Declaration officielle
Autres déclarations de cette vidéo 7 ▾
- □ Pourquoi les frameworks JavaScript génèrent-ils des soft 404 sur les sites à fort inventaire ?
- □ Robots.txt bloque-t-il vos ressources critiques sans que vous le sachiez ?
- □ Pourquoi l'historique du robots.txt dans Search Console change-t-il la donne ?
- □ Une requête AJAX qui échoue peut-elle tuer l'indexation de toute votre page ?
- □ Comment Chrome DevTools peut-il révéler les problèmes de rendu que Googlebot rencontre sur vos pages ?
- □ Pourquoi Google pénalise-t-il les sites qui gèrent mal leurs erreurs JavaScript ?
- □ La résoumission manuelle d'URLs via Search Console accélère-t-elle vraiment la réindexation ?
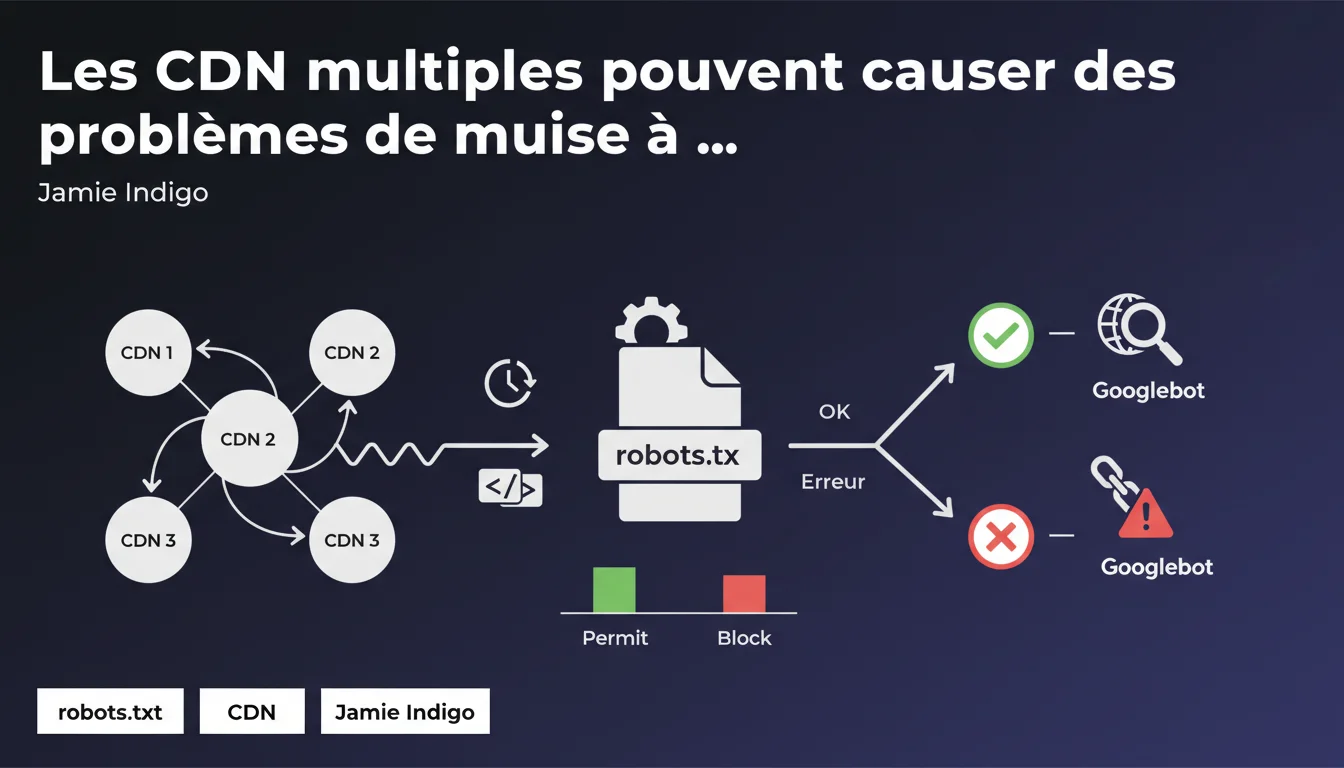
Quand un robots.txt est diffusé via plusieurs CDN, tous ne se synchronisent pas instantanément lors d'une modification. Résultat : Googlebot peut recevoir des versions contradictoires du fichier selon le CDN interrogé, créant des incohérences dans le crawl de certaines ressources. Un problème technique souvent sous-estimé qui peut bloquer l'indexation de contenus stratégiques.
Ce qu'il faut comprendre
Comment un fichier robots.txt peut-il se retrouver sur plusieurs CDN ?
Les architectures web modernes utilisent fréquemment plusieurs CDN en parallèle pour optimiser la disponibilité et les performances. Cette stratégie, appelée multi-CDN, répartit le trafic entre différents fournisseurs — parfois pour la redondance, parfois pour la géolocalisation.
Le robots.txt, bien qu'il soit un fichier unique à la racine du domaine, transite lui aussi par ces infrastructures. Quand vous modifiez ce fichier côté serveur origine, chaque CDN doit rafraîchir sa copie en cache. Et c'est là que ça coince.
Pourquoi la synchronisation n'est-elle jamais instantanée ?
Chaque CDN applique ses propres règles de TTL (Time To Live) et ses mécanismes de purge de cache. Un CDN peut mettre à jour son cache en quelques secondes, un autre en plusieurs minutes, voire heures selon la configuration.
Googlebot interroge votre domaine depuis différents datacenters, chacun pouvant être routé vers un CDN distinct. Pendant cette fenêtre de désynchronisation, certains crawlers voient l'ancien robots.txt (qui bloque encore des ressources), d'autres la nouvelle version. Résultat : incohérences dans le crawl.
Quels risques concrets pour l'indexation ?
Imaginons que vous débloquez des fichiers CSS ou JavaScript critiques pour le rendu de vos pages. Si un CDN sert encore l'ancienne version du robots.txt qui bloque ces ressources, Googlebot ne pourra pas les charger — et votre page risque d'être mal comprise ou indexée avec un DOM incomplet.
L'inverse est tout aussi problématique : vous bloquez une section du site, mais certains CDN continuent de servir l'ancien fichier qui autorise le crawl. Des pages sensibles restent crawlables plus longtemps que prévu.
- Propagation asynchrone des modifications de robots.txt entre CDN
- Googlebot reçoit des versions contradictoires selon le datacenter sollicité
- Risque de blocage involontaire de ressources critiques pour le rendu
- Ou à l'inverse, exposition prolongée de sections censées être bloquées
- Impact direct sur la qualité de l'indexation pendant la période de désynchronisation
Avis d'un expert SEO
Cette déclaration reflète-t-elle vraiment un problème fréquent sur le terrain ?
Oui, et c'est même sous-estimé. Les architectures multi-CDN se sont démocratisées, notamment pour les sites internationaux ou critiques. Mais peu de responsables techniques anticipent que le robots.txt, fichier perçu comme statique et simple, subit les mêmes contraintes de cache qu'une image ou une feuille de style.
J'ai observé des cas où un déblocage urgent de ressources JavaScript (pour corriger un problème de rendu) mettait plusieurs heures à se propager. Entre-temps, certaines pages continuaient d'être crawlées avec le DOM incomplet — et Google Search Console affichait des alertes contradictoires selon le bot qui avait testé.
Google donne-t-il suffisamment de détails pour diagnostiquer ce problème ?
[À vérifier] — La déclaration reste volontairement vague. Jamie Indigo ne précise pas combien de temps dure typiquement cette désynchronisation, ni comment Googlebot gère ces incohérences en interne. Fait-il une moyenne ? Privilégie-t-il la version la plus récente détectée ? Aucune indication.
On devine que Google constate le problème, mais sans fournir de métrique concrète. Difficile donc de calibrer l'urgence ou de quantifier l'impact réel sur un site donné. Une surveillance manuelle via des tests depuis différents datacenters reste nécessaire — fastidieux, mais incontournable.
Dans quels cas ce risque devient-il négligeable ?
Si votre robots.txt change rarement — disons une fois par trimestre — et que vous ne bloquez pas de ressources critiques pour le rendu, l'impact reste marginal. Une désynchronisation de quelques heures sur un fichier stable ne casse rien.
En revanche, si vous itérez souvent sur ce fichier (par exemple pour gérer des environnements de staging, des migrations progressives, ou des déblocages de sections tests), vous êtes en plein dans la zone rouge. Chaque modification devient un pari sur la vitesse de propagation.
Impact pratique et recommandations
Que faut-il faire concrètement pour limiter ce risque ?
Première mesure : auditer votre architecture CDN. Identifiez combien de fournisseurs servent votre robots.txt et quelles sont leurs politiques de TTL par défaut. Certains CDN permettent de forcer un TTL court ou une purge immédiate sur des fichiers spécifiques — c'est exactement ce qu'il faut configurer pour robots.txt.
Deuxième axe : planifier les modifications du robots.txt comme vous le feriez pour un déploiement applicatif critique. Évitez les changements impulsifs. Documentez chaque modification, testez depuis plusieurs localisations géographiques, et attendez une propagation complète avant de valider l'effet dans Search Console.
Troisième levier : envisagez de simplifier votre stack CDN si le multi-CDN n'apporte pas de bénéfice mesurable. Un seul CDN bien configuré réduit mécaniquement les risques de désynchronisation, même si cela peut impacter la redondance géographique.
Comment vérifier que tous vos CDN servent la même version ?
Utilisez des outils comme curl avec résolution DNS forcée pour interroger chaque CDN individuellement. Par exemple : curl -H "Host: example.com" https://IP_CDN_1/robots.txt. Comparez les réponses et les headers (notamment Last-Modified ou ETag).
Automatisez ce monitoring si vos modifications sont fréquentes. Un script quotidien qui alerte en cas de divergence entre CDN peut vous épargner des journées de debug en cas de problème d'indexation inexpliqué.
Quelles erreurs éviter absolument ?
Ne jamais supposer qu'une purge manuelle de cache sur un CDN impacte immédiatement tous les edge nodes. Même après purge, certains serveurs périphériques peuvent conserver une copie pendant quelques minutes.
Évitez aussi de bloquer puis débloquer rapidement une même section dans robots.txt — par exemple pour tester un comportement. Ce yoyo amplifie les incohérences et sème la confusion chez Googlebot. Préférez des tests sur un sous-domaine staging non indexé.
- Auditer la configuration TTL de robots.txt sur chaque CDN
- Configurer un TTL court ou une purge automatique sur ce fichier
- Documenter et planifier chaque modification du robots.txt
- Tester la propagation depuis plusieurs localisations avant validation
- Automatiser la vérification de cohérence entre CDN (curl + scripts)
- Éviter les modifications fréquentes ou les bascules rapides
- Privilégier un seul CDN si le multi-CDN n'est pas stratégique
- Monitorer Search Console pour détecter des incohérences de crawl
❓ Questions frequentes
Combien de temps dure typiquement une désynchronisation entre CDN pour robots.txt ?
Googlebot privilégie-t-il une version du robots.txt s'il en voit plusieurs différentes ?
Faut-il éviter complètement les architectures multi-CDN si on veut un SEO optimal ?
Comment savoir si mon site est affecté par ce problème actuellement ?
Est-ce que ce problème concerne aussi d'autres fichiers comme sitemap.xml ?
🎥 De la même vidéo 7
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 02/03/2023
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.