sont les conséquences directes pour un site e-commerce ?
Un catalogue de 500 produits présenté en scroll infini peut voir seulement les 50 premiers produits indexés. Les fiches produits situées plus bas dans le flux ne reçoivent aucun lien HTML classique, donc aucun signal de crawl direct.
Résultat : des pages orphelines, invisibles dans l'index, même si elles sont techniquement accessibles pour un utilisateur réel. Le trafic organique se concentre sur une fraction du catalogue, et le potentiel SEO est gâché.
- Le scroll infini sans pagination rend l'exploration inefficace pour les crawlers
- La viewport expansion consomme du crawl budget sans garantie de résultat
- Les produits en bas de page risquent de ne jamais être indexés
- Une pagination classique en complément est la solution recommandée par Google
Avis d'un expert SEO
Cette recommandation est-elle vraiment nouvelle ?
Non. Google martèle ce message depuis des années, mais la nuance ici réside dans le terme « fortement recommandé ». Ce n'est plus un conseil mou — c'est un avertissement direct pour les sites e-commerce qui misent tout sur le scroll infini sans filet de sécurité.
On observe sur le terrain que les sites qui ont adopté le scroll infini sans pagination complémentaire souffrent effectivement d'une indexation tronquée. Les logs serveur montrent que Googlebot s'arrête souvent après quelques dizaines d'éléments, même si la page en contient des centaines.
Tous les types de scroll infini sont-ils concernés de la même manière ?
Là, il faut distinguer. Un scroll infini sur une page blog ou un flux d'actualités pose moins de problèmes qu'un catalogue produit. Pourquoi ? Parce que les articles de blog sont généralement accessibles via d'autres chemins (menu, sitemap, liens internes). Les produits e-commerce, eux, dépendent souvent uniquement de la page catégorie pour être découverts.
Si votre scroll infini charge des contenus déjà accessibles ailleurs (maillage interne solide, sitemap XML exhaustif), le risque est moindre. Mais si ces contenus n'existent nulle part ailleurs sous forme de lien HTML classique, vous jouez à la roulette russe avec votre indexation. [À vérifier] dans vos propres logs de crawl.
La pagination complète résout-elle vraiment tous les problèmes ?
Presque. Une pagination classique avec des liens rel="next" et rel="prev" (même si Google ne les utilise plus officiellement) offre un chemin de crawl clair et prévisible. Chaque page a une URL distincte, un contenu délimité, un budget de crawl calculable.
Mais attention : une pagination mal conçue (URLs dupliquées, canonicales incohérentes, pages orphelines) peut créer d'autres problèmes. Le diable est dans les détails d'implémentation.
Impact pratique et recommandations
Que faut-il implémenter concrètement sur un site e-commerce ?
Ajoute des liens de pagination HTML classiques en bas de tes pages catégories, même si le scroll infini reste actif pour l'expérience utilisateur. Ces liens doivent pointer vers des URLs distinctes (ex: /categorie?page=2, /categorie?page=3) et être présents dans le DOM sans nécessiter d'interaction JavaScript.
Chaque page paginée doit avoir sa propre URL, son propre contenu délimité, et des balises canonical cohérentes. Le scroll infini peut cohabiter : l'utilisateur scroll, le bot clique sur les liens de pagination.
Comment vérifier que Googlebot explore bien tout le catalogue ?
Analyse tes logs serveur. Repère les URLs de pages catégories et vérifie combien de produits Googlebot découvre réellement. Si tu constates que le bot s'arrête systématiquement après X éléments, c'est le symptôme d'un problème de viewport expansion.
Vérifie aussi la Search Console : combien de fiches produits sont indexées par rapport au nombre total dans ton catalogue ? Un écart important (> 20%) signale un souci d'exploration.
Quelles erreurs éviter lors de l'implémentation ?
Ne crée pas de contenus dupliqués entre les pages paginées et le scroll infini. Si /categorie affiche les produits 1 à 50 en scroll infini, /categorie?page=1 doit afficher exactement les mêmes produits 1 à 50, pas une variation aléatoire.
Évite les canonicales vers la page 1 pour toutes les pages paginées — c'est une erreur classique qui annule l'intérêt de la pagination. Chaque page doit être auto-canonicale ou utiliser rel="next"/rel="prev" si tu veux signaler une série.
- Ajouter des liens de pagination HTML en complément du scroll infini
- Utiliser des URLs distinctes pour chaque page de pagination (ex: ?page=2)
- Vérifier que ces liens sont présents dans le DOM initial, pas injectés par JS après interaction
- Configurer des canonicales cohérentes (auto-canonicales pour chaque page)
- Analyser les logs serveur pour vérifier le comportement de Googlebot
- Comparer le nombre de produits indexés avec le catalogue total dans la Search Console
- Tester le crawl avec Screaming Frog ou un outil similaire pour simuler le comportement bot
❓ Questions frequentes
Peut-on utiliser le scroll infini ET la pagination sur la même page ?
Le sitemap XML compense-t-il l'absence de pagination ?
Faut-il utiliser rel='next' et rel='prev' sur les pages paginées ?
Le lazy loading des images pose-t-il les mêmes problèmes que le scroll infini ?
Comment gérer les filtres de catégorie avec scroll infini et pagination ?
🎥 De la même vidéo 16
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 09/03/2023
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.