Declaration officielle
Autres déclarations de cette vidéo 7 ▾
- □ Pourquoi les frameworks JavaScript génèrent-ils des soft 404 sur les sites à fort inventaire ?
- □ Robots.txt bloque-t-il vos ressources critiques sans que vous le sachiez ?
- □ Pourquoi l'historique du robots.txt dans Search Console change-t-il la donne ?
- □ Pourquoi héberger robots.txt sur plusieurs CDN peut-il saboter votre crawl budget ?
- □ Comment Chrome DevTools peut-il révéler les problèmes de rendu que Googlebot rencontre sur vos pages ?
- □ Pourquoi Google pénalise-t-il les sites qui gèrent mal leurs erreurs JavaScript ?
- □ La résoumission manuelle d'URLs via Search Console accélère-t-elle vraiment la réindexation ?
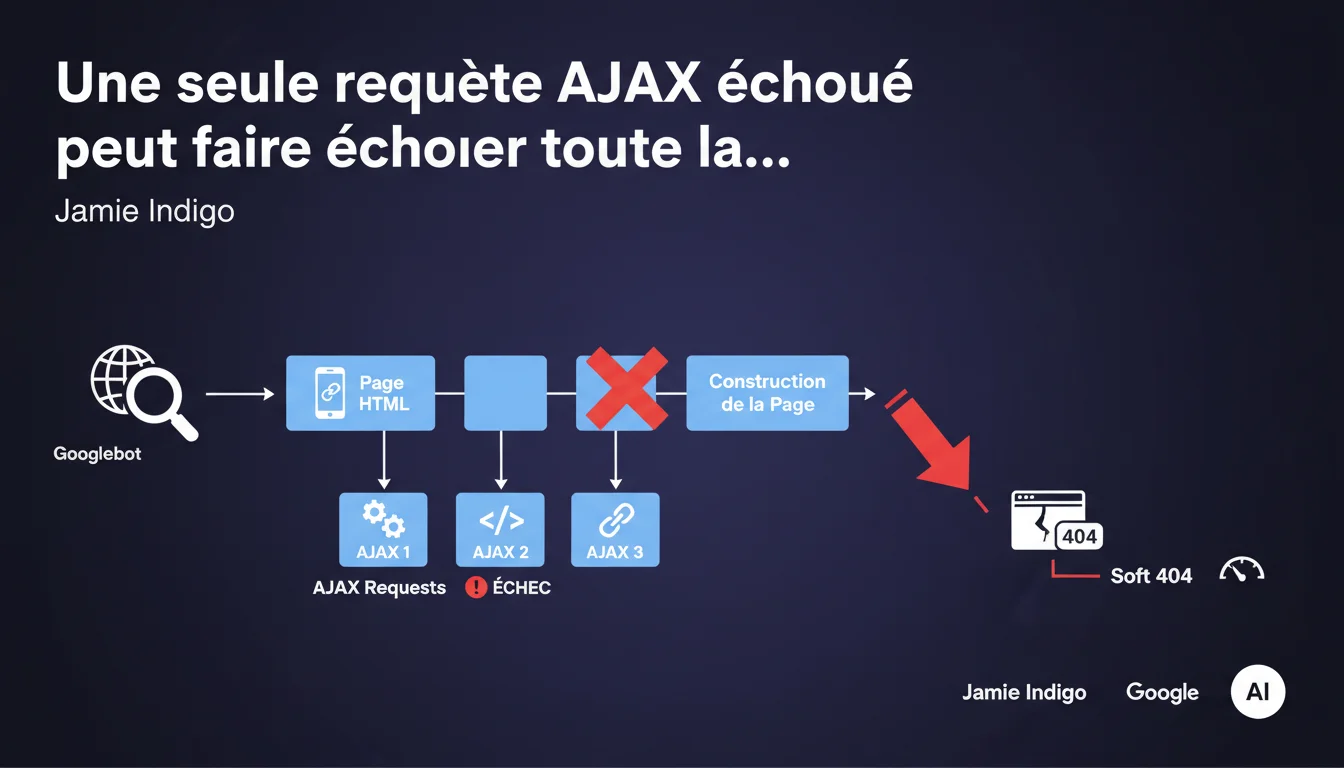
Si votre site utilise plusieurs endpoints JSON/AJAX pour construire une page et qu'une seule requête échoue sans gestion d'erreur, Googlebot peut échouer à rendre la page entière. Résultat : un soft 404 qui évacue la page de l'index. La fragilité des architectures JavaScript front-end n'a jamais été aussi coûteuse.
Ce qu'il faut comprendre
Qu'est-ce qu'une erreur AJAX peut concrètement provoquer côté Googlebot ?
Googlebot exécute le JavaScript de vos pages pour en extraire le contenu final. Si votre page s'appuie sur plusieurs appels AJAX pour assembler le DOM — récupération de produits, filtres, blocs de contenu dynamiques — et qu'une seule de ces requêtes échoue, le moteur peut se retrouver face à un rendu incomplet ou cassé.
Sans gestion d'erreur appropriée, le JavaScript peut planter en silence, laissant une page vide ou dysfonctionnelle. Pour Googlebot, c'est un soft 404 : une URL qui renvoie un code 200 mais ne contient aucun contenu exploitable.
Pourquoi Google parle-t-il spécifiquement de « plusieurs endpoints » ?
Les architectures modernes (React, Vue, Angular) chargent souvent les données par fragments : un call pour le catalogue, un autre pour les avis, un troisième pour les recommandations. Si l'un de ces endpoints timeout, renvoie un 500 ou une réponse malformée, le composant concerné peut bloquer l'ensemble du rendu.
Le problème n'est pas l'AJAX en soi — c'est l'absence de fallback. Si votre code ne prévoit pas de gérer l'échec, il s'arrête. Et Googlebot avec.
Qu'est-ce qu'un soft 404 et en quoi est-ce grave ?
Un soft 404 est une page qui répond 200 OK mais que Google considère comme vide ou inutile. Elle est techniquement accessible, mais ne contient rien d'indexable. Google finit par la retirer de l'index.
Contrairement à un 404 classique, le soft 404 est sournois : côté serveur, tout semble normal. Vous ne voyez rien dans vos logs, mais vos pages disparaissent progressivement de la SERP.
- Une seule requête AJAX qui échoue peut compromettre le rendu complet de la page pour Googlebot
- Le bot n'a pas accès au réseau de la même façon qu'un navigateur réel — timeouts, latences et erreurs réseau sont plus fréquents
- Sans gestion d'erreur, le JavaScript s'arrête et laisse une page vide ou partiellement chargée
- Google interprète cela comme un soft 404 et désindexe la page
- Le phénomène touche particulièrement les Single Page Applications (SPA) mal architecturées
Avis d'un expert SEO
Cette déclaration est-elle cohérente avec les observations terrain ?
Oui, et c'est même un classique. Les architectures JavaScript front-end mal sécurisées sont une source récurrente de problèmes d'indexation. On voit régulièrement des sites avec des pages qui s'affichent parfaitement en navigation humaine, mais qui retournent un DOM vide dans le rendu Googlebot.
Le problème est souvent invisible côté développeur : le navigateur en local masque les erreurs, les CDN cachent les timeouts, et le monitoring ne remonte rien si le code 200 est envoyé. Résultat : des pans entiers de site disparaissent de l'index sans qu'on sache pourquoi.
Quelles nuances faut-il apporter à cette règle ?
Google ne dit pas que toute erreur AJAX entraîne systématiquement un soft 404. Tout dépend de l'impact sur le rendu final. Si une requête secondaire échoue (ex : widget de commentaires) mais que le contenu principal s'affiche, la page peut rester indexable.
Ce qui tue l'indexation, c'est une erreur critique qui bloque le rendu du contenu principal : le titre, le texte, les éléments structurants. Une erreur sur un bloc de recommandations en bas de page ? Googlebot s'en fout. Une erreur qui empêche l'affichage du catalogue produit ? Game over.
[A vérifier] : Google ne précise pas à partir de quel seuil de contenu manquant la page bascule en soft 404. Est-ce 50 % du DOM ? 80 % ? Aucune donnée publique là-dessus.
Dans quels cas cette règle ne s'applique-t-elle pas vraiment ?
Si votre site fait du Server-Side Rendering (SSR) ou du Static Site Generation (SSG), le problème disparaît en grande partie. Le HTML est déjà construit côté serveur, Googlebot n'a pas à exécuter de JavaScript pour accéder au contenu.
Même chose si vous utilisez un hydratation progressive correctement implémentée : le contenu critique est déjà présent dans le DOM initial, les appels AJAX ne font qu'enrichir l'expérience utilisateur sans bloquer l'indexation.
Impact pratique et recommandations
Que faut-il faire concrètement pour éviter ce piège ?
Premier réflexe : implémenter une gestion d'erreur robuste sur tous vos appels AJAX. Chaque fetch() ou XMLHttpRequest doit avoir un .catch() qui gère les échecs sans casser le rendu. Minimum syndical : afficher un message d'erreur ou un fallback plutôt que de laisser le composant dans les limbes.
Ensuite, testez systématiquement vos pages dans des conditions dégradées : simulez des timeouts réseau, des endpoints qui renvoient des 500, des réponses JSON malformées. Votre page doit rester fonctionnelle — ou au minimum afficher du contenu indexable — même si un ou plusieurs appels échouent.
Comment vérifier que Googlebot voit bien le contenu complet ?
Utilisez l'outil d'inspection d'URL de la Search Console pour tester le rendu de vos pages clés. Comparez le HTML brut (onglet « Plus d'infos ») avec le rendu final (onglet « Tester l'URL en direct »). Si le contenu principal est manquant ou incomplet dans le rendu, vous avez un problème.
Mettez en place un monitoring automatisé : des outils comme Puppeteer ou Playwright peuvent simuler Googlebot et vérifier que le DOM final contient bien les éléments critiques (titres, textes, liens internes). Alertez-vous dès qu'une page ne passe plus les critères.
Quelles erreurs éviter absolument ?
- Ne jamais laisser un
fetch()sans.catch()outry/catchen async/await - Éviter les dépendances en cascade : si la requête B dépend de A et que A échoue, B ne doit pas bloquer le rendu
- Ne pas compter uniquement sur les CDN pour la disponibilité des endpoints — prévoir des fallbacks locaux
- Implémenter des timeouts explicites sur les appels AJAX (ex : 5 secondes max) pour éviter que Googlebot attende indéfiniment
- Tester les pages avec l'outil de test du rendu mobile de Google Search Console
- Monitorer les soft 404 dans la Search Console (onglet « Couverture »)
- Vérifier que le contenu critique est présent dans le HTML initial ou chargé de manière synchrone
❓ Questions frequentes
Est-ce que toutes les erreurs AJAX provoquent un soft 404 ?
Le Server-Side Rendering (SSR) résout-il complètement ce problème ?
Comment savoir si mes pages sont touchées par des soft 404 ?
Faut-il préférer le rendu statique (SSG) au JavaScript côté client ?
Est-ce que Googlebot retry les requêtes AJAX qui échouent ?
🎥 De la même vidéo 7
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 02/03/2023
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.