Official statement
Other statements from this video 10 ▾
- □ Comment Google analyse-t-il vraiment votre contenu lors de l'indexation ?
- □ Google corrige-t-il vraiment vos erreurs HTML pour l'indexation ?
- □ Une balise non supportée dans <head> peut-elle vraiment casser toutes vos métadonnées SEO ?
- □ Comment Google choisit-il quelle version d'une page en double indexer ?
- □ Comment Google choisit-il quelle page indexer parmi vos contenus dupliqués ?
- □ Comment Google regroupe-t-il vraiment les pages au contenu similaire ?
- □ Pourquoi Google accorde-t-il plus de poids à certains signaux SEO qu'à d'autres ?
- □ Comment Google choisit-il LA page canonique dans un cluster de doublons ?
- □ Google sert-il vraiment des versions alternatives de vos pages selon le contexte de recherche ?
- □ Qu'est-ce que Google stocke vraiment dans son index pour une page canonique ?
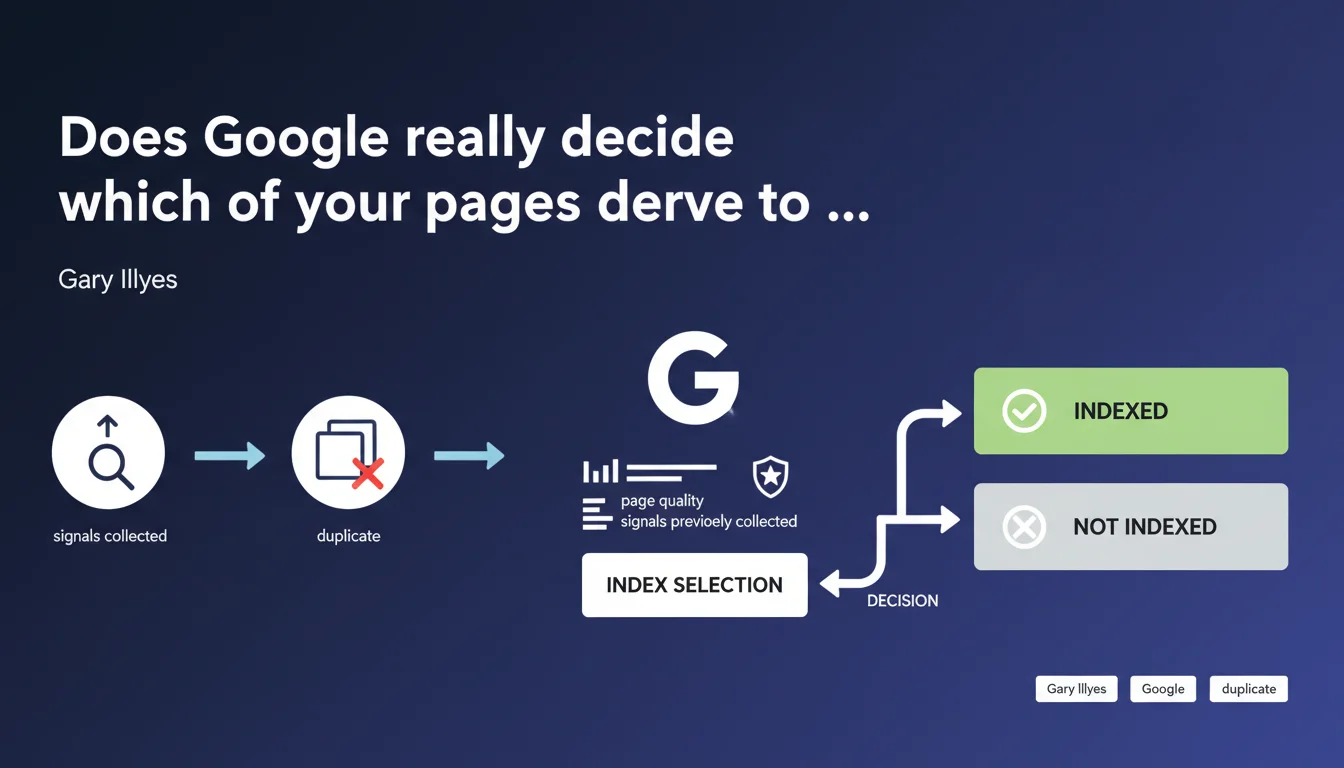
Google doesn't just crawl your pages — it actively evaluates whether they deserve to be indexed. This decision (index selection) relies on perceived quality and signals collected during the crawl. Not enough positive signals or insufficient quality? Your content remains invisible, even if it was explored.
What you need to understand
What exactly is index selection?
Index selection is the stage where Google decides whether a crawled and deduplicated page deserves to enter its main index. It's a distinct phase from the crawl itself: your server may have been visited, your resources explored, but that guarantees nothing.
Google collects quality signals during page processing (content, structure, links, potential user behavior, etc.). If these signals don't reach a certain threshold — deliberately vague — the page is discarded or placed in a secondary, less visible index.
Why is this distinction between crawling and indexing crucial?
Too many practitioners still confuse exploration with indexation. Seeing a page in server logs doesn't mean it will be served in the SERPs. Google can crawl massively without ever promising indexation.
This index selection filter acts as a safeguard against polluting the index with weak, redundant, or useless content. For SEO, this means that optimizing crawl budget alone is no longer enough — you must also maximize the quality signals perceived during processing.
What are the main signals mentioned by Google?
Gary Illyes remains deliberately vague. The collected signals mentioned likely include: semantic relevance, perceived authority via links, freshness, user experience (Core Web Vitals, etc.), content uniqueness, depth of topic coverage.
Page quality is evaluated by multiple criteria, some derived from the Quality Raters Guidelines (E-E-A-T notably), but also by automated algorithms detecting thin, duplicate, or mass-generated content.
- Index selection happens after crawling and deduplication
- It relies on multi-criteria qualitative evaluation
- Being crawled doesn't guarantee being indexed
- Signals collected during processing are decisive
- Google actively filters content deemed weak or redundant
SEO Expert opinion
Is this statement consistent with what we observe in practice?
Absolutely. For several years now, we've seen technically accessible pages, properly crawled, never appear in the index. Google Search Console even explicitly displays statuses like "Crawled, currently not indexed" or "Discovered, currently not indexed".
What Gary Illyes confirms here is that this isn't a bug — it's a feature. Google actively sorts what it indexes based on quality criteria. The problem: what criteria exactly? [To verify] because transparency remains minimal.
What nuances should be added to this statement?
First point: the term "quality" is a catch-all. Google never details the respective weight of each signal — domain authority, content depth, internal links, backlinks, engagement, loading speed. Impossible to know what really tips the scales.
Second nuance: this selection isn't binary. There are probably multiple levels of indexation (main index, secondary index rarely served, limited-time freshness index). A page can be partially indexed or indexed but never ranked competitively.
In what cases does this rule apply less strictly?
Let's be honest: sites with very high authority often escape this filter. Mediocre content on powerful domains stays indexed, while well-crafted pages on young sites struggle to enter the index.
Index selection also seems less aggressive on time-sensitive content (news, events) where Google prioritizes freshness. But again, hard to be certain — Google publishes no figures. [To verify] through large-scale testing.
Practical impact and recommendations
What should you do concretely to maximize your indexation chances?
First, strengthen perceived quality signals: depth of treatment (substantial content, not filler), structured internal linking to distribute authority, Core Web Vitals optimization, clean semantic markup (Schema.org, structured data).
Second, consolidate rather than multiply. Better 50 solid, well-linked pages than 500 weak pages scattered everywhere. Google rewards semantic density and thematic consistency, not volume for volume's sake.
What mistakes should you avoid to not sabotage index selection?
Don't create thin or duplicate content in mass — that's the best way to trigger site-wide devaluation. Also avoid orphaned silos: pages not linked from the rest of the site send signals of low importance.
Another pitfall: neglecting technical user experience. Catastrophic load times, excessive layout shift, or unoptimized mobile degrade the signals Google collects, even if text content is correct.
How can you verify that your pages pass the indexation filter?
Use Google Search Console systematically. Check the "Coverage" or "Pages" section to identify crawled but not indexed URLs. Analyze the reasons given (low quality, duplication, incorrect canonicalization).
Test indexation manually via site:yourdomain.com/exact-url. If the page doesn't appear despite recent crawl, it's probably an index selection issue. Compare with competitors ranking to assess the quality gap.
- Regularly audit "Crawled, not indexed" pages in Search Console
- Consolidate weak or redundant content into pillar pages
- Strengthen internal linking to strategic pages
- Optimize Core Web Vitals and mobile UX
- Enrich content with relevant structured data
- Monitor indexation rate evolution after changes
- Prioritize semantic depth over page volume
❓ Frequently Asked Questions
Pourquoi certaines de mes pages sont crawlées mais jamais indexées ?
L'index selection s'applique-t-elle différemment selon l'autorité du site ?
Quels signaux de qualité Google privilégie-t-il pour l'index selection ?
Peut-on forcer l'indexation d'une page refusée par l'index selection ?
L'index selection peut-elle expliquer une chute brutale d'indexation ?
🎥 From the same video 10
Other SEO insights extracted from this same Google Search Central video · published on 04/04/2024
🎥 Watch the full video on YouTube →
💬 Comments (0)
Be the first to comment.