Declaration officielle
Autres déclarations de cette vidéo 16 ▾
- □ Faut-il vraiment prévenir Google lors d'une refonte de site ?
- □ Google détecte-t-il vraiment le format WEBP par l'en-tête HTTP plutôt que par l'extension du fichier ?
- □ Comment Google évalue-t-il vraiment la proéminence d'une vidéo sur une page ?
- □ Le contenu dupliqué multilingue pénalise-t-il vraiment votre référencement international ?
- □ Faut-il préférer un ccTLD au .com pour cibler un marché local ?
- □ Pourquoi Google insiste-t-il pour isoler les migrations de site de toute autre refonte ?
- □ Pourquoi AdsBot fausse-t-il vos statistiques de crawl dans Search Console ?
- □ Hreflang : faut-il regrouper toutes les annotations dans un seul sitemap ou les séparer par langue ?
- □ Google propose-t-il un bouton pour réindexer massivement un site après refonte ?
- □ Strong vs Bold : Google fait-il vraiment la différence entre ces deux balises ?
- □ Le LCP ne mesure-t-il vraiment que le viewport visible au chargement ?
- □ Le sitemap XML est-il vraiment indispensable pour être indexé par Google ?
- □ Faut-il utiliser hreflang 'de' ou 'de-de' pour cibler les germanophones ?
- □ Google réessaie-t-il vraiment d'indexer vos pages après une erreur 401 ou serveur down ?
- □ Faut-il vraiment privilégier l'attribut alt plutôt que l'OCR pour le texte dans les images ?
- □ Pourquoi le scroll infini pénalise-t-il l'indexation de vos pages e-commerce ?
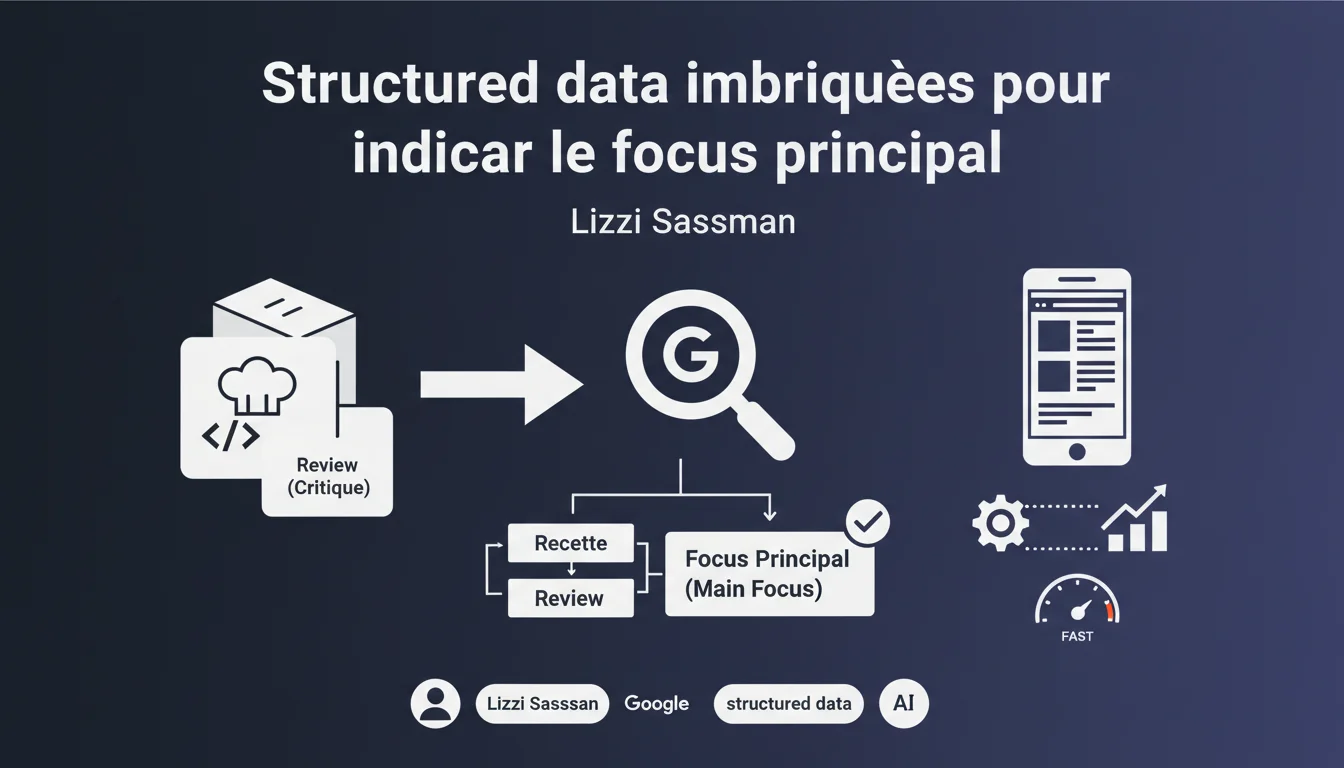
Google utilise l'imbrication des données structurées pour identifier le sujet principal d'une page. Concrètement : une review imbriquée dans une recette signale que la page est avant tout une recette, pas un article d'avis. Cette hiérarchie aide l'algorithme à afficher le bon rich snippet.
Ce qu'il faut comprendre
Pourquoi Google a-t-il besoin de cette hiérarchie dans les données structurées ?
Le problème est simple : une page peut contenir plusieurs types de contenus. Une recette de lasagnes peut inclure des avis d'utilisateurs, une vidéo de démonstration, et des informations sur l'auteur. Sans hiérarchie claire, Google doit deviner quel est le sujet principal.
L'imbrication des données structurées résout cette ambiguïté. En plaçant un objet Review à l'intérieur d'un objet Recipe, vous indiquez explicitement que la recette est le contenu principal et que l'avis n'est qu'un élément complémentaire. Cela influence directement quel rich snippet sera affiché dans les SERP.
Comment fonctionne techniquement cette imbrication ?
Dans le JSON-LD, certaines propriétés acceptent des objets imbriqués. Par exemple, le type Recipe possède une propriété "aggregateRating" qui peut contenir un objet AggregateRating. De même, "review" peut contenir un tableau d'objets Review.
Cette architecture n'est pas arbitraire — elle suit la logique du vocabulaire Schema.org qui définit des relations parent-enfant entre types de contenus. Google exploite cette structure pour comprendre la relation sémantique entre les différents éléments de la page.
Tous les types de données structurées peuvent-ils être imbriqués ?
Non, et c'est là que ça coince. Chaque type Schema.org définit quelles propriétés il accepte et quels types d'objets peuvent y être imbriqués. La documentation Google de chaque fonctionnalité de recherche (recettes, événements, produits, etc.) précise ces règles.
Certaines imbrications sont obligatoires pour être éligible aux rich snippets. D'autres sont optionnelles mais recommandées. Et certaines combinaisons, bien que techniquement valides selon Schema.org, ne sont pas reconnues par Google pour déclencher des fonctionnalités spécifiques.
- L'imbrication signale la hiérarchie : le type parent est le contenu principal, les types imbriqués sont complémentaires
- Influence directe sur les rich snippets : Google choisit le format d'affichage selon le type principal identifié
- Pas d'imbrication universelle : chaque type a des règles spécifiques définies dans la documentation Google
- Validation technique nécessaire : utiliser l'outil de test des résultats enrichis pour vérifier la compatibilité
Avis d'un expert SEO
Cette logique d'imbrication est-elle systématiquement respectée par Google ?
Sur le papier, c'est cohérent. Dans la pratique ? Les observations terrain montrent que Google arrive souvent à identifier le contenu principal même sans imbrication stricte, notamment grâce au traitement sémantique du contenu textuel lui-même.
Plusieurs cas observés où des pages avec des données structurées "plates" (plusieurs types au même niveau) obtiennent quand même le bon rich snippet. L'algorithme semble croiser les données structurées avec d'autres signaux : position dans le DOM, volume de contenu, balises HTML sémantiques. [A vérifier] dans quelle mesure l'imbrication est un facteur déterminant versus un signal parmi d'autres.
Quels risques si on n'imbrique pas correctement ?
Le risque principal : perte d'éligibilité aux rich snippets. Si Google ne parvient pas à déterminer le type de contenu principal, il peut simplement ne pas afficher de résultat enrichi. Pire, il pourrait afficher le mauvais type de snippet — imaginons une page produit qui s'affiche comme un article de blog.
Attention aussi aux erreurs de validation. Certaines propriétés requises pour un type donné deviennent obligatoires uniquement si ce type est déclaré comme principal. Une imbrication incorrecte peut générer des avertissements dans la Search Console qui, même s'ils ne sont pas bloquants, signalent une implémentation sous-optimale.
Dans quels cas l'imbrication n'est-elle pas la meilleure approche ?
Soyons honnêtes : quand une page couvre véritablement plusieurs sujets d'importance égale, l'imbrication force une hiérarchie artificielle. Exemple typique : une page événement qui inclut à la fois des informations sur le lieu (LocalBusiness) et l'événement lui-même (Event).
Dans ces cas, utiliser des blocs de données structurées séparés au même niveau peut être plus approprié. Google devra faire un choix pour le rich snippet, mais au moins vous n'aurez pas faussé la sémantique réelle du contenu. Le compromis à assumer : vous laissez Google décider plutôt que de contrôler explicitement.
Impact pratique et recommandations
Que faut-il auditer en priorité sur vos pages existantes ?
Commencez par identifier les pages qui combinent plusieurs types de contenus : pages produits avec avis, articles avec vidéos intégrées, pages auteur avec liste d'articles, etc. Ce sont les candidates à une restructuration de vos données structurées.
Utilisez l'outil de test des résultats enrichis de Google pour chaque type de page. Vérifiez non seulement la validation technique, mais aussi le type de contenu principal détecté. Si l'outil identifie un type différent de celui que vous visez, c'est un signal d'alarme.
Comment implémenter l'imbrication sans tout casser ?
Pour du JSON-LD (le format recommandé), la refactorisation est relativement propre. Identifiez le type principal, puis intégrez les types secondaires comme valeurs de propriétés appropriées. Par exemple, pour une recette avec avis :
Le type Recipe devient l'objet racine. Les avis individuels s'intègrent dans la propriété "review" comme tableau d'objets Review. Le rating agrégé va dans "aggregateRating". Cette structure remplace les multiples blocs JSON-LD séparés que vous aviez peut-être initialement.
- Cartographier tous les types de pages qui combinent plusieurs types de contenus
- Consulter la documentation Google spécifique à chaque fonctionnalité visée (recettes, produits, événements, etc.)
- Identifier quelles propriétés acceptent des objets imbriqués selon Schema.org
- Refactoriser le JSON-LD en plaçant le contenu principal comme type racine
- Tester chaque page avec l'outil de résultats enrichis de Google
- Vérifier dans la Search Console l'absence de nouvelles erreurs après déploiement
- Monitorer l'évolution des impressions en rich snippets dans les semaines suivantes
Quelles erreurs techniques éviter absolument ?
Première erreur classique : imbriquer dans le mauvais sens. Si votre page est principalement un avis de produit (type Review), le produit doit être imbriqué dans la review via la propriété "itemReviewed", et non l'inverse. La hiérarchie doit refléter le contenu réel de la page.
Deuxième piège : omettre des propriétés devenues requises. Quand vous changez le type principal, les champs obligatoires changent aussi. Un Product exige "name" et "image", mais si vous l'imbriquez dans une Review, cette dernière a ses propres exigences ("author", "reviewRating", etc.).
❓ Questions frequentes
Peut-on utiliser plusieurs blocs JSON-LD séparés plutôt qu'imbriquer les données ?
L'imbrication fonctionne-t-elle de la même manière en microdata ou RDFa ?
Si je change ma structure de données, vais-je perdre temporairement mes rich snippets ?
Faut-il imbriquer même si la documentation Google ne le mentionne pas explicitement ?
Les données structurées imbriquées influencent-elles le classement au-delà des rich snippets ?
🎥 De la même vidéo 16
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 09/03/2023
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.