Official statement
Other statements from this video 7 ▾
- □ Pourquoi les frameworks JavaScript génèrent-ils des soft 404 sur les sites à fort inventaire ?
- □ Robots.txt bloque-t-il vos ressources critiques sans que vous le sachiez ?
- □ Pourquoi l'historique du robots.txt dans Search Console change-t-il la donne ?
- □ Une requête AJAX qui échoue peut-elle tuer l'indexation de toute votre page ?
- □ Comment Chrome DevTools peut-il révéler les problèmes de rendu que Googlebot rencontre sur vos pages ?
- □ Pourquoi Google pénalise-t-il les sites qui gèrent mal leurs erreurs JavaScript ?
- □ La résoumission manuelle d'URLs via Search Console accélère-t-elle vraiment la réindexation ?
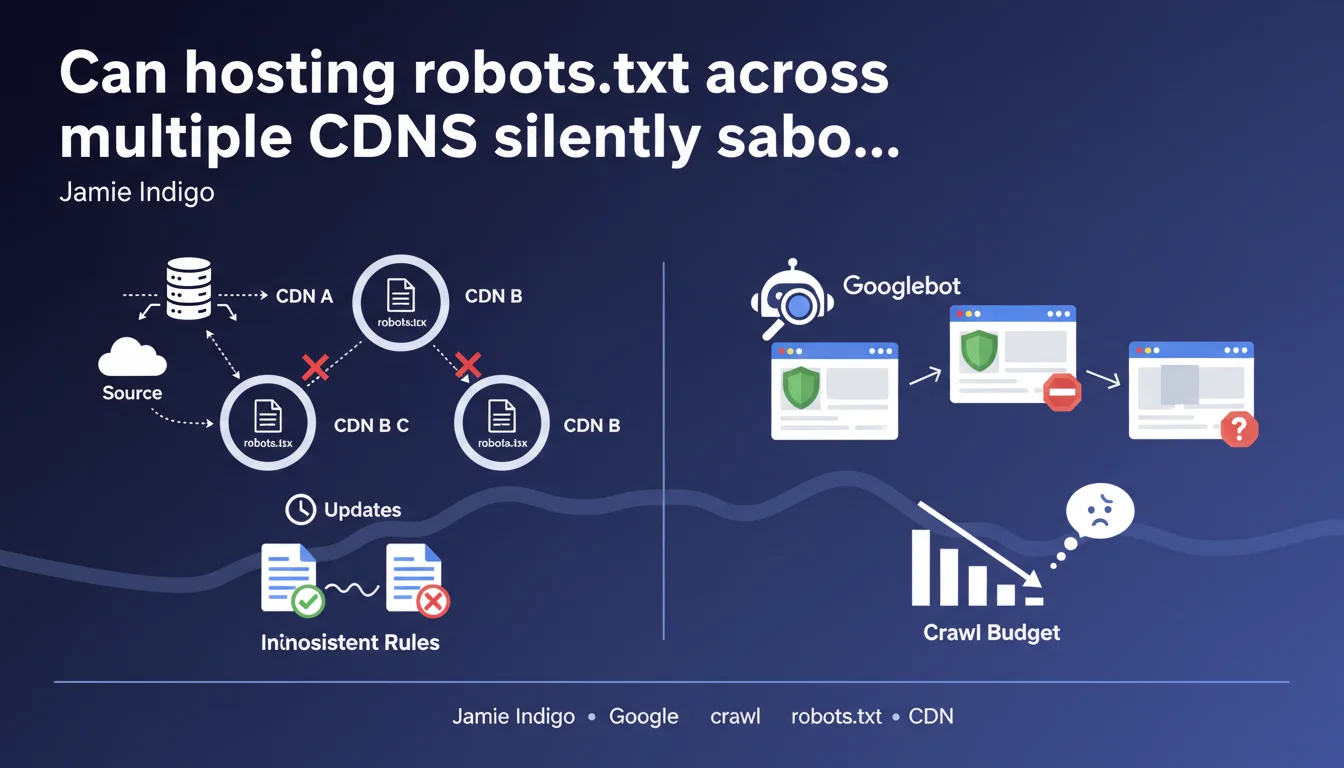
When a robots.txt file is distributed across multiple CDNs, they don't all synchronize instantly when you make changes. The result: Googlebot may receive conflicting versions of the file depending on which CDN it queries, creating inconsistencies in how certain resources are crawled. A technical problem that's often underestimated but can block the indexation of strategic content.
What you need to understand
How can a robots.txt file end up on multiple CDNs?
Modern web architectures frequently use multiple CDNs in parallel to optimize availability and performance. This strategy, called multi-CDN, distributes traffic across different providers — sometimes for redundancy, sometimes for geolocation optimization.
The robots.txt, although it's a unique file at the root of your domain, also flows through these infrastructures. When you modify this file on your origin server, each CDN must refresh its cached copy. And that's where things get stuck.
Why is synchronization never instant?
Each CDN applies its own TTL rules (Time To Live) and cache purge mechanisms. One CDN might update its cache in seconds, another in minutes or even hours depending on configuration.
Googlebot queries your domain from different datacenters, each potentially being routed to a different CDN. During this desynchronization window, some crawlers see the old robots.txt (which still blocks resources), others see the new version. Result: inconsistencies in crawling.
What are the concrete risks for indexation?
Imagine you unblock critical CSS or JavaScript files needed for page rendering. If one CDN is still serving the old robots.txt version that blocks these resources, Googlebot won't be able to load them — and your page risks being misunderstood or indexed with an incomplete DOM.
The opposite is equally problematic: you block a section of the site, but some CDNs continue serving the old file that allows crawling. Sensitive pages remain crawlable longer than intended.
- Asynchronous propagation of robots.txt modifications across CDNs
- Googlebot receives conflicting versions depending on which datacenter is queried
- Risk of unintended blocking of critical rendering resources
- Or conversely, prolonged exposure of sections meant to be blocked
- Direct impact on indexation quality during the desynchronization period
SEO Expert opinion
Does this claim really reflect a frequent problem in the field?
Yes, and it's actually underestimated. Multi-CDN architectures have become mainstream, especially for international or mission-critical sites. But few technical leads anticipate that robots.txt, perceived as a static and simple file, faces the same caching constraints as an image or stylesheet.
I've observed cases where an urgent unblocking of JavaScript resources (to fix a rendering issue) took several hours to propagate. In the meantime, certain pages continued to be crawled with incomplete DOM — and Google Search Console showed contradictory alerts depending on which bot had tested.
Does Google provide enough detail to diagnose this problem?
[To verify] — The statement remains intentionally vague. Jamie Indigo doesn't specify how long this desynchronization typically lasts, or how Googlebot handles these inconsistencies internally. Does it average? Does it prioritize the most recent version detected? No indication.
You can guess that Google observes the problem, but without providing concrete metrics. It's therefore difficult to calibrate urgency or quantify the actual impact on a given site. Manual monitoring via tests from different datacenters remains necessary — tedious, but unavoidable.
In what cases does this risk become negligible?
If your robots.txt changes rarely — say once per quarter — and you're not blocking resources critical for rendering, the impact remains marginal. A desynchronization of a few hours on a stable file breaks nothing.
However, if you iterate frequently on this file (for example to manage staging environments, progressive migrations, or unblocking test sections), you're squarely in the danger zone. Each modification becomes a gamble on propagation speed.
Practical impact and recommendations
What should you do concretely to limit this risk?
First step: audit your CDN architecture. Identify how many providers serve your robots.txt and what their default TTL policies are. Some CDNs allow you to force a short TTL or immediate purge on specific files — that's exactly what you need to configure for robots.txt.
Second axis: plan robots.txt modifications as you would a critical application deployment. Avoid impulsive changes. Document each modification, test from multiple geographic locations, and wait for complete propagation before validating the effect in Search Console.
Third lever: consider simplifying your CDN stack if multi-CDN doesn't deliver measurable benefit. A single well-configured CDN mechanically reduces desynchronization risks, even if it may impact geographic redundancy.
How can you verify that all your CDNs serve the same version?
Use tools like curl with forced DNS resolution to query each CDN individually. For example: curl -H "Host: example.com" https://IP_CDN_1/robots.txt. Compare responses and headers (notably Last-Modified or ETag).
Automate this monitoring if your modifications are frequent. A daily script that alerts on CDN divergence can spare you days of debugging in case of unexplained indexation problems.
What mistakes should you absolutely avoid?
Never assume that manual cache purge on one CDN immediately impacts all edge nodes. Even after purge, some peripheral servers may retain a copy for several minutes.
Also avoid quickly blocking and unblocking the same section in robots.txt — for example to test a behavior. This yoyo amplifies inconsistencies and confuses Googlebot. Prefer testing on a non-indexed staging subdomain.
- Audit robots.txt TTL configuration on each CDN
- Configure short TTL or automatic purge on this file
- Document and plan each robots.txt modification
- Test propagation from multiple locations before validation
- Automate coherence verification across CDNs (curl + scripts)
- Avoid frequent modifications or rapid switches
- Prefer a single CDN if multi-CDN isn't strategic
- Monitor Search Console for crawl inconsistency detection
❓ Frequently Asked Questions
Combien de temps dure typiquement une désynchronisation entre CDN pour robots.txt ?
Googlebot privilégie-t-il une version du robots.txt s'il en voit plusieurs différentes ?
Faut-il éviter complètement les architectures multi-CDN si on veut un SEO optimal ?
Comment savoir si mon site est affecté par ce problème actuellement ?
Est-ce que ce problème concerne aussi d'autres fichiers comme sitemap.xml ?
🎥 From the same video 7
Other SEO insights extracted from this same Google Search Central video · published on 02/03/2023
🎥 Watch the full video on YouTube →
💬 Comments (0)
Be the first to comment.