Official statement
Other statements from this video 13 ▾
- 3:25 Pourquoi des rich results valides ne garantissent-ils pas l'affichage dans Job Search ?
- 5:14 Le champ employmentType dans les données structurées JobPosting influence-t-il le matching des requêtes ?
- 7:19 Peut-on agréger les avis d'autres sites dans ses données structurées Rating ?
- 10:28 Faut-il vraiment avoir un contenu strictement identique entre mobile et desktop pour le Mobile-First Indexing ?
- 10:28 Pourquoi masquer du contenu mobile en CSS sabote-t-il votre indexation Mobile-First ?
- 19:07 Le contenu masqué dans des accordéons et des onglets est-il vraiment indexé par Google ?
- 19:07 Google Office Hours : pourquoi votre question SEO ne recevra-t-elle peut-être jamais de réponse ?
- 24:24 Pourquoi le nombre d'URLs dans Web Vitals de Search Console varie-t-il chaque mois ?
- 25:24 Pourquoi vos métriques Page Experience fluctuent-elles alors que vous n'avez rien changé ?
- 31:07 Les redirections géolocalisées par cookies sont-elles considérées comme du cloaking par Google ?
- 31:07 Faut-il vraiment abandonner les redirections géolocalisées au profit du hreflang ?
- 31:07 Les redirections IP bloquent-elles vraiment l'indexation de vos contenus multilingues ?
- 48:33 Les tests A/B posent-ils un risque de cloaking aux yeux de Google ?
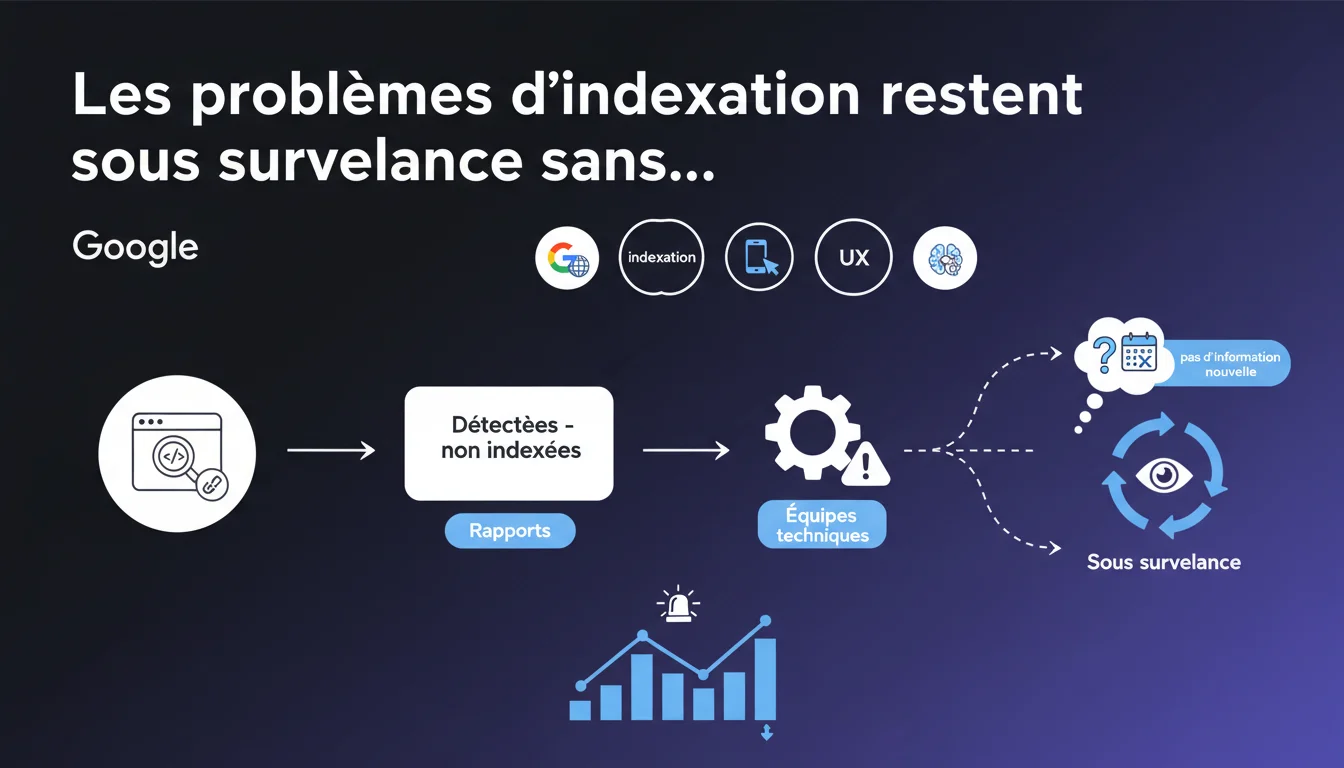
Google continues to receive reports about 'Discovered - not indexed' pages but has no updates to share. The technical teams are aware, but no resolution timeline has been announced. The prolonged silence raises questions about the true scale of the issue.
What you need to understand
What does the status 'Discovered - not indexed' mean?
When Google discovers a URL via crawling or through a sitemap but decides not to add it to its index, it appears with this status in the Search Console. Unlike a technical exclusion (robots.txt, noindex), these pages are technically accessible, but Google chooses not to index them.
This status can apply to a few pages on a site — which is normal — or thousands of URLs, which poses a real visibility issue. The difference between the two cases lies in the scale and recurrence of the phenomenon.
Why does Google mention 'reports forwarded to technical teams'?
This wording suggests that the problem is not isolated. Google acknowledges receiving enough reports for the issue to escalate internally, yet does not admit to a widespread bug or malfunction.
The absence of a timeline or precise diagnosis leaves room for doubt: is it a stricter quality filter, a crawl resource limitation, or a genuine technical problem?
What does the absence of new information conceal?
Either Google really hasn’t identified anything concrete to share, or the team prefers not to communicate on a sensitive topic. This prolonged silence itself becomes a signal for SEOs: you need to learn to live with this status and optimize differently.
- The status 'Discovered - not indexed' can be temporary or permanent depending on the case
- Google does not necessarily view this phenomenon as a bug to be fixed
- Reports are escalated internally without guaranteed prompt resolution
- No official metrics or thresholds are communicated to distinguish a normal case from a real problem
SEO Expert opinion
Is this statement consistent with what we observe in the field?
Yes and no. Many sites are indeed experiencing a surge in the number of pages in this status for several months, without clear explanation. Some sectors are more affected than others — e-commerce, media, multilingual sites — suggesting that Google is applying selective criteria, not a uniform filter.
But the fact that Google keeps saying "we're forwarding" without ever specifying whether it’s expected behavior or a malfunction is frustrating. [To verify]: does the team really have regression data, or do they consider this the new normal balance? Nothing in this statement allows us to conclude.
What nuances should be applied to this status?
Not all 'Discovered - not indexed' pages are equal. An orphan page, without internal links, discovered only via an XML sitemap, does not have the same legitimacy as a well-linked category page, with referring traffic and backlinks.
The problem is that Google lumps everything into the same status. Result: impossible to know if it's an alarm signal or noise. It is necessary to cross-reference with other data — server logs, internal linking, click depth — to diagnose the real cause.
In what cases does this phenomenon really deserve concern?
If the volume of 'Discovered - not indexed' pages suddenly increases without an obvious reason — no migration, no structural change — and it affects URLs with high traffic potential, then yes, it’s worth digging deeper. Especially if these pages were indexed previously and have disappeared without explanation.
Practical impact and recommendations
What concrete actions can be taken with these non-indexed pages?
First, segment the affected URLs: are they strategic or secondary? Did they have organic traffic in the past? Are they properly linked? This analysis helps prioritize actions.
Next, ensure that these pages are not orphaned. If they don’t receive any internal links from regularly crawled pages, Google has no reason to consider them important. Improving internal linking remains the most effective short-term action.
For strategic pages still ignored despite good linking, testing the URL inspection with a request for indexing may unlock some cases — but without guarantee. If this doesn't work, the content may need to be reworked, relevance signals improved, or one must accept that Google deems the page non-priority.
What mistakes should be avoided in the face of this status?
Do not panic and submit all URLs massively via the Indexing API. This API is reserved for urgent content (job offers, livestreams) and its abusive use may lead to suspension of access.
Also, avoid cramming the XML sitemap with thousands of low-quality URLs hoping to force indexing. Google crawls the sitemap, but this does not guarantee anything if the pages do not meet its quality criteria.
How to monitor the evolution of this problem?
Implement a weekly monitoring of the number of 'Discovered - not indexed' pages via the Search Console. Regularly export the lists of URLs to compare and identify patterns — types of pages, depth, themes.
- Segment non-indexed URLs by type (products, categories, articles, technical pages)
- Check the internal linking of these pages and their click depth from the homepage
- Analyze server logs to determine if Googlebot is actually visiting these URLs
- Test URL inspection on a sample of strategic pages
- Improve relevance signals: titles, metas, unique content, internal backlinks
- Avoid massive submissions via the Indexing API or overloading the sitemap
- Track the evolution of the status over time to detect regressions or improvements
❓ Frequently Asked Questions
Le statut 'Détectées - non indexées' signifie-t-il que Google pénalise mon site ?
Combien de temps faut-il attendre avant que Google indexe ces pages ?
Peut-on forcer l'indexation via l'API Indexing ?
Faut-il retirer ces URLs du sitemap XML ?
Ce problème touche-t-il tous les sites de la même manière ?
🎥 From the same video 13
Other SEO insights extracted from this same Google Search Central video · published on 21/12/2021
🎥 Watch the full video on YouTube →
💬 Comments (0)
Be the first to comment.