Official statement
Other statements from this video 8 ▾
- □ Comment le Googlebot crawle-t-il et indexe-t-il réellement votre site web ?
- □ Comment Google construit-il réellement son index et pourquoi ça change tout pour votre SEO ?
- □ Comment Google classe-t-il réellement les résultats pour une requête donnée ?
- □ Google personnalise-t-il vraiment tous les résultats selon l'utilisateur ?
- □ Les résultats organiques Google reposent-ils vraiment uniquement sur la pertinence du contenu ?
- □ Peut-on vraiment payer Google pour améliorer son positionnement organique ?
- □ Google distingue-t-il vraiment ses annonces des résultats organiques de manière efficace ?
- □ Les ressources officielles Google suffisent-elles vraiment à optimiser votre visibilité SEO ?
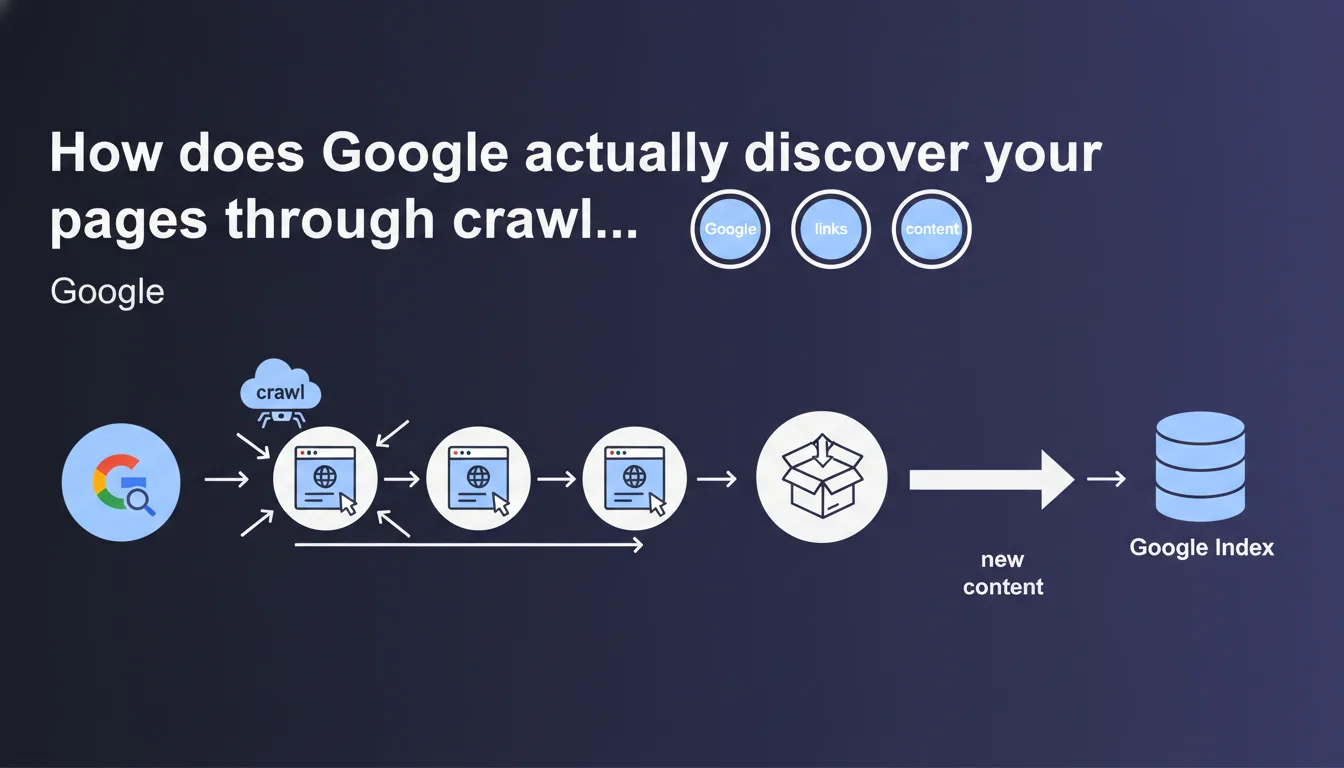
Google discovers new content by following links from page to page — this is crawling. Without links pointing to a page, it remains invisible to the search engine. Internal linking and backlinks are therefore the two pillars of discoverability.
What you need to understand
Why does Google emphasize the central role of links in content discovery?
Crawling is the process by which Googlebot traverses the web by following hyperlinks from one page to another. Each link is a potential gateway to new content. Without a link, a page remains orphaned — technically accessible by direct URL, but invisible to the search engine.
This statement reminds us of a fundamental truth: link structure determines discoverability. A page buried 10 clicks away from the home page, without external backlinks, will be crawled late, if at all.
What does this concretely imply for indexing a website?
If Google cannot find your pages, it cannot index them. Internal linking therefore becomes a strategic lever for prioritizing the crawl of important content. A page accessible in 2 clicks from the home page will be discovered faster than a page buried in an obscure subcategory.
Backlinks play a similar role: they signal to Google that a page deserves to be crawled, especially if the link comes from a site already in the index and regularly visited.
Does Google use other methods to discover content?
Yes, but links remain the primary channel. Google can also discover pages via XML sitemaps, RSS feeds, or manual submissions through Search Console. But these methods do not replace links — they complement them.
The sitemap helps mainly for recent or poorly linked pages. But if a URL has no internal or external links, even a sitemap does not guarantee rapid crawling.
- Links are the primary discovery vector — without them, a page remains invisible
- Internal linking structures crawl priority and accelerates indexation of strategic pages
- Backlinks signal relevance and trigger more frequent crawling of linked pages
- XML sitemaps are a complement, not a substitute for linking and backlinks
SEO Expert opinion
Is this statement consistent with real-world observations?
Yes, absolutely. Crawl audits confirm it: orphaned or poorly linked pages are rarely indexed quickly, if at all. Server logs show that Googlebot meticulously follows internal and external links to discover new URLs.
That said, Google omits an important nuance: not all links are equal. A link in the footer shared across 10,000 pages will have less impact than an editorial contextual link from a strategic page. [To verify]: Google never specifies how it weights links in its crawl algorithm — we only know there is a difference.
What common errors result from a misunderstanding of this mechanism?
Many sites rely solely on their XML sitemap to get new pages indexed. Result: significant delays, or even complete absence of indexation. The sitemap does not trigger priority crawling — it simply informs Google that a URL exists.
Another classic mistake: creating pages with no internal links thinking they will be discovered magically. It doesn't work. A page must be linked, ideally from several strategic locations on the site.
In what cases does this rule not apply completely?
For very large sites — e-commerce with millions of products, media with high volume — crawl budget becomes a limiting factor. Google does not crawl everything, even if everything is well linked. You must then prioritize linking of high-value pages and block crawling of unnecessary pages (filters, parameters, etc.).
Practical impact and recommendations
What should you concretely do to optimize the discovery of your content?
Structure your internal linking hierarchically: strategic pages (conversions, pillar content) should be accessible in 2-3 clicks maximum from the home page. Use contextual links in your editorial content to strengthen the discoverability of important pages.
Regularly audit your orphaned pages — those with no internal links. Fix by adding links from already well-crawled pages. Prioritize quality backlinks to accelerate crawling of new sections or strategic content.
What mistakes should you absolutely avoid?
Don't rely solely on your XML sitemap. It does not replace links. Also avoid creating navigation structures that are too deep — each additional click delays discovery and dilutes link equity.
Watch out for links blocked by robots.txt or poorly managed JavaScript: Googlebot cannot follow what it cannot see. Verify that your critical links are in standard HTML and crawlable.
How can you verify that your site is properly structured for crawling?
- Verify in Search Console that strategic pages are indexed quickly after publication
- Analyze your server logs to identify pages never or rarely crawled
- Use Screaming Frog to detect orphaned pages and fix them
- Audit crawl depth: no important page should be more than 3 clicks from the home page
- Monitor incoming backlinks via Ahrefs, Majestic or Search Console — they accelerate crawling
- Submit a clean, up-to-date XML sitemap, but don't rely solely on it
❓ Frequently Asked Questions
Google peut-il indexer une page sans lien pointant vers elle ?
Le sitemap XML suffit-il à faire indexer mes pages rapidement ?
Tous les liens internes ont-ils le même poids pour le crawl ?
Les backlinks accélèrent-ils vraiment la découverte de nouvelles pages ?
Comment identifier les pages orphelines sur mon site ?
🎥 From the same video 8
Other SEO insights extracted from this same Google Search Central video · published on 24/02/2022
🎥 Watch the full video on YouTube →
💬 Comments (0)
Be the first to comment.