Official statement
Other statements from this video 11 ▾
- □ Google transcrit-il vraiment l'audio de vos vidéos pour les ranker ?
- □ Google analyse-t-il vraiment le texte affiché dans vos vidéos pour le référencement ?
- □ Google analyse-t-il réellement le contenu visuel des vidéos pour le SEO ?
- □ Pourquoi les données structurées vidéo restent-elles indispensables malgré les progrès de l'IA de Google ?
- □ Pourquoi Google exige-t-il l'URL du fichier vidéo dans les données structurées ?
- □ Pourquoi bloquer vos fichiers vidéo pourrait nuire gravement à votre indexation ?
- □ Pourquoi le cache-busting d'URL vidéo bloque-t-il l'indexation Google ?
- □ Faut-il vraiment utiliser la vérification DNS inversée pour autoriser Googlebot ?
- □ Faut-il toujours privilégier content URL sur embed URL dans les données structurées vidéo ?
- □ Google analyse-t-il vraiment le contenu vidéo ou se fie-t-il uniquement au texte de la page ?
- □ Google indexe-t-il vraiment les vidéos courtes si elles ont une URL crawlable ?
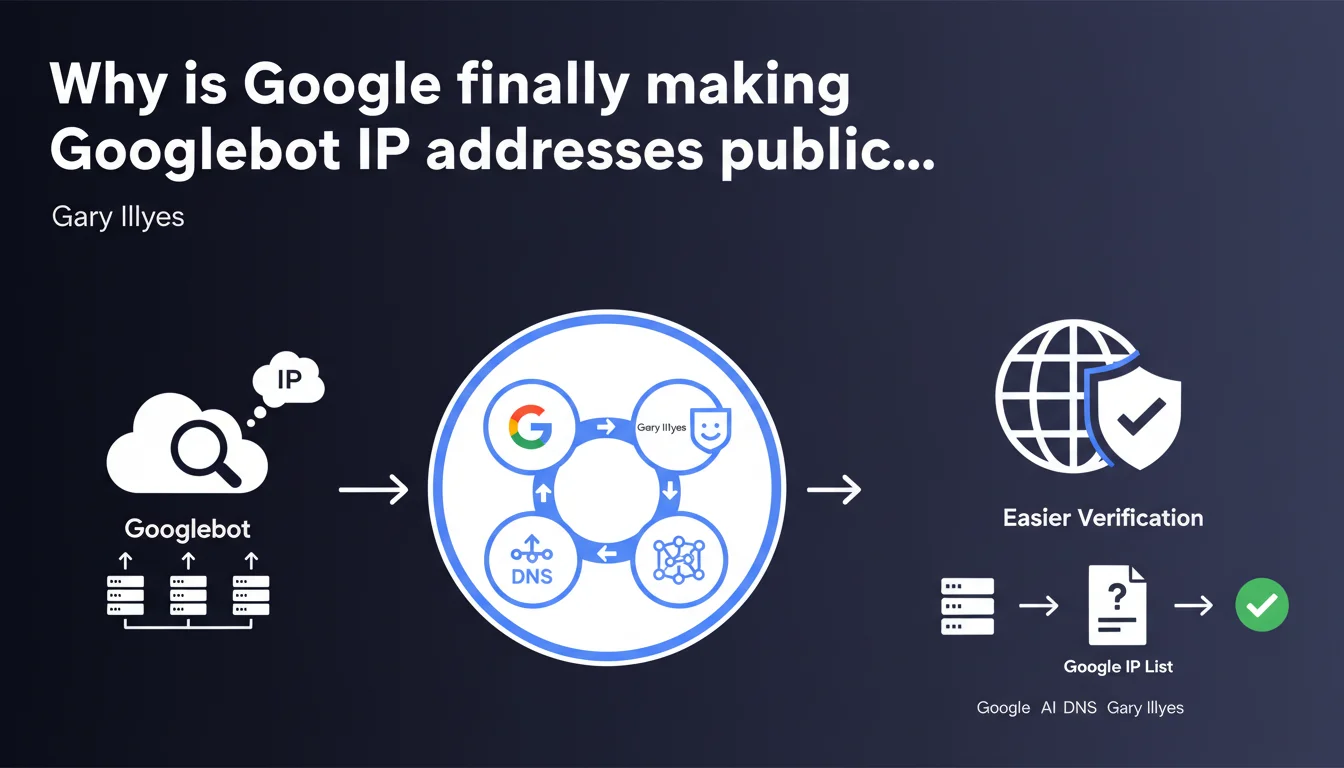
Google has made Googlebot IP addresses public to simplify identification by webmasters. The goal: avoid repeated reverse DNS lookups that burden validation processes. This increased transparency particularly facilitates firewall configuration and security system management.
What you need to understand
How does this IP address publication change the game?
Until now, verifying that a request truly came from Googlebot involved a reverse DNS lookup. In practice: you received a visit from an IP, you had to query DNS servers to confirm it belonged to Google, then re-verify the corresponding IP.
It's heavy. It consumes server resources. And for publishers managing significant crawl volumes or complex infrastructures, it quickly becomes a technical headache. With this public list, verification becomes instantaneous: you compare the incoming IP against a static list.
What are the concrete use cases for an SEO professional?
First use case: firewall configuration and security rule setup. You can now precisely whitelist Googlebot without fear of accidentally blocking the crawler or opening vulnerabilities to malicious bots impersonating Google.
Second use case: server log analysis. Quickly identifying legitimate Googlebot visits in your log files becomes trivial. No more need for complex reverse DNS scripts — a simple grep on the IPs suffices.
Third use case: detecting fake Googlebots. Scrapers regularly disguise themselves as Googlebot in their user-agent. Now, cross-referencing the IP with the official list immediately exposes the deception.
What should you take away from this announcement?
- Google officially publishes the IP address ranges used by Googlebot
- This list eliminates the need for multiple reverse DNS lookups to validate crawler identity
- Publishers can simplify their firewall and security rules
- Server log analysis becomes more straightforward and less resource-intensive
- Detection of fraudulent bots impersonating Googlebot is made easier
SEO Expert opinion
Is this transparency really something new?
Let's be honest: Google has always provided methods to verify Googlebot, particularly through reverse DNS lookup documented for years. What changes is the availability of a static, public list.
For high-traffic infrastructures, it's a real gain. For a typical WordPress site? The impact is marginal. Most hosting providers and CDNs already managed this verification behind the scenes. This announcement primarily benefits technical teams managing custom-built infrastructures or sites with high crawl volumes.
What are the limitations of this approach?
First point: these IP addresses can change. Google makes no commitment to keep them frozen forever. You'll therefore need to implement a regular update mechanism — ideally automated — rather than simply hardcoding the ranges into your configs.
Second point: [To be verified] the update frequency of this list isn't clearly specified by Google. If Google adds new IPs without clear communication, you risk blocking Googlebot despite your precautions. Technical monitoring is essential.
Does this publication change anything about crawl budget?
No. Absolutely not.
Knowing Googlebot's IP addresses doesn't modify the crawl frequency or exploration priorities whatsoever. Crawl budget depends on your site's authority, content freshness, technical structure — not on bot identification methods. This announcement falls under security and system administration, not SEO optimization per se.
Practical impact and recommendations
What should you concretely do with these IP addresses?
If you manage a complex technical infrastructure (multi-server sites, custom CDNs, application firewalls), integrate this list into your whitelisting rules. Automate list retrieval through a script that regularly queries the official Google source.
If you're on shared hosting or a typical WordPress setup, change nothing. Your hosting provider or security plugin likely already handles this. Manual verification would be wasted effort.
What mistakes should you avoid during implementation?
Mistake number one: hardcoding the IPs in your configuration files without an update mechanism. Google can add or remove ranges — if you don't keep up, you'll block Googlebot without realizing it.
Mistake number two: blocking all unlisted IPs without a testing phase. Certain secondary Google bots (AdsBot, Google-InspectionTool) may use other ranges. Analyze your logs for at least two weeks before tightening your rules.
Mistake number three: believing this IP verification replaces user-agent analysis. No. A malicious bot can usurp a Google IP if it passes through certain proxies or compromised infrastructures. The combination of IP plus reverse DNS remains the most reliable method.
How do you verify your site isn't blocking Googlebot by mistake?
- Regularly check Google Search Console, "Crawl Stats" section: any sudden crawl drop may indicate a block
- Analyze your server logs to spot HTTP 403 or 503 codes returned to Google IPs
- Test your firewall rules in a staging environment before production deployment
- Set up an automated alert if Googlebot crawl volume drops more than 30% within 48 hours
- Document all security modifications and keep a fast rollback option available
This IP publication simplifies life for technical teams managing complex infrastructures, but changes nothing about SEO fundamentals. If you encounter persistent crawl difficulties or if configuring your firewalls seems too technical, it may be wise to engage an SEO agency specializing in this area, one that can audit your logs, identify blockages, and implement a whitelisting strategy tailored to your infrastructure.
❓ Frequently Asked Questions
Où trouver la liste officielle des adresses IP de Googlebot ?
Dois-je obligatoirement utiliser cette liste pour autoriser Googlebot ?
Ces adresses IP sont-elles fixes ou peuvent-elles changer ?
Vérifier les IP suffit-il à bloquer les faux Googlebots ?
Cette annonce a-t-elle un impact sur le crawl budget de mon site ?
🎥 From the same video 11
Other SEO insights extracted from this same Google Search Central video · published on 10/03/2022
🎥 Watch the full video on YouTube →
💬 Comments (0)
Be the first to comment.