Official statement
Other statements from this video 5 ▾
- □ Les opinions Google sur le Web3 reflètent-elles vraiment la position du moteur de recherche ?
- □ Google est-il vraiment neutre dans la distribution du contenu web ?
- □ Les contenus en communautés privées sont-ils vraiment invisibles pour Google ?
- □ Les créateurs doivent-ils vraiment contrôler ce qui est indexé par Google ?
- □ Google va-t-il abandonner le crawl traditionnel pour indexer le web social ?
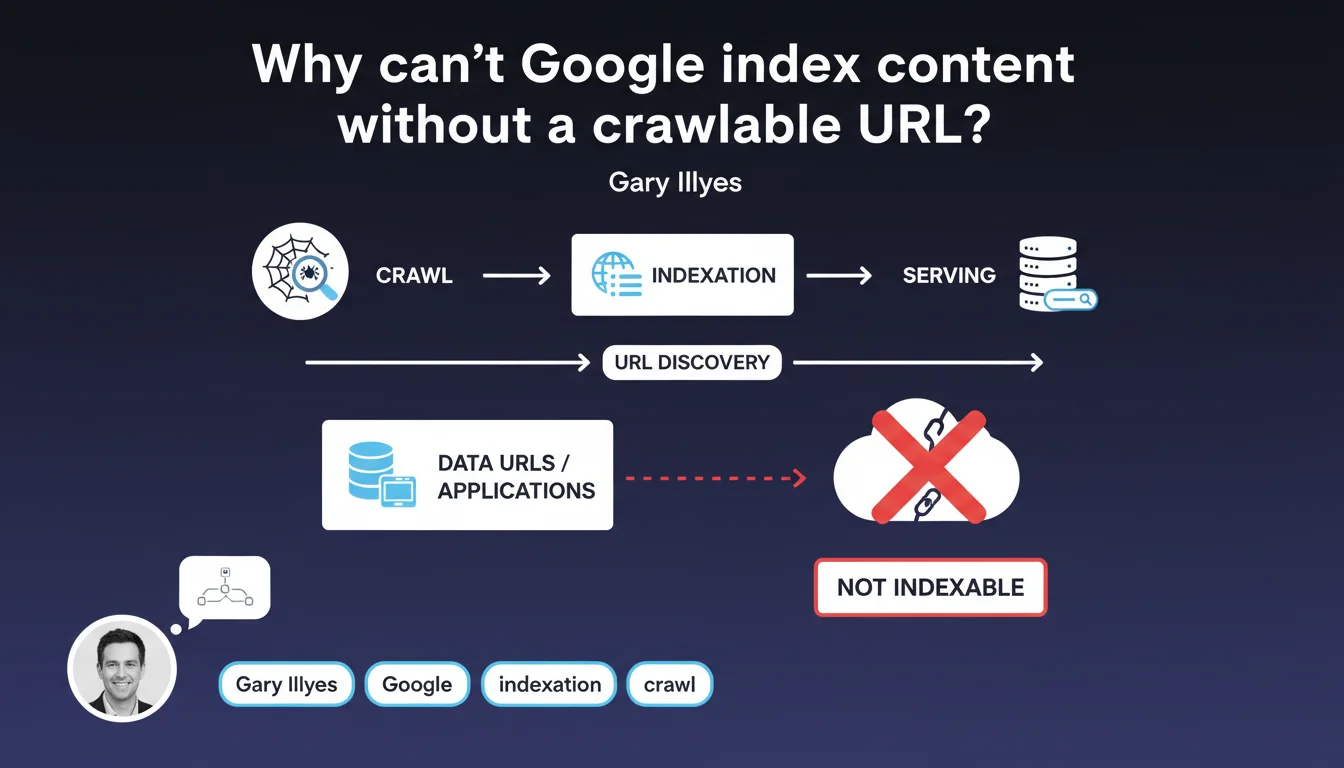
Google's indexing model relies entirely on discovering resources through crawlable URLs. Content that doesn't exist in the form of accessible URLs — such as applications using data URLs or dynamically generated content without a stable URL — cannot be indexed. For SEO professionals, the rule is straightforward: no URL = no indexation.
What you need to understand
What is a crawlable URL in Google's terms?
A crawlable URL is a web address accessible via HTTP/HTTPS protocol that Googlebot can discover, retrieve, and process. This URL must return stable and reproducible content with each request.
In contrast, data URLs — those base64-encoded strings embedded directly in code — or content generated exclusively on the client side without a dedicated URL do not meet this criterion. Google has no mechanism to discover and index them reliably.
Why does this technical limitation still exist?
Google's indexing pipeline (crawl → indexation → serving) was built around the URL model. Each stage depends on the ability to reference a resource by its unique address.
Modifying this architecture to accommodate content without URLs would require rethinking the entire system. And practically speaking? Google has no economic incentive to do so, since the vast majority of the web already operates with URLs.
Which web applications are affected by this restriction?
Single Page Applications (SPA) that are misconfigured are the first to be impacted. If content changes without the URL changing, or if application states don't generate unique URLs, Google only sees a single page.
The same problem exists with applications that store their content in IndexedDB or localStorage without exposing public URLs. The content exists for the user, but remains invisible to search engines.
- Data URLs are not crawlable or indexable
- Client-side generated content without a stable URL flies under Google's radar
- SPAs must implement Server-Side Rendering or hydration to expose crawlable URLs
- The traditional crawl → indexation → serving model remains unchanged and depends entirely on URLs
- No evolution is planned to index content without an accessible web address
SEO Expert opinion
Does this statement really reflect practices observed in the field?
Absolutely. SEO audits consistently confirm that content without a stable URL never appears in Google's index. Cases of SPAs with client-side navigation without unique URLs inevitably end up with only a single page indexed.
What sometimes surprises developers: even content that is technically accessible via JavaScript but without a dedicated URL remains invisible. Google doesn't crawl like a user clicking — it follows links and URLs.
What nuances should be applied to this rule?
The statement is binary, but reality contains some gray areas. For example, Google can index content loaded via Ajax if the URL remains stable and the content appears on first render or after hydration.
The real pitfall lurks in URL fragments (#). Historically ignored by Google, they can now be interpreted in certain contexts (particularly with modern frameworks). But be careful: [To be verified] depending on configurations, results remain unpredictable. It's better to rely on clean URLs.
Another rarely discussed point: content accessible only after authentication. Technically, it has a URL, but Googlebot cannot crawl it. This isn't exactly the same problem, but the effect is identical: indexation is impossible.
In which cases does this constraint become blocking for SEO?
E-commerce sites with dynamic filters are the first to be affected. If applying a filter doesn't change the URL, Google will never see these product combinations. Result: massive loss of long-tail traffic.
User-generated content platforms (forums, social networks) face the same issue. If each discussion, each profile, each application state doesn't have its own unique URL, a huge portion of content remains outside the index.
Practical impact and recommendations
What should you check immediately on your site?
First step: crawl your own site with a tool like Screaming Frog or Sitebulb. If you see content when navigating manually that doesn't appear in the crawl, that's your alarm signal.
Second check: query Google's index with the site: operator. Compare the number of indexed pages with the number of pages you think you have. A significant gap often indicates a URL problem.
How do you fix an architecture that's incompatible with indexation?
For SPAs, the solution involves Server-Side Rendering (SSR) or static rendering (Static Site Generation). Each application state must generate a unique URL that returns complete HTML on the server side.
If full SSR is too costly, progressive hydration represents an acceptable compromise: the server sends the base HTML, and JavaScript then enriches the experience. The essential point: Google must see the content without executing complex JavaScript.
E-commerce filters must generate URLs with clean parameters (query strings or URL segments). Then, properly configure your robots.txt file and canonical tags to avoid duplicate content while allowing indexation of strategic combinations.
What technical errors must you absolutely avoid?
Never rely on the inspection mode in Search Console to validate indexability. This tool sometimes renders content that regular crawling won't see. Test with an external crawler.
Avoid JavaScript redirects that modify the URL without going through the server. Google interprets them poorly, and you risk losing link equity. Always prioritize server-side redirects (301/302).
- Crawl your site with a third-party tool to identify invisible content
- Check Google's index with
site:and compare with the expected number of pages - Implement SSR or static generation for critical SPAs
- Ensure that each application state generates a unique and stable URL
- Configure e-commerce filters to produce crawlable URLs
- Use server redirects (301/302) rather than JavaScript
- Test indexability with an external crawler, not just Search Console
- Document the URL architecture in a technical spec accessible to the entire team
❓ Frequently Asked Questions
Les data URLs peuvent-elles être indexées par Google ?
Une SPA peut-elle être correctement indexée sans Server-Side Rendering ?
Les fragments d'URL (#) sont-ils pris en compte par Google pour l'indexation ?
Comment vérifier si mon contenu dynamique est bien indexable ?
Les contenus accessibles uniquement après connexion peuvent-ils être indexés ?
🎥 From the same video 5
Other SEO insights extracted from this same Google Search Central video · published on 19/05/2022
🎥 Watch the full video on YouTube →
💬 Comments (0)
Be the first to comment.